 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTessel: Boosting Distributed Execution of Large DNN Models via Flexible Schedule Search
Nov 26, 2023Increasingly complex and diverse deep neural network (DNN) models necessitate distributing the execution across multiple devices for training and inference tasks, and also require carefully planned schedules for performance. However, existing practices often rely on predefined schedules that may not fully exploit the benefits of emerging diverse model-aware operator placement strategies. Handcrafting high-efficiency schedules can be challenging due to the large and varying schedule space. This paper presents Tessel, an automated system that searches for efficient schedules for distributed DNN training and inference for diverse operator placement strategies. To reduce search costs, Tessel leverages the insight that the most efficient schedules often exhibit repetitive pattern (repetend) across different data inputs. This leads to a two-phase approach: repetend construction and schedule completion. By exploring schedules for various operator placement strategies, Tessel significantly improves both training and inference performance. Experiments with representative DNN models demonstrate that Tessel achieves up to 5.5x training performance speedup and up to 38% inference latency reduction.
Adam Accumulation to Reduce Memory Footprints of both Activations and Gradients for Large-scale DNN Training
May 31, 2023Running out of GPU memory has become a main bottleneck for large-scale DNN training. How to reduce the memory footprint during training has received intensive research attention. We find that previous gradient accumulation reduces activation memory but fails to be compatible with gradient memory reduction due to a contradiction between preserving gradients and releasing gradients. To address this issue, we propose a novel optimizer accumulation method for Adam, named Adam Accumulation (AdamA), which enables reducing both activation and gradient memory. Specifically, AdamA directly integrates gradients into optimizer states and accumulates optimizer states over micro-batches, so that gradients can be released immediately after use. We mathematically and experimentally demonstrate AdamA yields the same convergence properties as Adam. Evaluated on transformer-based models, AdamA achieves up to 23% memory reduction compared to gradient accumulation with less than 2% degradation in training throughput. Notably, AdamA can work together with memory reduction methods for optimizer states to fit 1.26x~3.14x larger models over PyTorch and DeepSpeed baseline on GPUs with different memory capacities.
SuperScaler: Supporting Flexible DNN Parallelization via a Unified Abstraction
Jan 21, 2023



With the growing model size, deep neural networks (DNN) are increasingly trained over massive GPU accelerators, which demands a proper parallelization plan that transforms a DNN model into fine-grained tasks and then schedules them to GPUs for execution. Due to the large search space, the contemporary parallelization plan generators often rely on empirical rules that couple transformation and scheduling, and fall short in exploring more flexible schedules that yield better memory usage and compute efficiency. This tension can be exacerbated by the emerging models with increasing complexity in their structure and model size. SuperScaler is a system that facilitates the design and generation of highly flexible parallelization plans. It formulates the plan design and generation into three sequential phases explicitly: model transformation, space-time scheduling, and data dependency preserving. Such a principled approach decouples multiple seemingly intertwined factors and enables the composition of highly flexible parallelization plans. As a result, SuperScaler can not only generate empirical parallelization plans, but also construct new plans that achieve up to 3.5X speedup compared to state-of-the-art solutions like DeepSpeed, Megatron and Alpa, for emerging DNN models like Swin-Transformer and AlphaFold2, as well as well-optimized models like GPT-3.
Dense-to-Sparse Gate for Mixture-of-Experts
Dec 29, 2021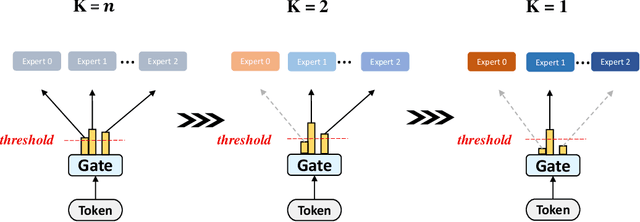

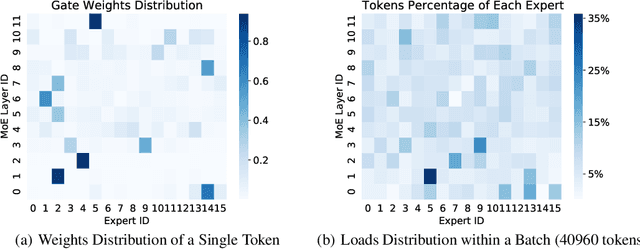
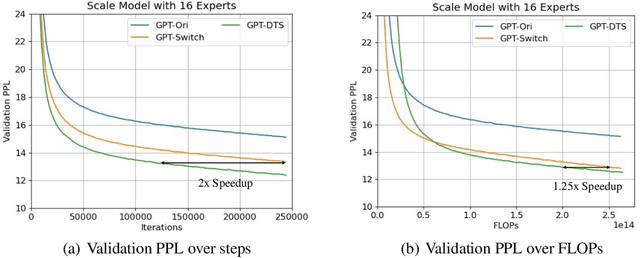
Mixture-of-experts (MoE) is becoming popular due to its success in improving the model quality, especially in Transformers. By routing tokens with a sparse gate to a few experts that each only contains part of the full model, MoE keeps the model size unchanged and significantly reduces per-token computation, which effectively scales neural networks. However, we found that the current approach of jointly training experts and the sparse gate introduces a negative impact on model accuracy, diminishing the efficiency of expensive large-scale model training. In this work, we proposed Dense-To-Sparse gate (DTS-Gate) for MoE training. Specifically, instead of using a permanent sparse gate, DTS-Gate begins as a dense gate that routes tokens to all experts, then gradually and adaptively becomes sparser while routes to fewer experts. MoE with DTS-Gate naturally decouples the training of experts and the sparse gate by training all experts at first and then learning the sparse gate. Experiments show that compared with the state-of-the-art Switch-Gate in GPT-MoE(1.5B) model with OpenWebText dataset(40GB), DTS-Gate can obtain 2.0x speed-up to reach the same validation perplexity, as well as higher FLOPs-efficiency of a 1.42x speed-up.
CoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning
May 13, 2021
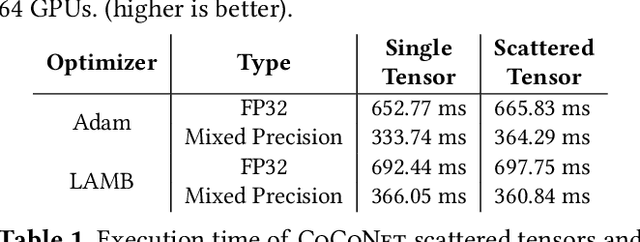

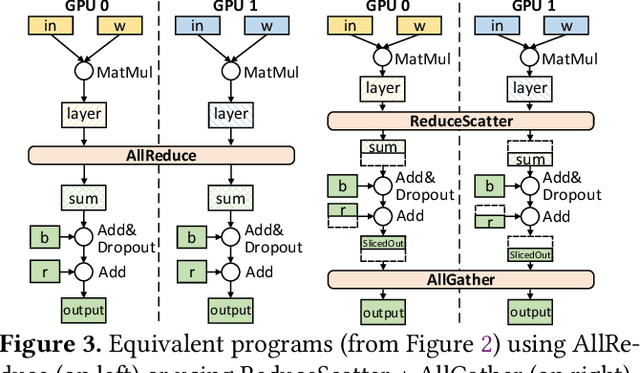
Modern deep learning workloads run on distributed hardware and are difficult to optimize -- data, model, and pipeline parallelism require a developer to thoughtfully restructure their workload around optimized computation and communication kernels in libraries such as cuBLAS and NCCL. The logical separation between computation and communication leaves performance on the table with missed optimization opportunities across abstraction boundaries. To explore these opportunities, this paper presents CoCoNet, which consists of a compute language to express programs with both computation and communication, a scheduling language to apply transformations on such programs, and a compiler to generate high performance kernels. Providing both computation and communication as first class constructs enables new optimizations, such as overlapping or fusion of communication with computation. CoCoNet allowed us to optimize several data, model and pipeline parallel workloads in existing deep learning systems with very few lines of code. We show significant improvements after integrating novel CoCoNet generated kernels.
CrossoverScheduler: Overlapping Multiple Distributed Training Applications in a Crossover Manner
Mar 14, 2021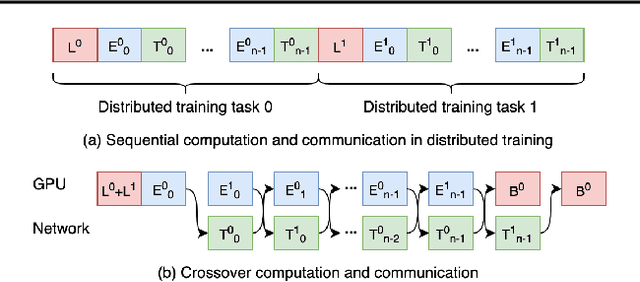
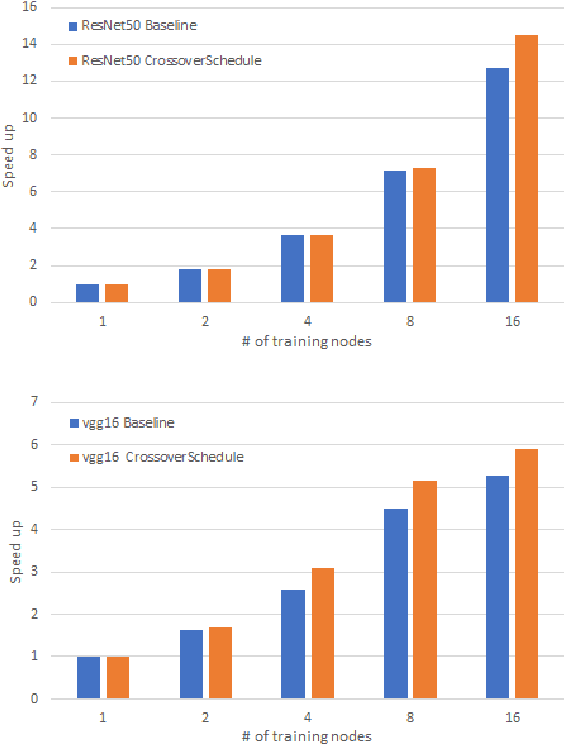
Distributed deep learning workloads include throughput-intensive training tasks on the GPU clusters, where the Distributed Stochastic Gradient Descent (SGD) incurs significant communication delays after backward propagation, forces workers to wait for the gradient synchronization via a centralized parameter server or directly in decentralized workers. We present CrossoverScheduler, an algorithm that enables communication cycles of a distributed training application to be filled by other applications through pipelining communication and computation. With CrossoverScheduler, the running performance of distributed training can be significantly improved without sacrificing convergence rate and network accuracy. We achieve so by introducing Crossover Synchronization which allows multiple distributed deep learning applications to time-share the same GPU alternately. The prototype of CrossoverScheduler is built and integrated with Horovod. Experiments on a variety of distributed tasks show that CrossoverScheduler achieves 20% \times speedup for image classification tasks on ImageNet dataset.
Architectural Implications of Graph Neural Networks
Sep 02, 2020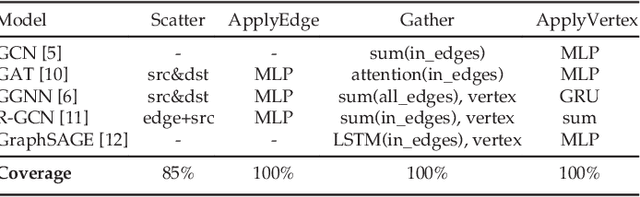
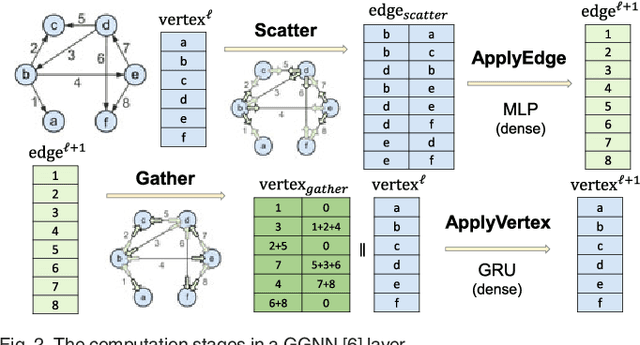
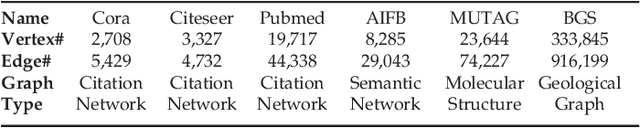
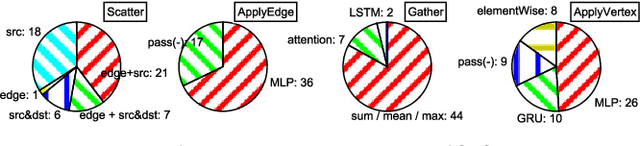
Graph neural networks (GNN) represent an emerging line of deep learning models that operate on graph structures. It is becoming more and more popular due to its high accuracy achieved in many graph-related tasks. However, GNN is not as well understood in the system and architecture community as its counterparts such as multi-layer perceptrons and convolutional neural networks. This work tries to introduce the GNN to our community. In contrast to prior work that only presents characterizations of GCNs, our work covers a large portion of the varieties for GNN workloads based on a general GNN description framework. By constructing the models on top of two widely-used libraries, we characterize the GNN computation at inference stage concerning general-purpose and application-specific architectures and hope our work can foster more system and architecture research for GNNs.
* 4 pages, published in IEEE Computer Architecture Letters (CAL) 2020
Towards Efficient Large-Scale Graph Neural Network Computing
Oct 19, 2018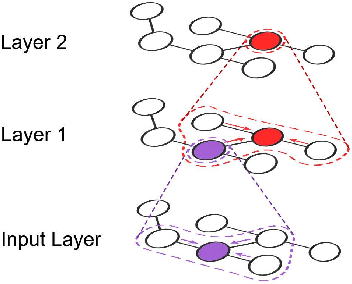
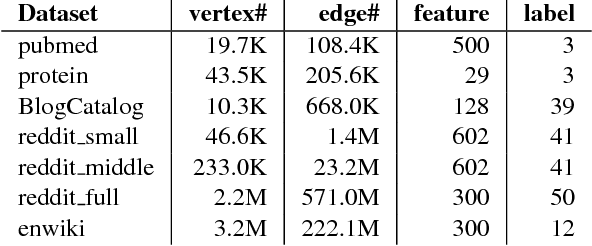

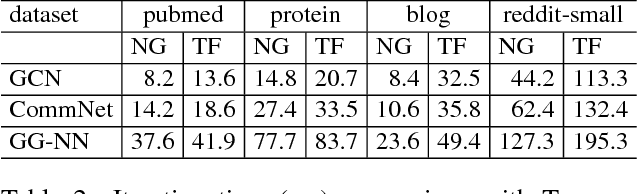
Recent deep learning models have moved beyond low-dimensional regular grids such as image, video, and speech, to high-dimensional graph-structured data, such as social networks, brain connections, and knowledge graphs. This evolution has led to large graph-based irregular and sparse models that go beyond what existing deep learning frameworks are designed for. Further, these models are not easily amenable to efficient, at scale, acceleration on parallel hardwares (e.g. GPUs). We introduce NGra, the first parallel processing framework for graph-based deep neural networks (GNNs). NGra presents a new SAGA-NN model for expressing deep neural networks as vertex programs with each layer in well-defined (Scatter, ApplyEdge, Gather, ApplyVertex) graph operation stages. This model not only allows GNNs to be expressed intuitively, but also facilitates the mapping to an efficient dataflow representation. NGra addresses the scalability challenge transparently through automatic graph partitioning and chunk-based stream processing out of GPU core or over multiple GPUs, which carefully considers data locality, data movement, and overlapping of parallel processing and data movement. NGra further achieves efficiency through highly optimized Scatter/Gather operators on GPUs despite its sparsity. Our evaluation shows that NGra scales to large real graphs that none of the existing frameworks can handle directly, while achieving up to about 4 times speedup even at small scales over the multiple-baseline design on TensorFlow.
RPC Considered Harmful: Fast Distributed Deep Learning on RDMA
May 22, 2018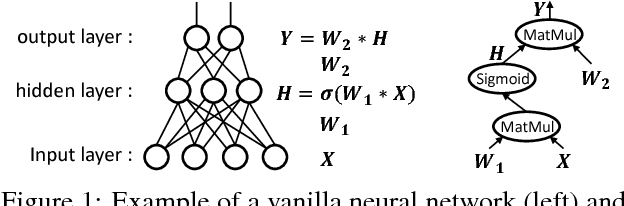
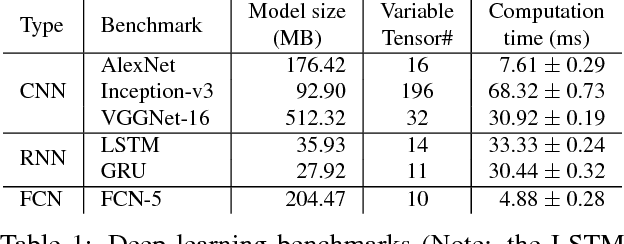
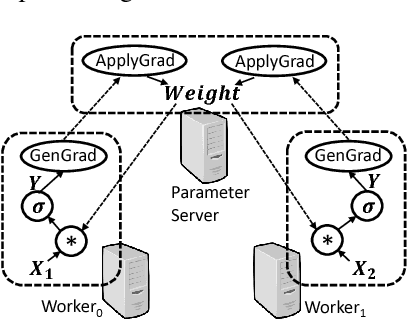
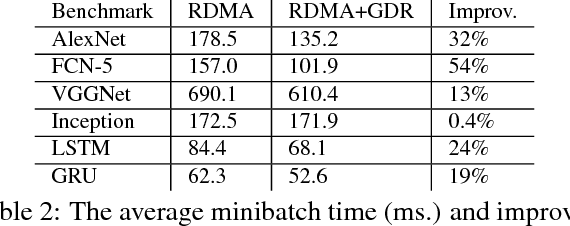
Deep learning emerges as an important new resource-intensive workload and has been successfully applied in computer vision, speech, natural language processing, and so on. Distributed deep learning is becoming a necessity to cope with growing data and model sizes. Its computation is typically characterized by a simple tensor data abstraction to model multi-dimensional matrices, a data-flow graph to model computation, and iterative executions with relatively frequent synchronizations, thereby making it substantially different from Map/Reduce style distributed big data computation. RPC, commonly used as the communication primitive, has been adopted by popular deep learning frameworks such as TensorFlow, which uses gRPC. We show that RPC is sub-optimal for distributed deep learning computation, especially on an RDMA-capable network. The tensor abstraction and data-flow graph, coupled with an RDMA network, offers the opportunity to reduce the unnecessary overhead (e.g., memory copy) without sacrificing programmability and generality. In particular, from a data access point of view, a remote machine is abstracted just as a "device" on an RDMA channel, with a simple memory interface for allocating, reading, and writing memory regions. Our graph analyzer looks at both the data flow graph and the tensors to optimize memory allocation and remote data access using this interface. The result is up to 25 times speedup in representative deep learning benchmarks against the standard gRPC in TensorFlow and up to 169% improvement even against an RPC implementation optimized for RDMA, leading to faster convergence in the training process.