 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Concept Reasoning Networks
Aug 26, 2020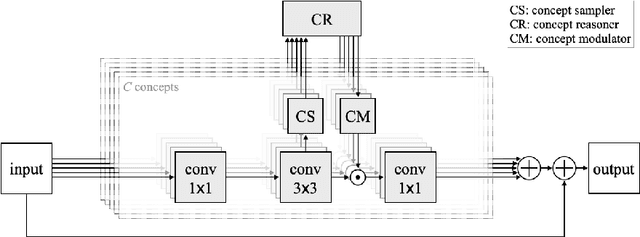
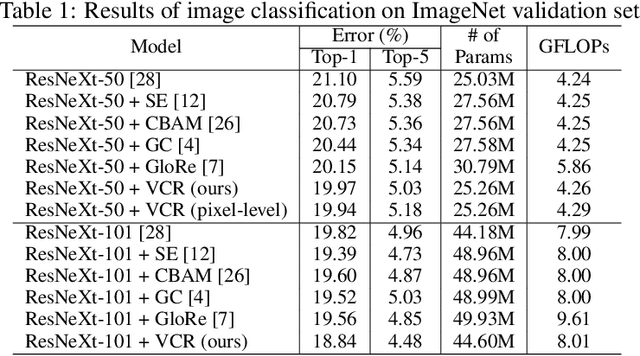
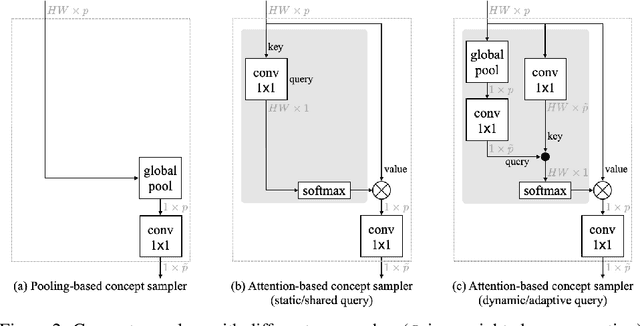
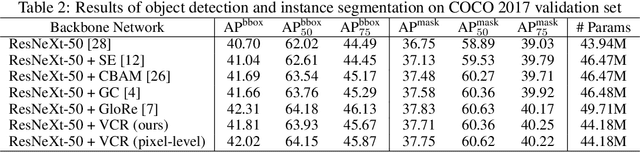
A split-transform-merge strategy has been broadly used as an architectural constraint in convolutional neural networks for visual recognition tasks. It approximates sparsely connected networks by explicitly defining multiple branches to simultaneously learn representations with different visual concepts or properties. Dependencies or interactions between these representations are typically defined by dense and local operations, however, without any adaptiveness or high-level reasoning. In this work, we propose to exploit this strategy and combine it with our Visual Concept Reasoning Networks (VCRNet) to enable reasoning between high-level visual concepts. We associate each branch with a visual concept and derive a compact concept state by selecting a few local descriptors through an attention module. These concept states are then updated by graph-based interaction and used to adaptively modulate the local descriptors. We describe our proposed model by split-transform-attend-interact-modulate-merge stages, which are implemented by opting for a highly modularized architecture. Extensive experiments on visual recognition tasks such as image classification, semantic segmentation, object detection, scene recognition, and action recognition show that our proposed model, VCRNet, consistently improves the performance by increasing the number of parameters by less than 1%.
Deriving Differential Target Propagation from Iterating Approximate Inverses
Aug 17, 2020We show that a particular form of target propagation, i.e., relying on learned inverses of each layer, which is differential, i.e., where the target is a small perturbation of the forward propagation, gives rise to an update rule which corresponds to an approximate Gauss-Newton gradient-based optimization, without requiring the manipulation or inversion of large matrices. What is interesting is that this is more biologically plausible than back-propagation yet may turn out to implicitly provide a stronger optimization procedure. Extending difference target propagation, we consider several iterative calculations based on local auto-encoders at each layer in order to achieve more precise inversions for more accurate target propagation and we show that these iterative procedures converge exponentially fast if the auto-encoding function minus the identity function has a Lipschitz constant smaller than one, i.e., the auto-encoder is coarsely succeeding at performing an inversion. We also propose a way to normalize the changes at each layer to take into account the relative influence of each layer on the output, so that larger weight changes are done on more influential layers, like would happen in ordinary back-propagation with gradient descent.
Mastering Rate based Curriculum Learning
Aug 14, 2020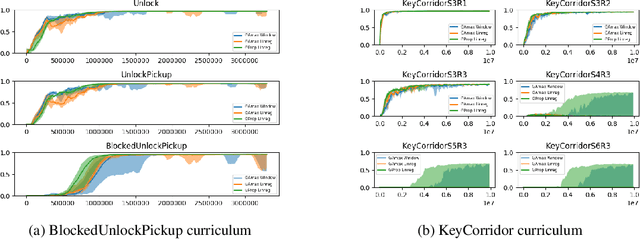
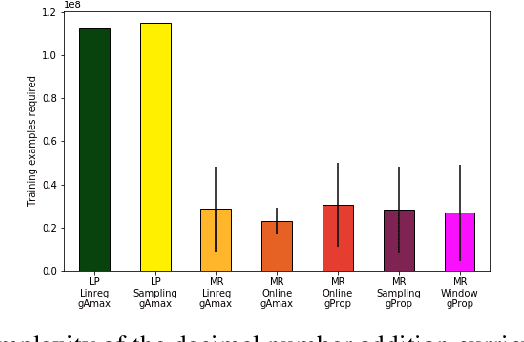
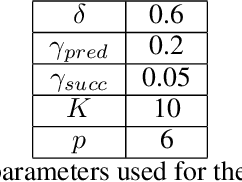
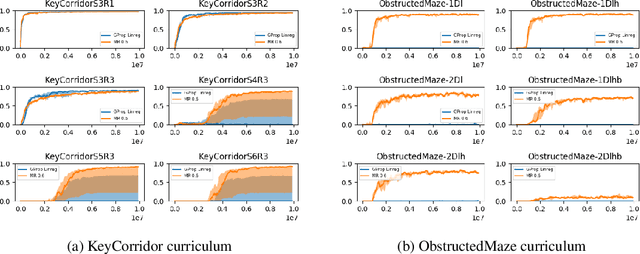
Recent automatic curriculum learning algorithms, and in particular Teacher-Student algorithms, rely on the notion of learning progress, making the assumption that the good next tasks are the ones on which the learner is making the fastest progress or digress. In this work, we first propose a simpler and improved version of these algorithms. We then argue that the notion of learning progress itself has several shortcomings that lead to a low sample efficiency for the learner. We finally propose a new algorithm, based on the notion of mastering rate, that significantly outperforms learning progress-based algorithms.
BabyAI 1.1
Jul 24, 2020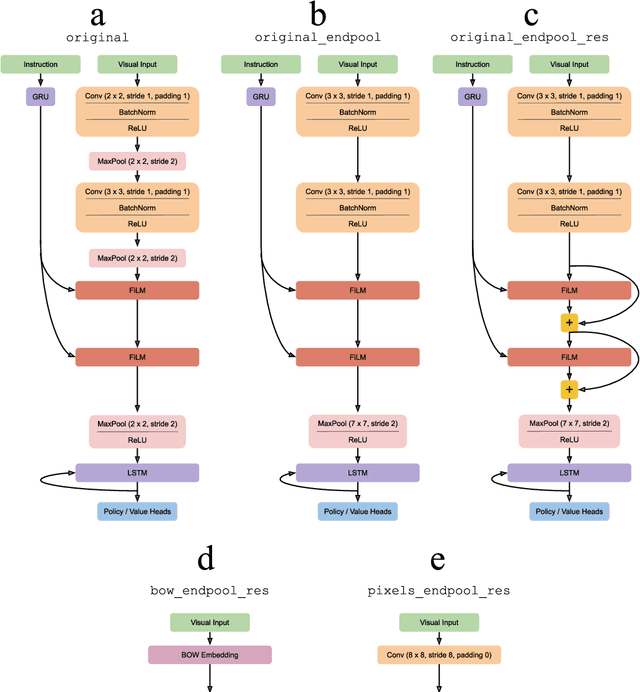
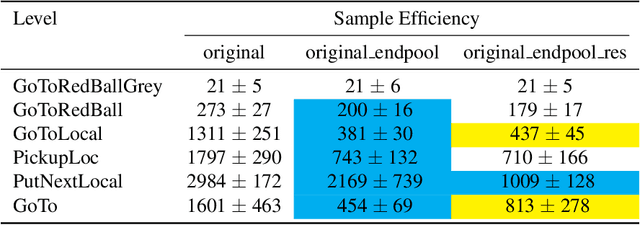

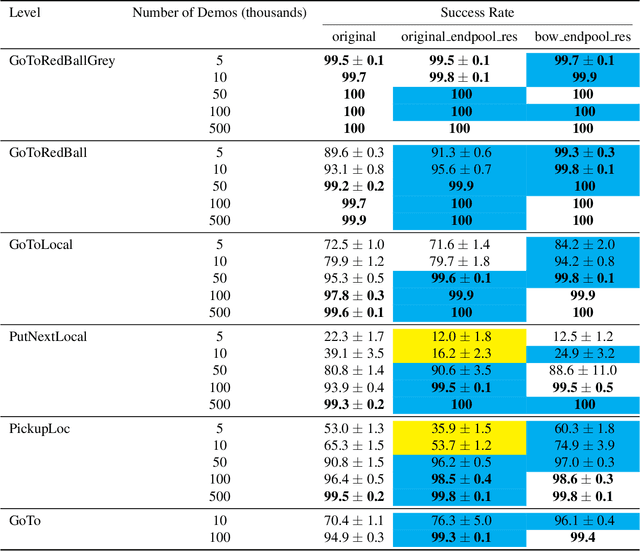
The BabyAI platform is designed to measure the sample efficiency of training an agent to follow grounded-language instructions. BabyAI 1.0 presents baseline results of an agent trained by deep imitation or reinforcement learning. BabyAI 1.1 improves the agent's architecture in three minor ways. This increases reinforcement learning sample efficiency by up to 3 times and improves imitation learning performance on the hardest level from 77 % to 90.4 %. We hope that these improvements increase the computational efficiency of BabyAI experiments and help users design better agents.
Revisiting Fundamentals of Experience Replay
Jul 13, 2020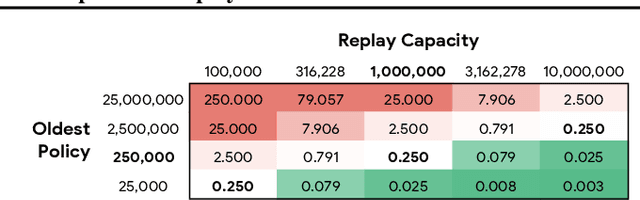

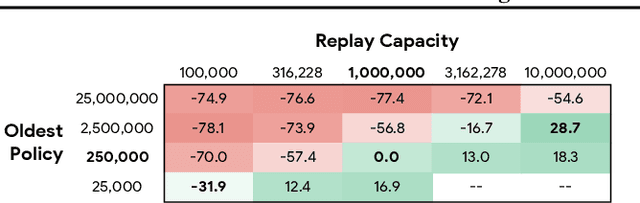
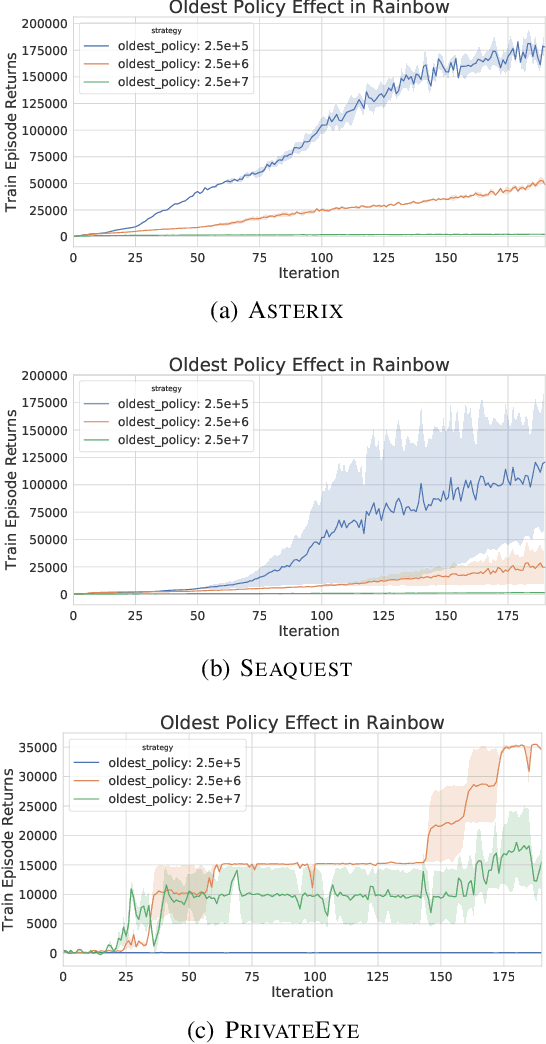
Experience replay is central to off-policy algorithms in deep reinforcement learning (RL), but there remain significant gaps in our understanding. We therefore present a systematic and extensive analysis of experience replay in Q-learning methods, focusing on two fundamental properties: the replay capacity and the ratio of learning updates to experience collected (replay ratio). Our additive and ablative studies upend conventional wisdom around experience replay -- greater capacity is found to substantially increase the performance of certain algorithms, while leaving others unaffected. Counterintuitively we show that theoretically ungrounded, uncorrected n-step returns are uniquely beneficial while other techniques confer limited benefit for sifting through larger memory. Separately, by directly controlling the replay ratio we contextualize previous observations in the literature and empirically measure its importance across a variety of deep RL algorithms. Finally, we conclude by testing a set of hypotheses on the nature of these performance benefits.
S2RMs: Spatially Structured Recurrent Modules
Jul 13, 2020



Capturing the structure of a data-generating process by means of appropriate inductive biases can help in learning models that generalize well and are robust to changes in the input distribution. While methods that harness spatial and temporal structures find broad application, recent work has demonstrated the potential of models that leverage sparse and modular structure using an ensemble of sparingly interacting modules. In this work, we take a step towards dynamic models that are capable of simultaneously exploiting both modular and spatiotemporal structures. We accomplish this by abstracting the modeled dynamical system as a collection of autonomous but sparsely interacting sub-systems. The sub-systems interact according to a topology that is learned, but also informed by the spatial structure of the underlying real-world system. This results in a class of models that are well suited for modeling the dynamics of systems that only offer local views into their state, along with corresponding spatial locations of those views. On the tasks of video prediction from cropped frames and multi-agent world modeling from partial observations in the challenging Starcraft2 domain, we find our models to be more robust to the number of available views and better capable of generalization to novel tasks without additional training, even when compared against strong baselines that perform equally well or better on the training distribution.
Rethinking Distributional Matching Based Domain Adaptation
Jul 03, 2020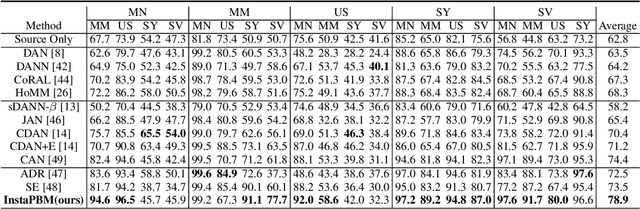
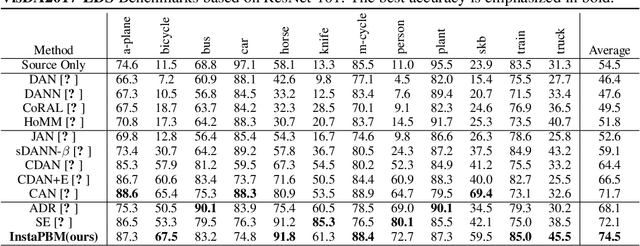
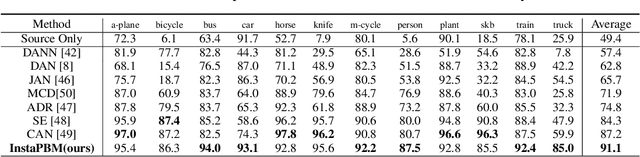
Domain adaptation (DA) is a technique that transfers predictive models trained on a labeled source domain to an unlabeled target domain, with the core difficulty of resolving distributional shift between domains. Currently, most popular DA algorithms are based on distributional matching (DM). However in practice, realistic domain shifts (RDS) may violate their basic assumptions and as a result these methods will fail. In this paper, in order to devise robust DA algorithms, we first systematically analyze the limitations of DM based methods, and then build new benchmarks with more realistic domain shifts to evaluate the well-accepted DM methods. We further propose InstaPBM, a novel Instance-based Predictive Behavior Matching method for robust DA. Extensive experiments on both conventional and RDS benchmarks demonstrate both the limitations of DM methods and the efficacy of InstaPBM: Compared with the best baselines, InstaPBM improves the classification accuracy respectively by $4.5\%$, $3.9\%$ on Digits5, VisDA2017, and $2.2\%$, $2.9\%$, $3.6\%$ on DomainNet-LDS, DomainNet-ILDS, ID-TwO. We hope our intuitive yet effective method will serve as a useful new direction and increase the robustness of DA in real scenarios. Code will be available at anonymous link: https://github.com/pikachusocute/InstaPBM-RobustDA.
Object Files and Schemata: Factorizing Declarative and Procedural Knowledge in Dynamical Systems
Jun 30, 2020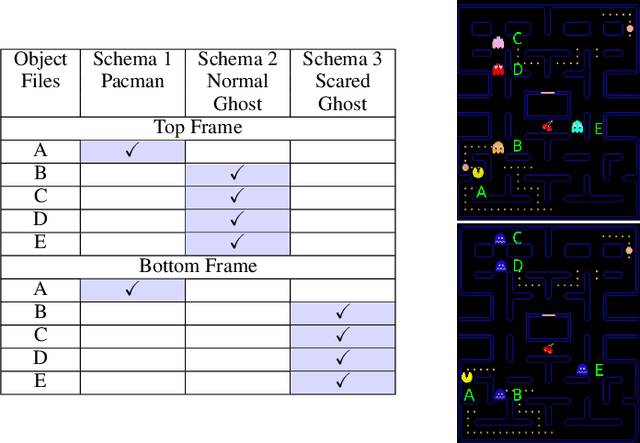
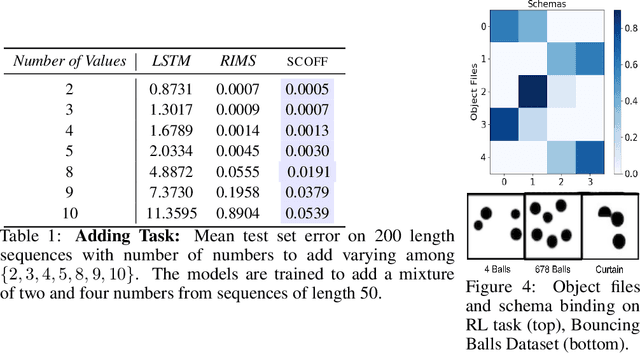
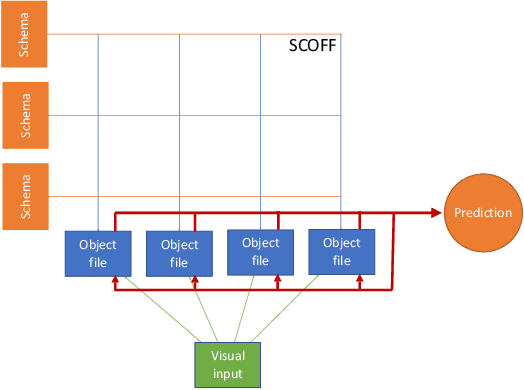

Modeling a structured, dynamic environment like a video game requires keeping track of the objects and their states (\emph{declarative} knowledge) as well as predicting how objects behave (\emph{procedural} knowledge). Black-box models with a monolithic hidden state often lack \emph{systematicity}: they fail to apply procedural knowledge consistently and uniformly. For example, in a video game, correct prediction of one enemy's trajectory does not ensure correct prediction of another's. We address this issue via an architecture that factorizes declarative and procedural knowledge and that imposes modularity within each form of knowledge. The architecture consists of active modules called \emph{object files} that maintain the state of a single object and invoke passive external knowledge sources called \emph{schemata} that prescribe state updates. To use a video game as an illustration, two enemies of the same type will share schemata but will each have their own object file to encode their distinct state (e.g., health, position). We propose to use attention to control the determination of which object files to update, the selection of schemata, and the propagation of information between object files. The resulting architecture is a drop-in replacement conforming to the same input-output interface as normal recurrent networks (e.g., LSTM, GRU) yet achieves substantially better generalization on environments that have factorized declarative and procedural knowledge, including a challenging intuitive physics benchmark.
Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neural Networks with Attention over Modules
Jun 30, 2020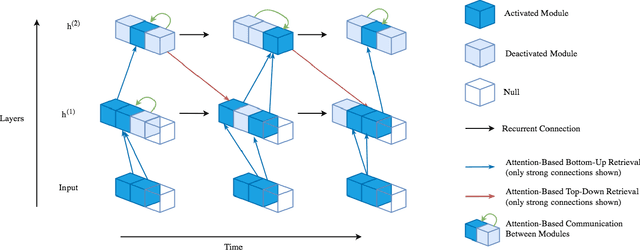
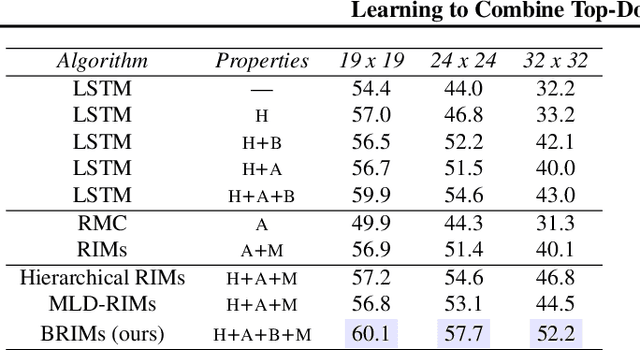
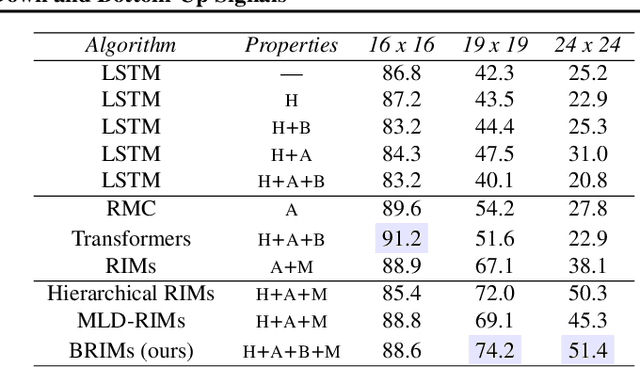
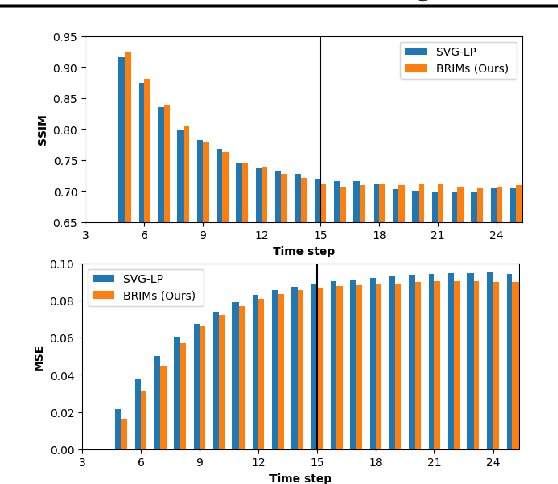
Robust perception relies on both bottom-up and top-down signals. Bottom-up signals consist of what's directly observed through sensation. Top-down signals consist of beliefs and expectations based on past experience and short-term memory, such as how the phrase `peanut butter and~...' will be completed. The optimal combination of bottom-up and top-down information remains an open question, but the manner of combination must be dynamic and both context and task dependent. To effectively utilize the wealth of potential top-down information available, and to prevent the cacophony of intermixed signals in a bidirectional architecture, mechanisms are needed to restrict information flow. We explore deep recurrent neural net architectures in which bottom-up and top-down signals are dynamically combined using attention. Modularity of the architecture further restricts the sharing and communication of information. Together, attention and modularity direct information flow, which leads to reliable performance improvements in perceptual and language tasks, and in particular improves robustness to distractions and noisy data. We demonstrate on a variety of benchmarks in language modeling, sequential image classification, video prediction and reinforcement learning that the \emph{bidirectional} information flow can improve results over strong baselines.
Hybrid Models for Learning to Branch
Jun 26, 2020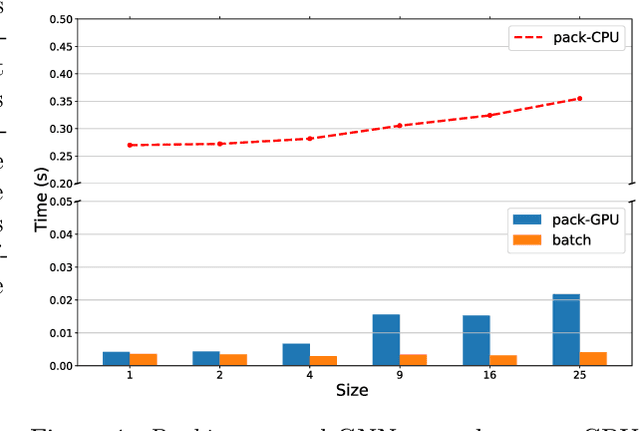
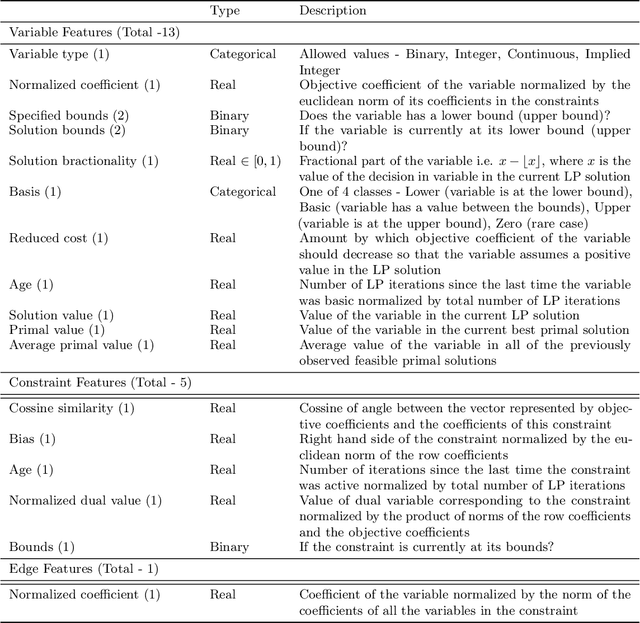
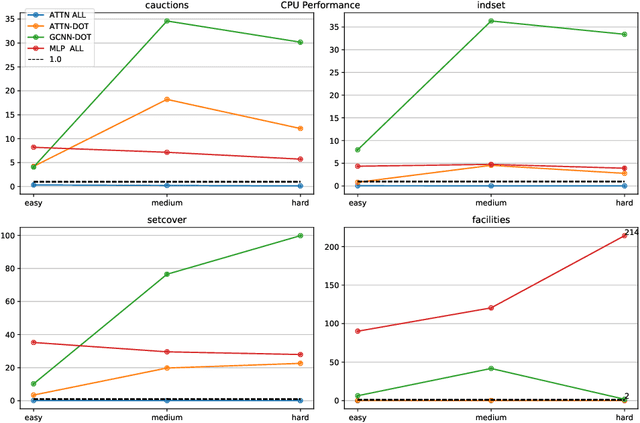

A recent Graph Neural Network (GNN) approach for learning to branch has been shown to successfully reduce the running time of branch-and-bound algorithms for Mixed Integer Linear Programming (MILP). While the GNN relies on a GPU for inference, MILP solvers are purely CPU-based. This severely limits its application as many practitioners may not have access to high-end GPUs. In this work, we ask two key questions. First, in a more realistic setting where only a CPU is available, is the GNN model still competitive? Second, can we devise an alternate computationally inexpensive model that retains the predictive power of the GNN architecture? We answer the first question in the negative, and address the second question by proposing a new hybrid architecture for efficient branching on CPU machines. The proposed architecture combines the expressive power of GNNs with computationally inexpensive multi-linear perceptrons (MLP) for branching. We evaluate our methods on four classes of MILP problems, and show that they lead to up to 26% reduction in solver running time compared to state-of-the-art methods without a GPU, while extrapolating to harder problems than it was trained on.