 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgehBert + BiasCorp -- Fighting Racism on the Web
Apr 06, 2021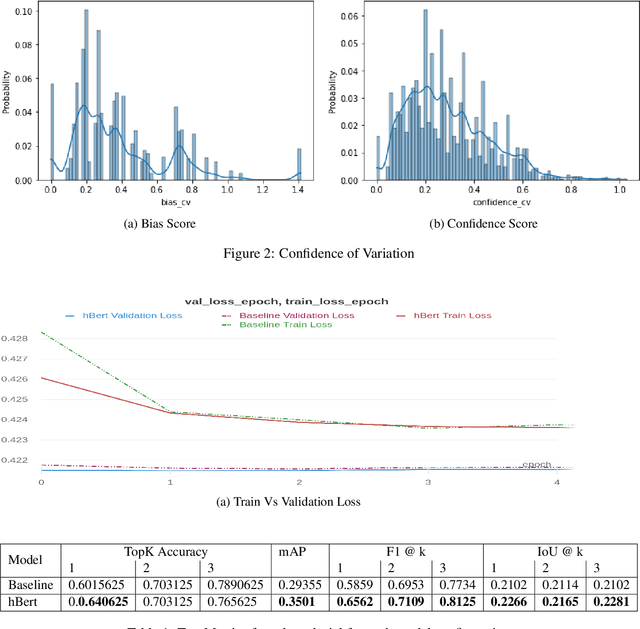
Subtle and overt racism is still present both in physical and online communities today and has impacted many lives in different segments of the society. In this short piece of work, we present how we're tackling this societal issue with Natural Language Processing. We are releasing BiasCorp, a dataset containing 139,090 comments and news segment from three specific sources - Fox News, BreitbartNews and YouTube. The first batch (45,000 manually annotated) is ready for publication. We are currently in the final phase of manually labeling the remaining dataset using Amazon Mechanical Turk. BERT has been used widely in several downstream tasks. In this work, we present hBERT, where we modify certain layers of the pretrained BERT model with the new Hopfield Layer. hBert generalizes well across different distributions with the added advantage of a reduced model complexity. We are also releasing a JavaScript library and a Chrome Extension Application, to help developers make use of our trained model in web applications (say chat application) and for users to identify and report racially biased contents on the web respectively.
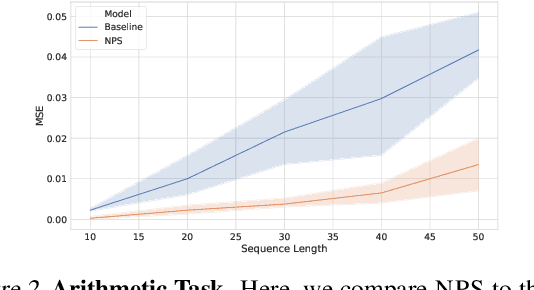
Neural Production Systems
Mar 02, 2021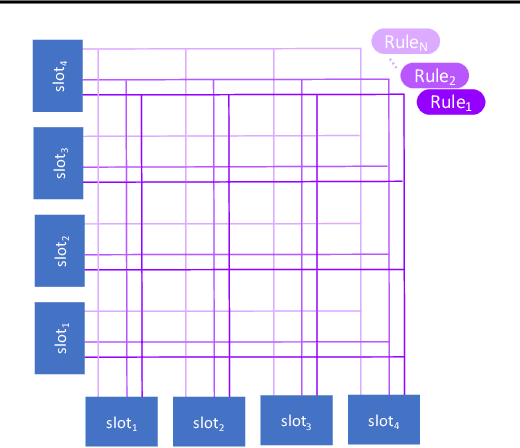

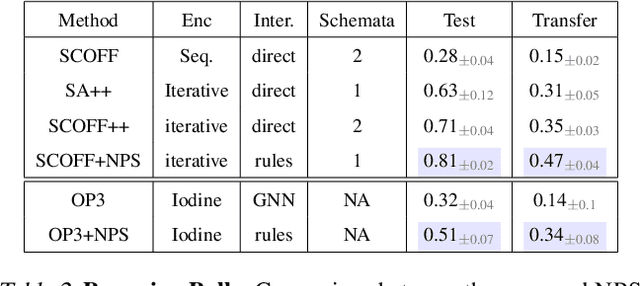
Visual environments are structured, consisting of distinct objects or entities. These entities have properties -- both visible and latent -- that determine the manner in which they interact with one another. To partition images into entities, deep-learning researchers have proposed structural inductive biases such as slot-based architectures. To model interactions among entities, equivariant graph neural nets (GNNs) are used, but these are not particularly well suited to the task for two reasons. First, GNNs do not predispose interactions to be sparse, as relationships among independent entities are likely to be. Second, GNNs do not factorize knowledge about interactions in an entity-conditional manner. As an alternative, we take inspiration from cognitive science and resurrect a classic approach, production systems, which consist of a set of rule templates that are applied by binding placeholder variables in the rules to specific entities. Rules are scored on their match to entities, and the best fitting rules are applied to update entity properties. In a series of experiments, we demonstrate that this architecture achieves a flexible, dynamic flow of control and serves to factorize entity-specific and rule-based information. This disentangling of knowledge achieves robust future-state prediction in rich visual environments, outperforming state-of-the-art methods using GNNs, and allows for the extrapolation from simple (few object) environments to more complex environments.
Coordination Among Neural Modules Through a Shared Global Workspace
Mar 01, 2021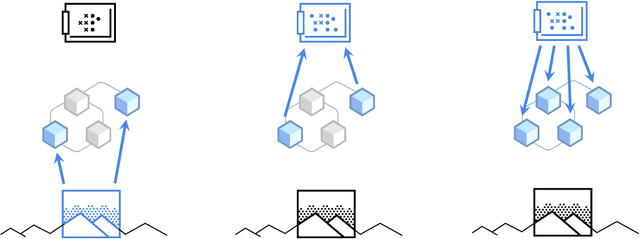
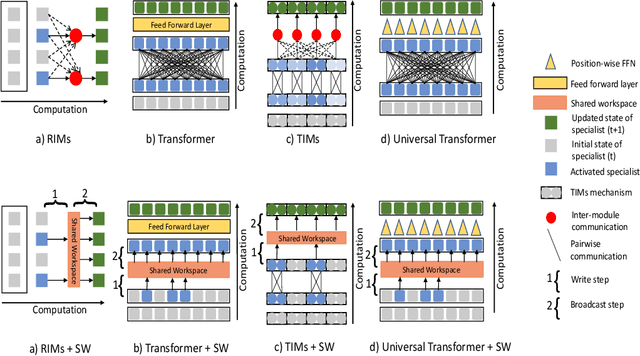
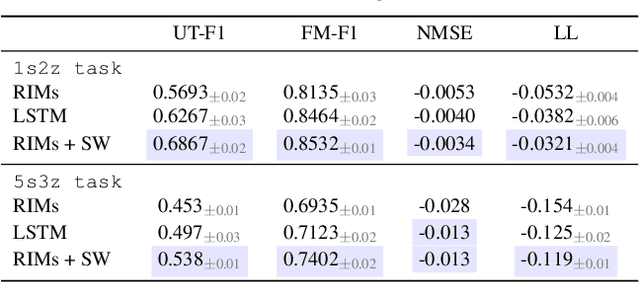
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
Learning Neural Generative Dynamics for Molecular Conformation Generation
Feb 28, 2021
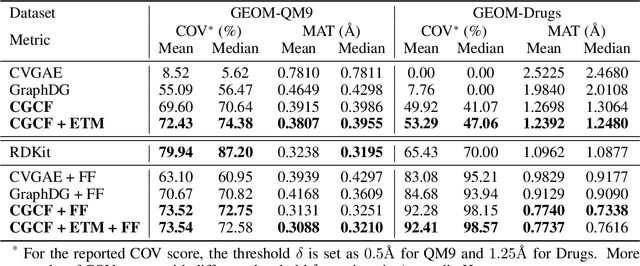
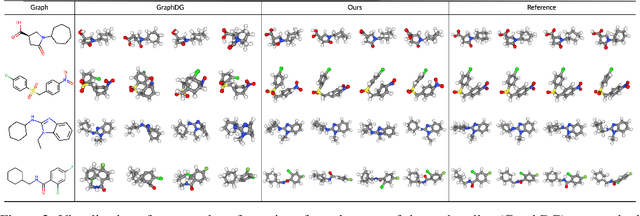
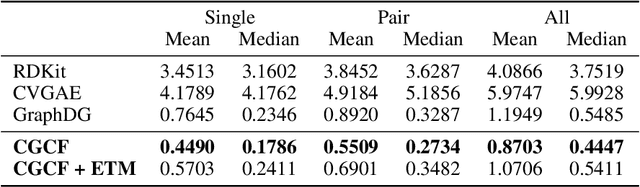
We study how to generate molecule conformations (\textit{i.e.}, 3D structures) from a molecular graph. Traditional methods, such as molecular dynamics, sample conformations via computationally expensive simulations. Recently, machine learning methods have shown great potential by training on a large collection of conformation data. Challenges arise from the limited model capacity for capturing complex distributions of conformations and the difficulty in modeling long-range dependencies between atoms. Inspired by the recent progress in deep generative models, in this paper, we propose a novel probabilistic framework to generate valid and diverse conformations given a molecular graph. We propose a method combining the advantages of both flow-based and energy-based models, enjoying: (1) a high model capacity to estimate the multimodal conformation distribution; (2) explicitly capturing the complex long-range dependencies between atoms in the observation space. Extensive experiments demonstrate the superior performance of the proposed method on several benchmarks, including conformation generation and distance modeling tasks, with a significant improvement over existing generative models for molecular conformation sampling.
Transformers with Competitive Ensembles of Independent Mechanisms
Feb 27, 2021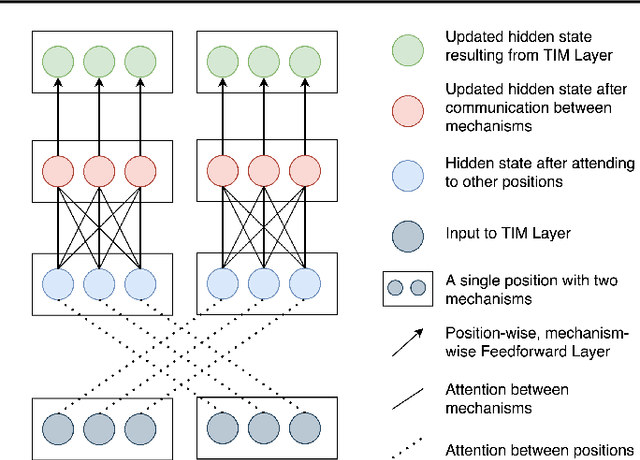
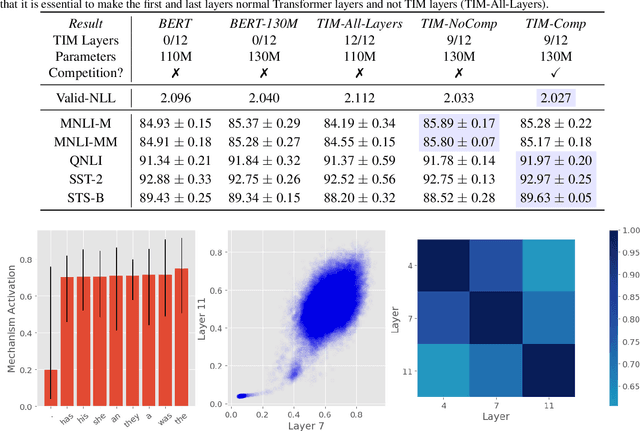
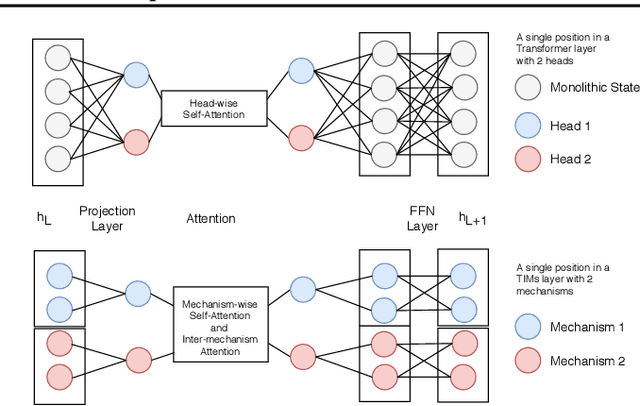
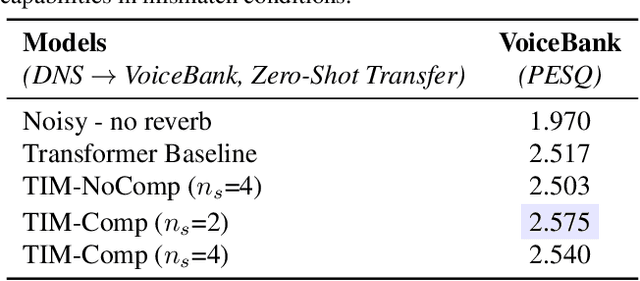
An important development in deep learning from the earliest MLPs has been a move towards architectures with structural inductive biases which enable the model to keep distinct sources of information and routes of processing well-separated. This structure is linked to the notion of independent mechanisms from the causality literature, in which a mechanism is able to retain the same processing as irrelevant aspects of the world are changed. For example, convnets enable separation over positions, while attention-based architectures (especially Transformers) learn which combination of positions to process dynamically. In this work we explore a way in which the Transformer architecture is deficient: it represents each position with a large monolithic hidden representation and a single set of parameters which are applied over the entire hidden representation. This potentially throws unrelated sources of information together, and limits the Transformer's ability to capture independent mechanisms. To address this, we propose Transformers with Independent Mechanisms (TIM), a new Transformer layer which divides the hidden representation and parameters into multiple mechanisms, which only exchange information through attention. Additionally, we propose a competition mechanism which encourages these mechanisms to specialize over time steps, and thus be more independent. We study TIM on a large-scale BERT model, on the Image Transformer, and on speech enhancement and find evidence for semantically meaningful specialization as well as improved performance.
Towards Causal Representation Learning
Feb 22, 2021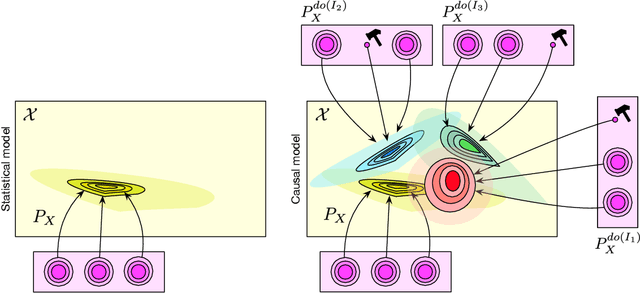

The two fields of machine learning and graphical causality arose and developed separately. However, there is now cross-pollination and increasing interest in both fields to benefit from the advances of the other. In the present paper, we review fundamental concepts of causal inference and relate them to crucial open problems of machine learning, including transfer and generalization, thereby assaying how causality can contribute to modern machine learning research. This also applies in the opposite direction: we note that most work in causality starts from the premise that the causal variables are given. A central problem for AI and causality is, thus, causal representation learning, the discovery of high-level causal variables from low-level observations. Finally, we delineate some implications of causality for machine learning and propose key research areas at the intersection of both communities.
DEUP: Direct Epistemic Uncertainty Prediction
Feb 16, 2021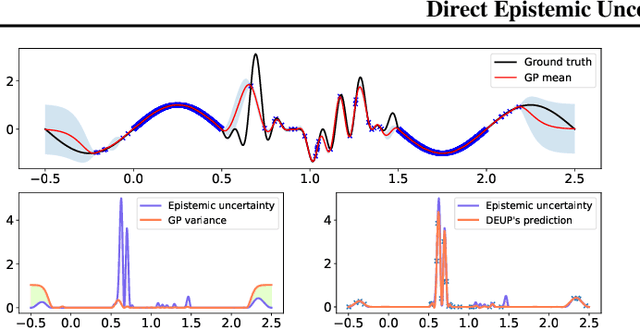
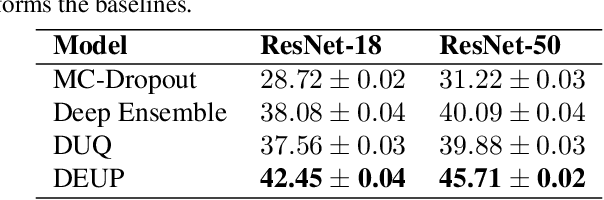
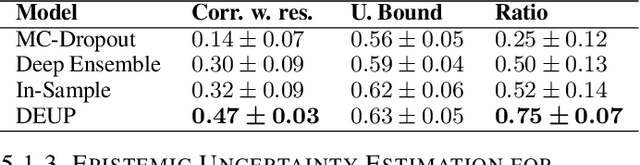
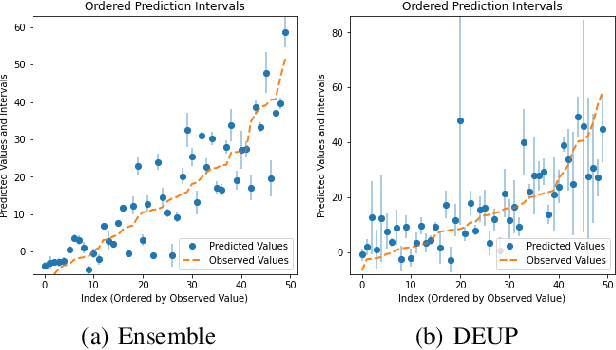
Epistemic uncertainty is the part of out-of-sample prediction error due to the lack of knowledge of the learner. Whereas previous work was focusing on model variance, we propose a principled approach for directly estimating epistemic uncertainty by learning to predict generalization error and subtracting an estimate of aleatoric uncertainty, i.e., intrinsic unpredictability. This estimator of epistemic uncertainty includes the effect of model bias and can be applied in non-stationary learning environments arising in active learning or reinforcement learning. In addition to demonstrating these properties of Direct Epistemic Uncertainty Prediction (DEUP), we illustrate its advantage against existing methods for uncertainty estimation on downstream tasks including sequential model optimization and reinforcement learning. We also evaluate the quality of uncertainty estimates from DEUP for probabilistic classification of images and for estimating uncertainty about synergistic drug combinations.
Structured Sparsity Inducing Adaptive Optimizers for Deep Learning
Feb 07, 2021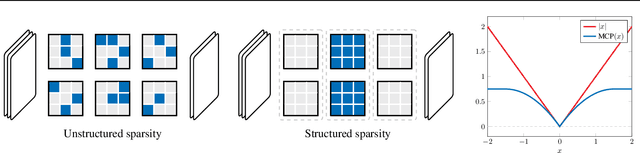
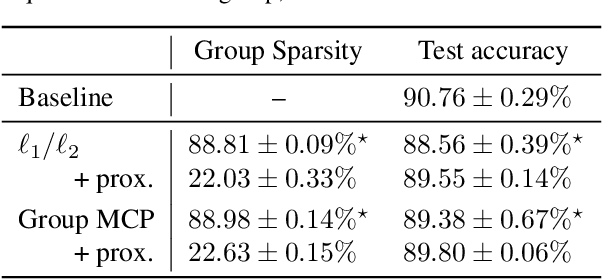
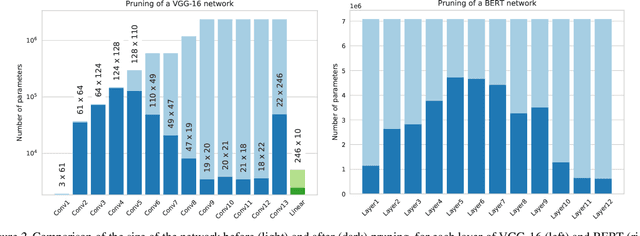
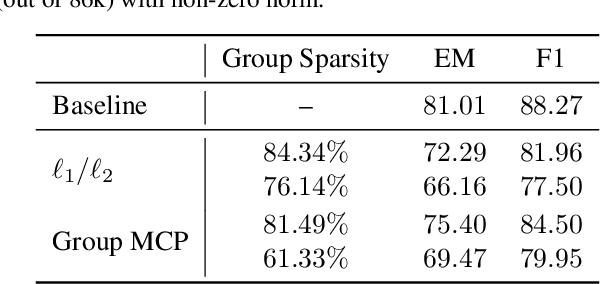
The parameters of a neural network are naturally organized in groups, some of which might not contribute to its overall performance. To prune out unimportant groups of parameters, we can include some non-differentiable penalty to the objective function, and minimize it using proximal gradient methods. In this paper, we derive the weighted proximal operator, which is a necessary component of these proximal methods, of two structured sparsity inducing penalties. Moreover, they can be approximated efficiently with a numerical solver, and despite this approximation, we prove that existing convergence guarantees are preserved when these operators are integrated as part of a generic adaptive proximal method. Finally, we show that this adaptive method, together with the weighted proximal operators derived here, is indeed capable of finding solutions with structure in their sparsity patterns, on representative examples from computer vision and natural language processing.
Scaling Equilibrium Propagation to Deep ConvNets by Drastically Reducing its Gradient Estimator Bias
Jan 14, 2021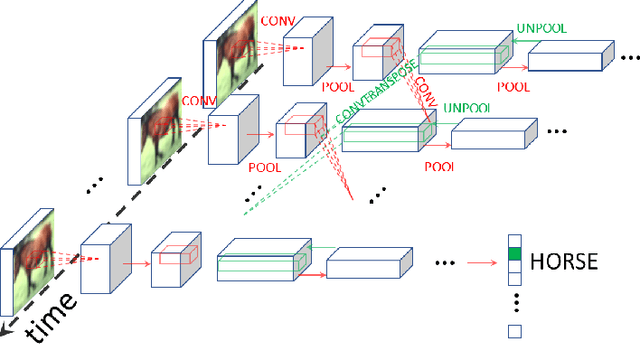
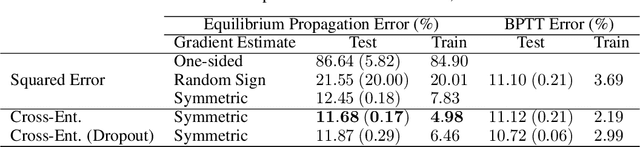
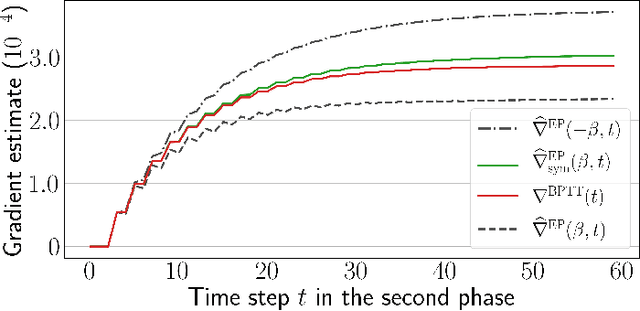

Equilibrium Propagation (EP) is a biologically-inspired counterpart of Backpropagation Through Time (BPTT) which, owing to its strong theoretical guarantees and the locality in space of its learning rule, fosters the design of energy-efficient hardware dedicated to learning. In practice, however, EP does not scale to visual tasks harder than MNIST. In this work, we show that a bias in the gradient estimate of EP, inherent in the use of finite nudging, is responsible for this phenomenon and that cancelling it allows training deep ConvNets by EP, including architectures with distinct forward and backward connections. These results highlight EP as a scalable approach to compute error gradients in deep neural networks, thereby motivating its hardware implementation.
Machine Learning for Glacier Monitoring in the Hindu Kush Himalaya
Dec 09, 2020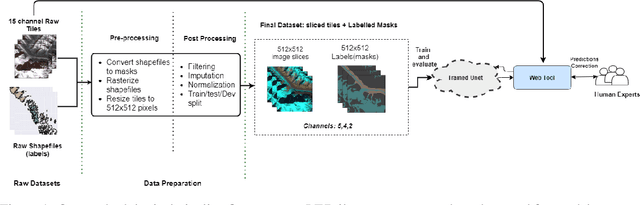

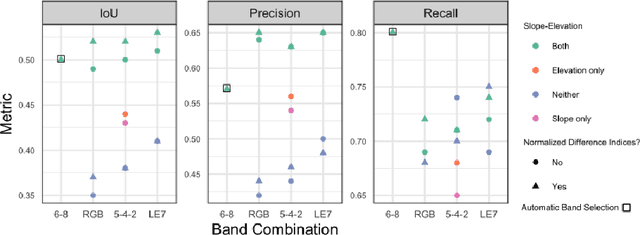

Glacier mapping is key to ecological monitoring in the hkh region. Climate change poses a risk to individuals whose livelihoods depend on the health of glacier ecosystems. In this work, we present a machine learning based approach to support ecological monitoring, with a focus on glaciers. Our approach is based on semi-automated mapping from satellite images. We utilize readily available remote sensing data to create a model to identify and outline both clean ice and debris-covered glaciers from satellite imagery. We also release data and develop a web tool that allows experts to visualize and correct model predictions, with the ultimate aim of accelerating the glacier mapping process.