 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
Jul 02, 2021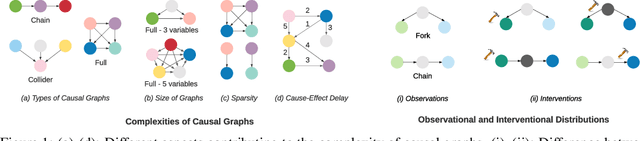
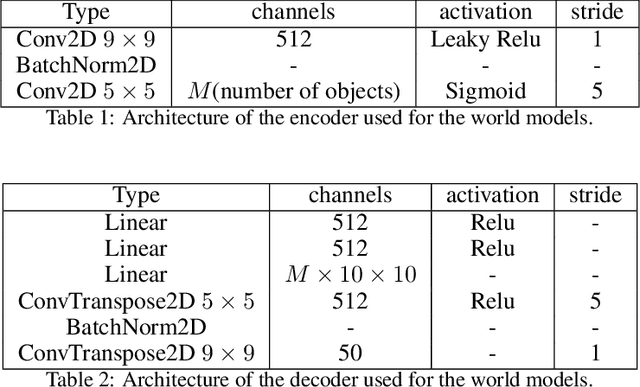
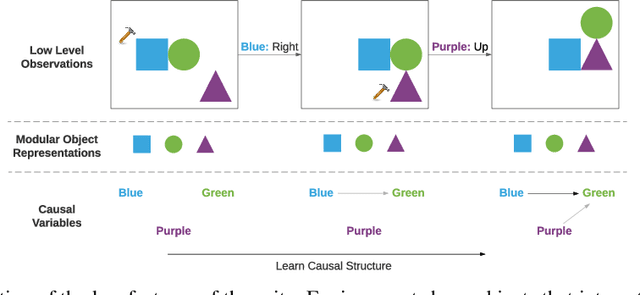
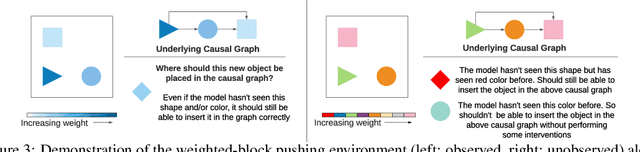
Inducing causal relationships from observations is a classic problem in machine learning. Most work in causality starts from the premise that the causal variables themselves are observed. However, for AI agents such as robots trying to make sense of their environment, the only observables are low-level variables like pixels in images. To generalize well, an agent must induce high-level variables, particularly those which are causal or are affected by causal variables. A central goal for AI and causality is thus the joint discovery of abstract representations and causal structure. However, we note that existing environments for studying causal induction are poorly suited for this objective because they have complicated task-specific causal graphs which are impossible to manipulate parametrically (e.g., number of nodes, sparsity, causal chain length, etc.). In this work, our goal is to facilitate research in learning representations of high-level variables as well as causal structures among them. In order to systematically probe the ability of methods to identify these variables and structures, we design a suite of benchmarking RL environments. We evaluate various representation learning algorithms from the literature and find that explicitly incorporating structure and modularity in models can help causal induction in model-based reinforcement learning.
Predicting Unreliable Predictions by Shattering a Neural Network
Jun 15, 2021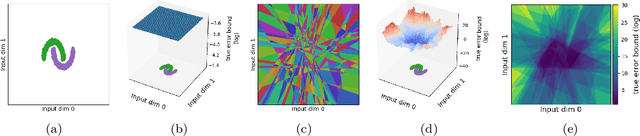
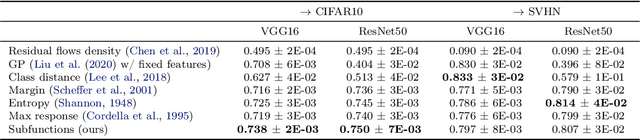
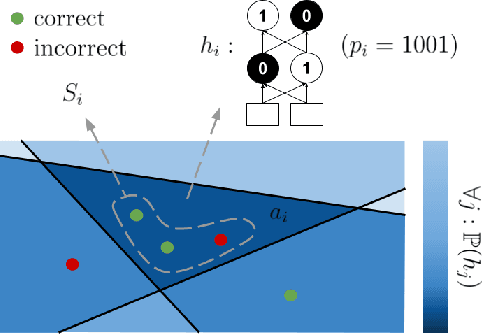

Piecewise linear neural networks can be split into subfunctions, each with its own activation pattern, domain, and empirical error. Empirical error for the full network can be written as an expectation over empirical error of subfunctions. Constructing a generalization bound on subfunction empirical error indicates that the more densely a subfunction is surrounded by training samples in representation space, the more reliable its predictions are. Further, it suggests that models with fewer activation regions generalize better, and models that abstract knowledge to a greater degree generalize better, all else equal. We propose not only a theoretical framework to reason about subfunction error bounds but also a pragmatic way of approximately evaluating it, which we apply to predicting which samples the network will not successfully generalize to. We test our method on detection of misclassification and out-of-distribution samples, finding that it performs competitively in both cases. In short, some network activation patterns are associated with higher reliability than others, and these can be identified using subfunction error bounds.
Variational Causal Networks: Approximate Bayesian Inference over Causal Structures
Jun 14, 2021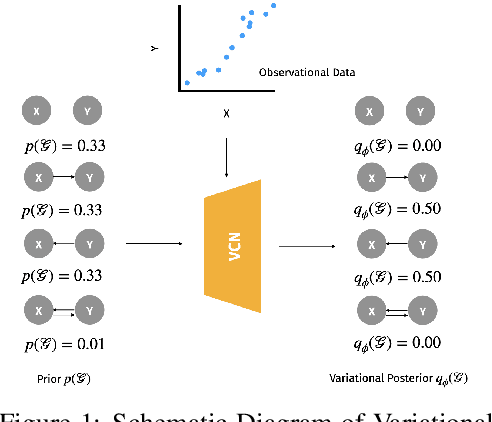
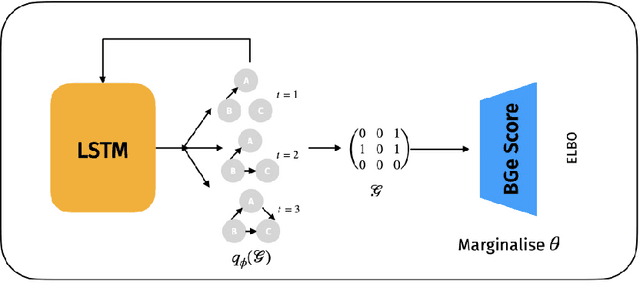
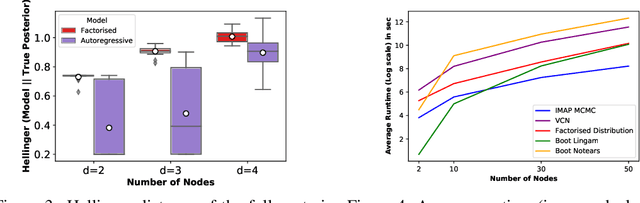
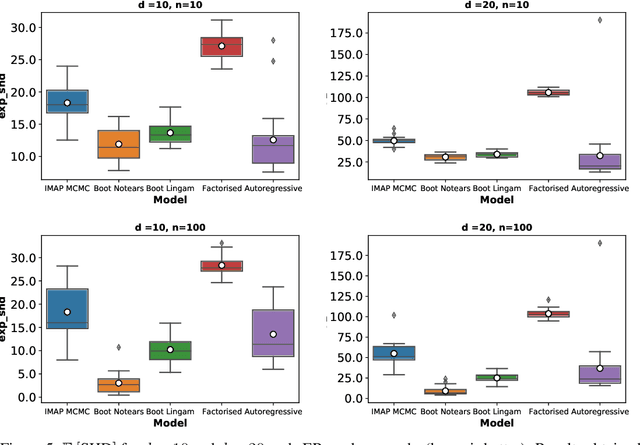
Learning the causal structure that underlies data is a crucial step towards robust real-world decision making. The majority of existing work in causal inference focuses on determining a single directed acyclic graph (DAG) or a Markov equivalence class thereof. However, a crucial aspect to acting intelligently upon the knowledge about causal structure which has been inferred from finite data demands reasoning about its uncertainty. For instance, planning interventions to find out more about the causal mechanisms that govern our data requires quantifying epistemic uncertainty over DAGs. While Bayesian causal inference allows to do so, the posterior over DAGs becomes intractable even for a small number of variables. Aiming to overcome this issue, we propose a form of variational inference over the graphs of Structural Causal Models (SCMs). To this end, we introduce a parametric variational family modelled by an autoregressive distribution over the space of discrete DAGs. Its number of parameters does not grow exponentially with the number of variables and can be tractably learned by maximising an Evidence Lower Bound (ELBO). In our experiments, we demonstrate that the proposed variational posterior is able to provide a good approximation of the true posterior.
Invariance Principle Meets Information Bottleneck for Out-of-Distribution Generalization
Jun 11, 2021
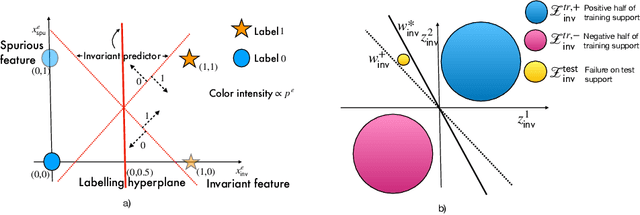

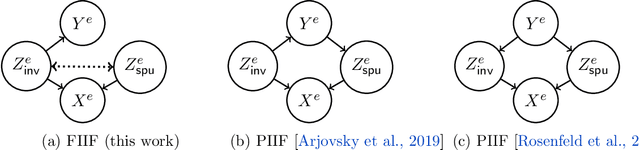
The invariance principle from causality is at the heart of notable approaches such as invariant risk minimization (IRM) that seek to address out-of-distribution (OOD) generalization failures. Despite the promising theory, invariance principle-based approaches fail in common classification tasks, where invariant (causal) features capture all the information about the label. Are these failures due to the methods failing to capture the invariance? Or is the invariance principle itself insufficient? To answer these questions, we revisit the fundamental assumptions in linear regression tasks, where invariance-based approaches were shown to provably generalize OOD. In contrast to the linear regression tasks, we show that for linear classification tasks we need much stronger restrictions on the distribution shifts, or otherwise OOD generalization is impossible. Furthermore, even with appropriate restrictions on distribution shifts in place, we show that the invariance principle alone is insufficient. We prove that a form of the information bottleneck constraint along with invariance helps address key failures when invariant features capture all the information about the label and also retains the existing success when they do not. We propose an approach that incorporates both of these principles and demonstrate its effectiveness in several experiments.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021
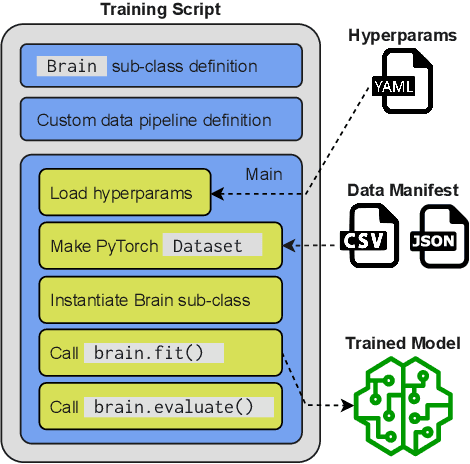

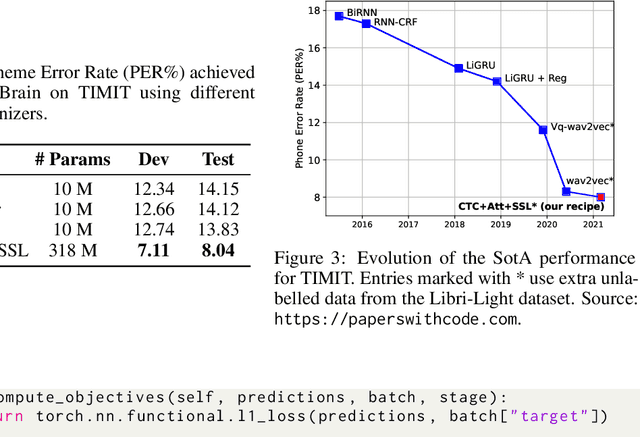
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation
Jun 08, 2021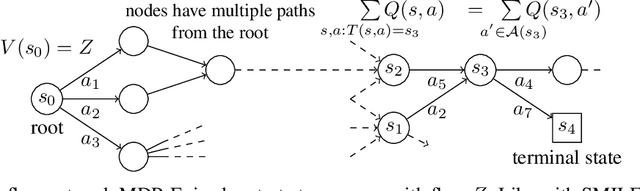
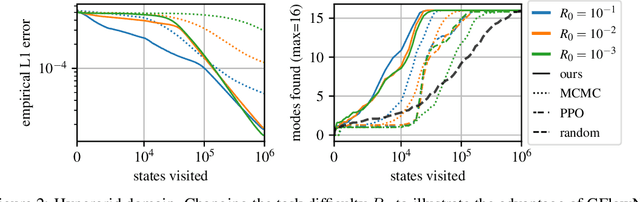
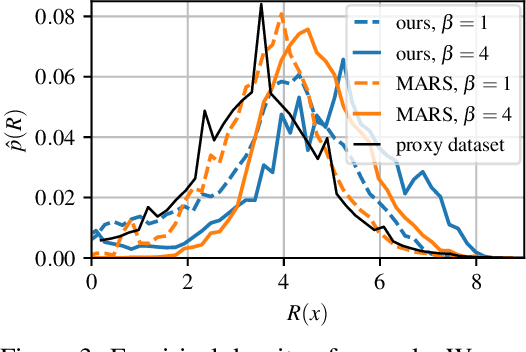
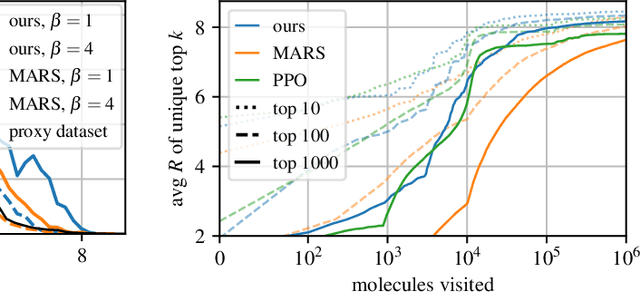
This paper is about the problem of learning a stochastic policy for generating an object (like a molecular graph) from a sequence of actions, such that the probability of generating an object is proportional to a given positive reward for that object. Whereas standard return maximization tends to converge to a single return-maximizing sequence, there are cases where we would like to sample a diverse set of high-return solutions. These arise, for example, in black-box function optimization when few rounds are possible, each with large batches of queries, where the batches should be diverse, e.g., in the design of new molecules. One can also see this as a problem of approximately converting an energy function to a generative distribution. While MCMC methods can achieve that, they are expensive and generally only perform local exploration. Instead, training a generative policy amortizes the cost of search during training and yields to fast generation. Using insights from Temporal Difference learning, we propose GFlowNet, based on a view of the generative process as a flow network, making it possible to handle the tricky case where different trajectories can yield the same final state, e.g., there are many ways to sequentially add atoms to generate some molecular graph. We cast the set of trajectories as a flow and convert the flow consistency equations into a learning objective, akin to the casting of the Bellman equations into Temporal Difference methods. We prove that any global minimum of the proposed objectives yields a policy which samples from the desired distribution, and demonstrate the improved performance and diversity of GFlowNet on a simple domain where there are many modes to the reward function, and on a molecule synthesis task.
A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning
Jun 03, 2021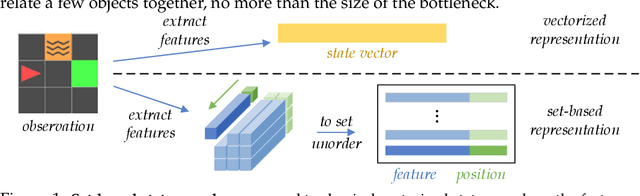
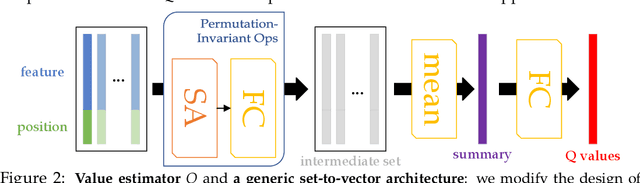
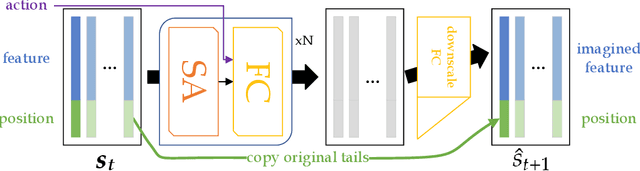
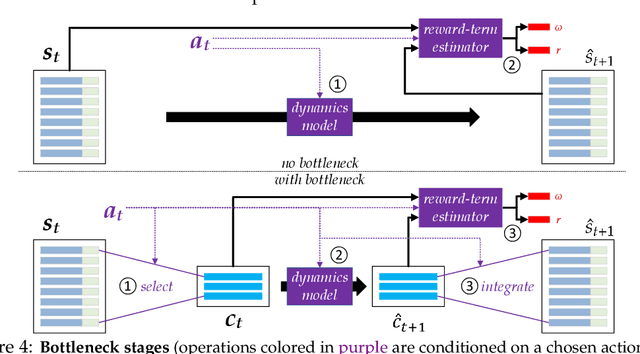
We present an end-to-end, model-based deep reinforcement learning agent which dynamically attends to relevant parts of its state, in order to plan and to generalize better out-of-distribution. The agent's architecture uses a set representation and a bottleneck mechanism, forcing the number of entities to which the agent attends at each planning step to be small. In experiments with customized MiniGrid environments with different dynamics, we observe that the design allows agents to learn to plan effectively, by attending to the relevant objects, leading to better out-of-distribution generalization.
An End-to-End Framework for Molecular Conformation Generation via Bilevel Programming
Jun 02, 2021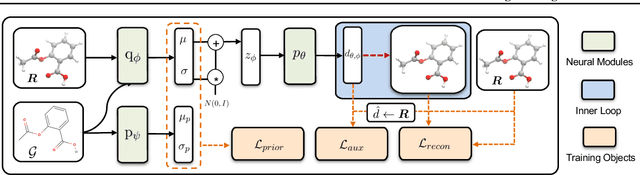
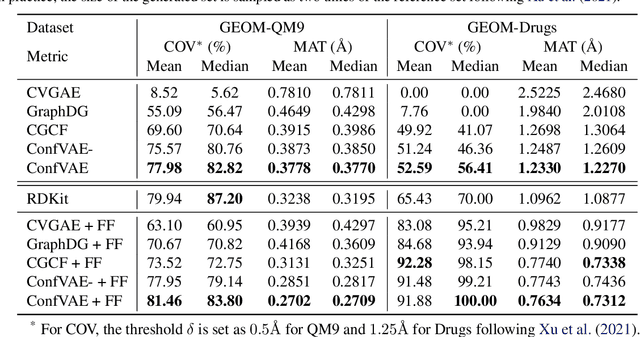
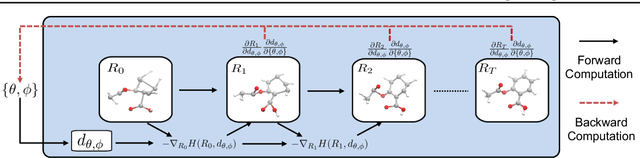
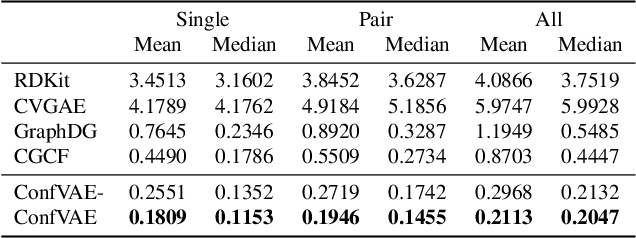
Predicting molecular conformations (or 3D structures) from molecular graphs is a fundamental problem in many applications. Most existing approaches are usually divided into two steps by first predicting the distances between atoms and then generating a 3D structure through optimizing a distance geometry problem. However, the distances predicted with such two-stage approaches may not be able to consistently preserve the geometry of local atomic neighborhoods, making the generated structures unsatisfying. In this paper, we propose an end-to-end solution for molecular conformation prediction called ConfVAE based on the conditional variational autoencoder framework. Specifically, the molecular graph is first encoded in a latent space, and then the 3D structures are generated by solving a principled bilevel optimization program. Extensive experiments on several benchmark data sets prove the effectiveness of our proposed approach over existing state-of-the-art approaches. Code is available at \url{https://github.com/MinkaiXu/ConfVAE-ICML21}.
Fast and Slow Learning of Recurrent Independent Mechanisms
May 19, 2021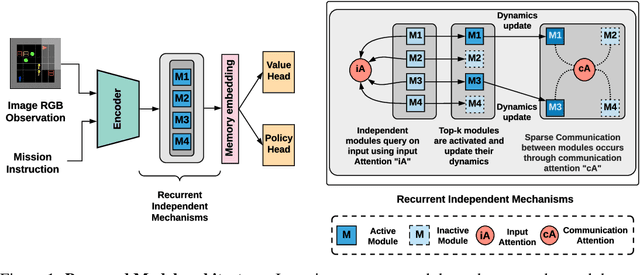

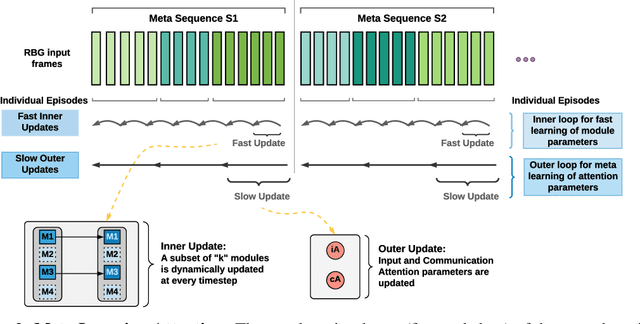
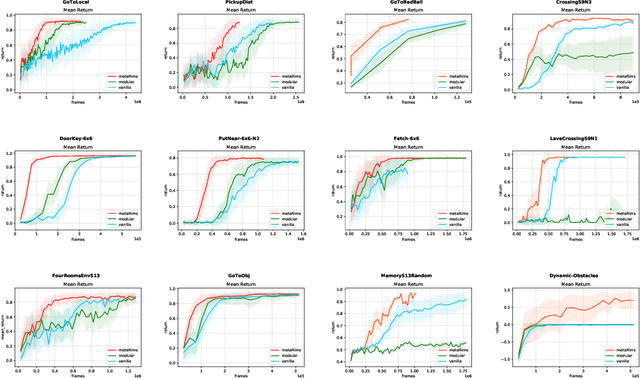
Decomposing knowledge into interchangeable pieces promises a generalization advantage when there are changes in distribution. A learning agent interacting with its environment is likely to be faced with situations requiring novel combinations of existing pieces of knowledge. We hypothesize that such a decomposition of knowledge is particularly relevant for being able to generalize in a systematic manner to out-of-distribution changes. To study these ideas, we propose a particular training framework in which we assume that the pieces of knowledge an agent needs and its reward function are stationary and can be re-used across tasks. An attention mechanism dynamically selects which modules can be adapted to the current task, and the parameters of the selected modules are allowed to change quickly as the learner is confronted with variations in what it experiences, while the parameters of the attention mechanisms act as stable, slowly changing, meta-parameters. We focus on pieces of knowledge captured by an ensemble of modules sparsely communicating with each other via a bottleneck of attention. We find that meta-learning the modular aspects of the proposed system greatly helps in achieving faster adaptation in a reinforcement learning setup involving navigation in a partially observed grid world with image-level input. We also find that reversing the role of parameters and meta-parameters does not work nearly as well, suggesting a particular role for fast adaptation of the dynamically selected modules.
Comparative Study of Learning Outcomes for Online Learning Platforms
Apr 15, 2021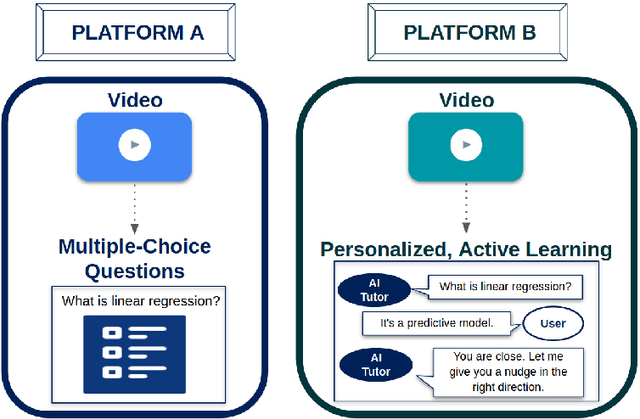

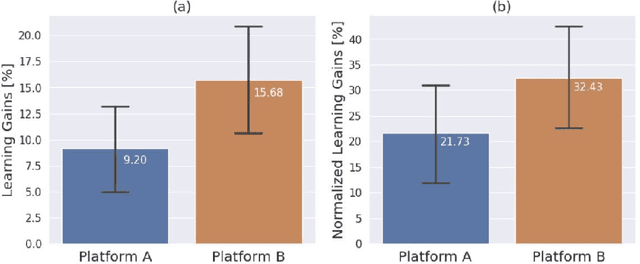
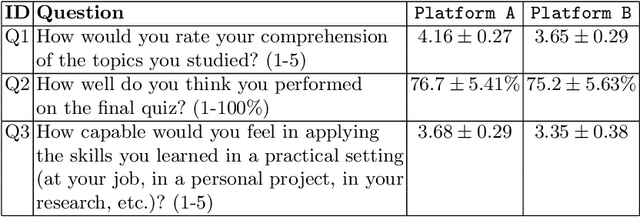
Personalization and active learning are key aspects to successful learning. These aspects are important to address in intelligent educational applications, as they help systems to adapt and close the gap between students with varying abilities, which becomes increasingly important in the context of online and distance learning. We run a comparative head-to-head study of learning outcomes for two popular online learning platforms: Platform A, which follows a traditional model delivering content over a series of lecture videos and multiple-choice quizzes, and Platform B, which creates a personalized learning environment and provides problem-solving exercises and personalized feedback. We report on the results of our study using pre- and post-assessment quizzes with participants taking courses on an introductory data science topic on two platforms. We observe a statistically significant increase in the learning outcomes on Platform B, highlighting the impact of well-designed and well-engineered technology supporting active learning and problem-based learning in online education. Moreover, the results of the self-assessment questionnaire, where participants reported on perceived learning gains, suggest that participants using Platform B improve their metacognition.