 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibriVAD: A Scalable Open Dataset with Deep Learning Benchmarks for Voice Activity Detection
Dec 19, 2025Robust Voice Activity Detection (VAD) remains a challenging task, especially under noisy, diverse, and unseen acoustic conditions. Beyond algorithmic development, a key limitation in advancing VAD research is the lack of large-scale, systematically controlled, and publicly available datasets. To address this, we introduce LibriVAD - a scalable open-source dataset derived from LibriSpeech and augmented with diverse real-world and synthetic noise sources. LibriVAD enables systematic control over speech-to-noise ratio, silence-to-speech ratio (SSR), and noise diversity, and is released in three sizes (15 GB, 150 GB, and 1.5 TB) with two variants (LibriVAD-NonConcat and LibriVAD-Concat) to support different experimental setups. We benchmark multiple feature-model combinations, including waveform, Mel-Frequency Cepstral Coefficients (MFCC), and Gammatone filter bank cepstral coefficients, and introduce the Vision Transformer (ViT) architecture for VAD. Our experiments show that ViT with MFCC features consistently outperforms established VAD models such as boosted deep neural network and convolutional long short-term memory deep neural network across seen, unseen, and out-of-distribution (OOD) conditions, including evaluation on the real-world VOiCES dataset. We further analyze the impact of dataset size and SSR on model generalization, experimentally showing that scaling up dataset size and balancing SSR noticeably and consistently enhance VAD performance under OOD conditions. All datasets, trained models, and code are publicly released to foster reproducibility and accelerate progress in VAD research.
Automatic Prediction of Amyotrophic Lateral Sclerosis Progression using Longitudinal Speech Transformer
Jun 26, 2024



Automatic prediction of amyotrophic lateral sclerosis (ALS) disease progression provides a more efficient and objective alternative than manual approaches. We propose ALS longitudinal speech transformer (ALST), a neural network-based automatic predictor of ALS disease progression from longitudinal speech recordings of ALS patients. By taking advantage of high-quality pretrained speech features and longitudinal information in the recordings, our best model achieves 91.0\% AUC, improving upon the previous best model by 5.6\% relative on the ALS TDI dataset. Careful analysis reveals that ALST is capable of fine-grained and interpretable predictions of ALS progression, especially for distinguishing between rarer and more severe cases. Code is publicly available.
Improved Cross-Lingual Transfer Learning For Automatic Speech Translation
Jun 01, 2023



Research in multilingual speech-to-text translation is topical. Having a single model that supports multiple translation tasks is desirable. The goal of this work it to improve cross-lingual transfer learning in multilingual speech-to-text translation via semantic knowledge distillation. We show that by initializing the encoder of the encoder-decoder sequence-to-sequence translation model with SAMU-XLS-R, a multilingual speech transformer encoder trained using multi-modal (speech-text) semantic knowledge distillation, we achieve significantly better cross-lingual task knowledge transfer than the baseline XLS-R, a multilingual speech transformer encoder trained via self-supervised learning. We demonstrate the effectiveness of our approach on two popular datasets, namely, CoVoST-2 and Europarl. On the 21 translation tasks of the CoVoST-2 benchmark, we achieve an average improvement of 12.8 BLEU points over the baselines. In the zero-shot translation scenario, we achieve an average gain of 18.8 and 11.9 average BLEU points on unseen medium and low-resource languages. We make similar observations on Europarl speech translation benchmark.
On Unsupervised Uncertainty-Driven Speech Pseudo-Label Filtering and Model Calibration
Nov 14, 2022



Pseudo-label (PL) filtering forms a crucial part of Self-Training (ST) methods for unsupervised domain adaptation. Dropout-based Uncertainty-driven Self-Training (DUST) proceeds by first training a teacher model on source domain labeled data. Then, the teacher model is used to provide PLs for the unlabeled target domain data. Finally, we train a student on augmented labeled and pseudo-labeled data. The process is iterative, where the student becomes the teacher for the next DUST iteration. A crucial step that precedes the student model training in each DUST iteration is filtering out noisy PLs that could lead the student model astray. In DUST, we proposed a simple, effective, and theoretically sound PL filtering strategy based on the teacher model's uncertainty about its predictions on unlabeled speech utterances. We estimate the model's uncertainty by computing disagreement amongst multiple samples drawn from the teacher model during inference by injecting noise via dropout. In this work, we show that DUST's PL filtering, as initially used, may fail under severe source and target domain mismatch. We suggest several approaches to eliminate or alleviate this issue. Further, we bring insights from the research in neural network model calibration to DUST and show that a well-calibrated model correlates strongly with a positive outcome of the DUST PL filtering step.
Multi-stage Progressive Compression of Conformer Transducer for On-device Speech Recognition
Oct 01, 2022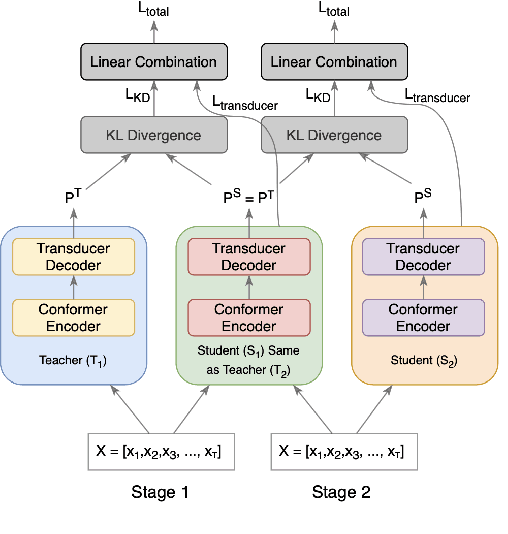
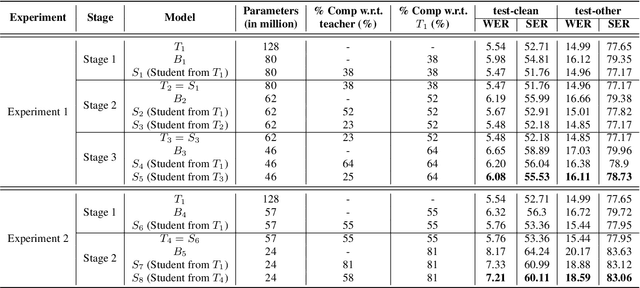
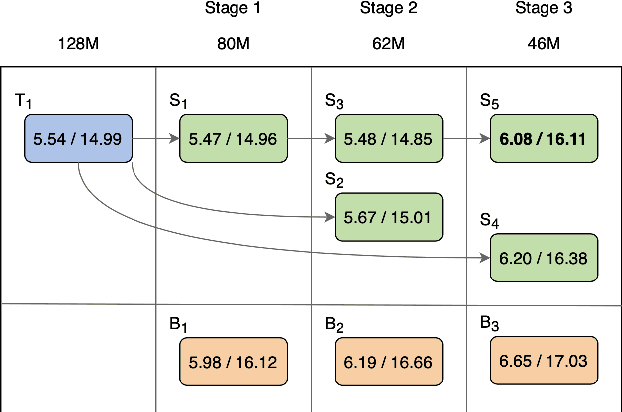
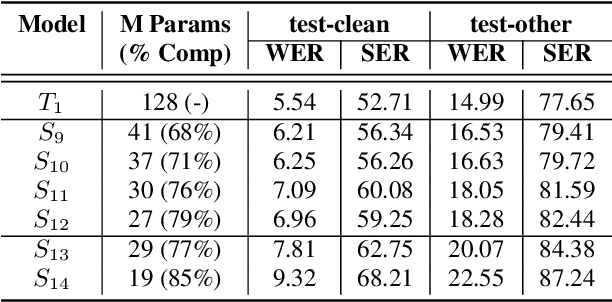
The smaller memory bandwidth in smart devices prompts development of smaller Automatic Speech Recognition (ASR) models. To obtain a smaller model, one can employ the model compression techniques. Knowledge distillation (KD) is a popular model compression approach that has shown to achieve smaller model size with relatively lesser degradation in the model performance. In this approach, knowledge is distilled from a trained large size teacher model to a smaller size student model. Also, the transducer based models have recently shown to perform well for on-device streaming ASR task, while the conformer models are efficient in handling long term dependencies. Hence in this work we employ a streaming transducer architecture with conformer as the encoder. We propose a multi-stage progressive approach to compress the conformer transducer model using KD. We progressively update our teacher model with the distilled student model in a multi-stage setup. On standard LibriSpeech dataset, our experimental results have successfully achieved compression rates greater than 60% without significant degradation in the performance compared to the larger teacher model.
* Published in INTERSPEECH 2022
Two-Pass End-to-End ASR Model Compression
Jan 08, 2022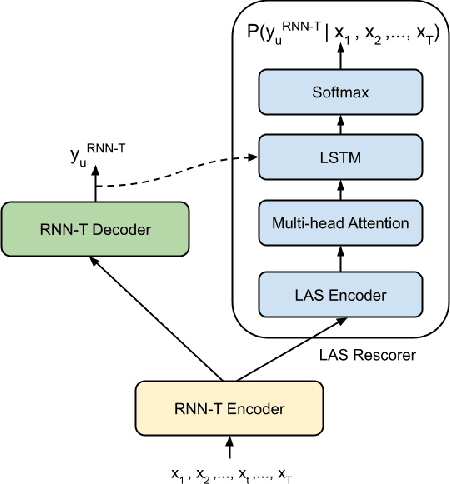

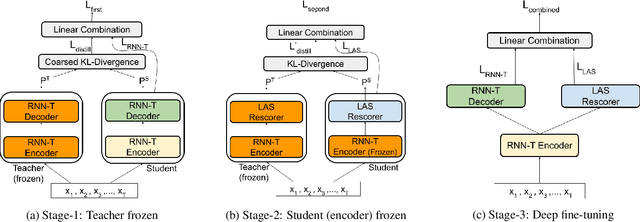
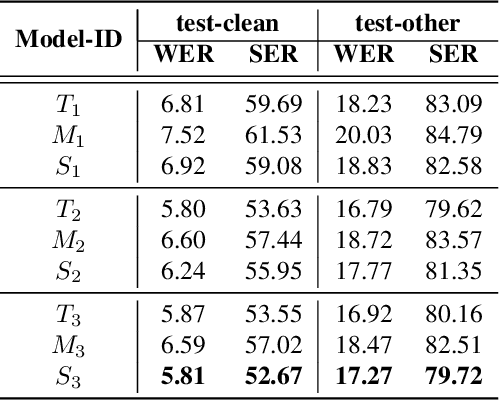
Speech recognition on smart devices is challenging owing to the small memory footprint. Hence small size ASR models are desirable. With the use of popular transducer-based models, it has become possible to practically deploy streaming speech recognition models on small devices [1]. Recently, the two-pass model [2] combining RNN-T and LAS modules has shown exceptional performance for streaming on-device speech recognition. In this work, we propose a simple and effective approach to reduce the size of the two-pass model for memory-constrained devices. We employ a popular knowledge distillation approach in three stages using the Teacher-Student training technique. In the first stage, we use a trained RNN-T model as a teacher model and perform knowledge distillation to train the student RNN-T model. The second stage uses the shared encoder and trains a LAS rescorer for student model using the trained RNN-T+LAS teacher model. Finally, we perform deep-finetuning for the student model with a shared RNN-T encoder, RNN-T decoder, and LAS rescorer. Our experimental results on standard LibriSpeech dataset show that our system can achieve a high compression rate of 55% without significant degradation in the WER compared to the two-pass teacher model.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021
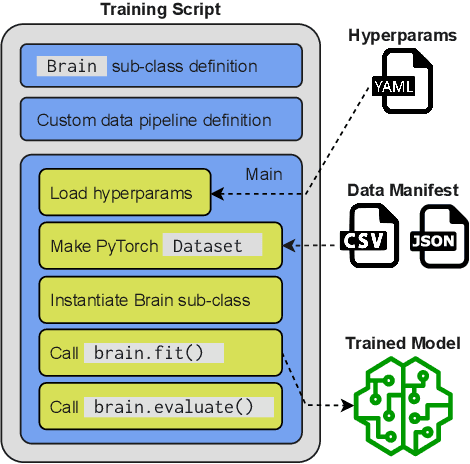

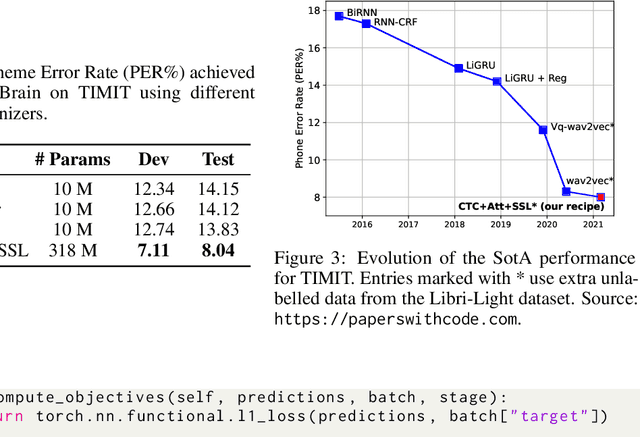
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
ECAPA-TDNN Embeddings for Speaker Diarization
Apr 03, 2021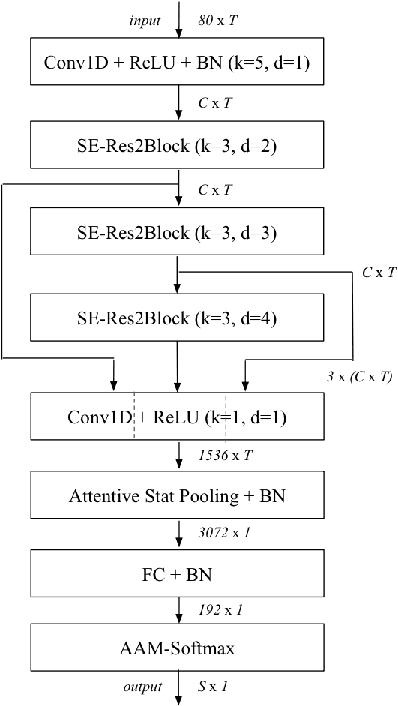
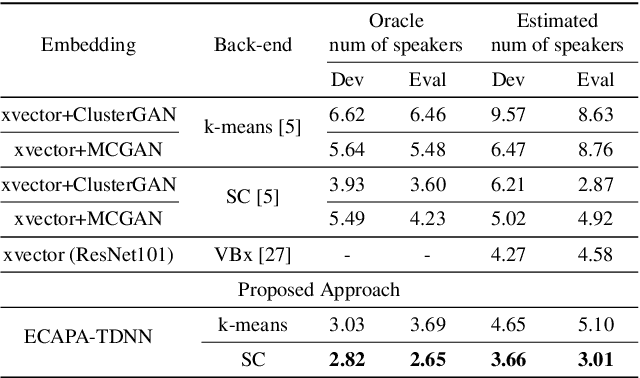
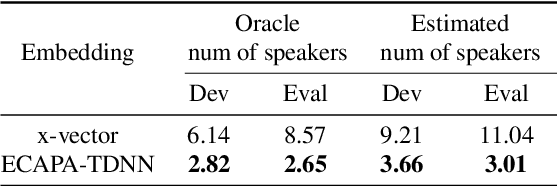
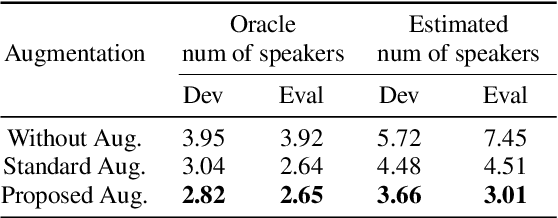
Learning robust speaker embeddings is a crucial step in speaker diarization. Deep neural networks can accurately capture speaker discriminative characteristics and popular deep embeddings such as x-vectors are nowadays a fundamental component of modern diarization systems. Recently, some improvements over the standard TDNN architecture used for x-vectors have been proposed. The ECAPA-TDNN model, for instance, has shown impressive performance in the speaker verification domain, thanks to a carefully designed neural model. In this work, we extend, for the first time, the use of the ECAPA-TDNN model to speaker diarization. Moreover, we improved its robustness with a powerful augmentation scheme that concatenates several contaminated versions of the same signal within the same training batch. The ECAPA-TDNN model turned out to provide robust speaker embeddings under both close-talking and distant-talking conditions. Our results on the popular AMI meeting corpus show that our system significantly outperforms recently proposed approaches.
Front-end Diarization for Percussion Separation in Taniavartanam of Carnatic Music Concerts
Mar 04, 2021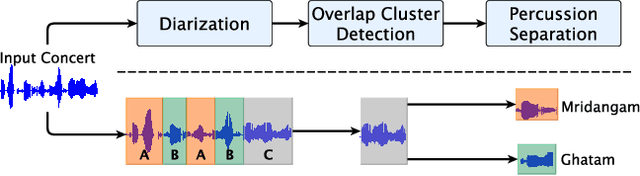
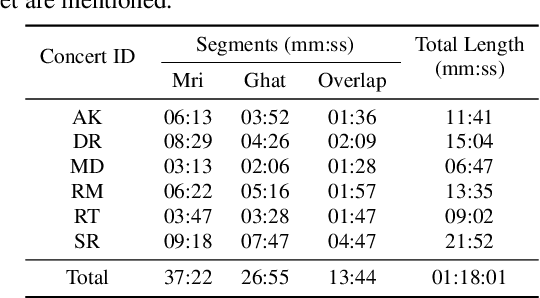
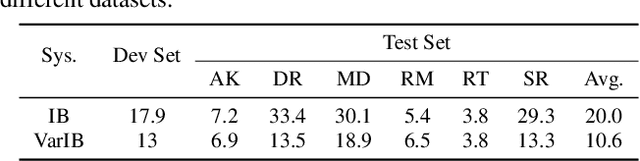
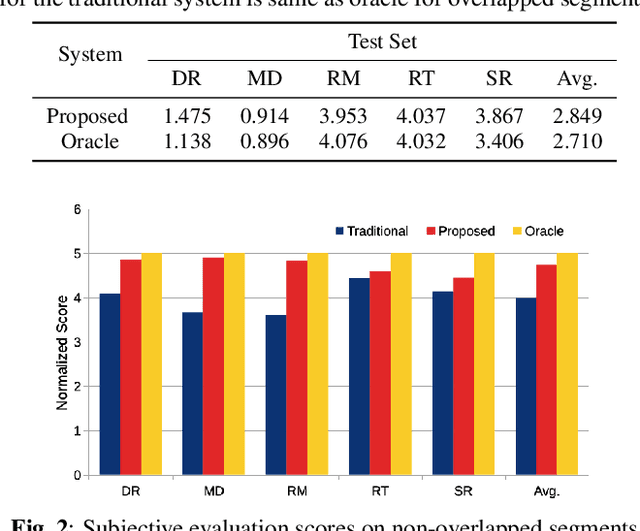
Instrument separation in an ensemble is a challenging task. In this work, we address the problem of separating the percussive voices in the taniavartanam segments of Carnatic music. In taniavartanam, a number of percussive instruments play together or in tandem. Separation of instruments in regions where only one percussion is present leads to interference and artifacts at the output, as source separation algorithms assume the presence of multiple percussive voices throughout the audio segment. We prevent this by first subjecting the taniavartanam to diarization. This process results in homogeneous clusters consisting of segments of either a single voice or multiple voices. A cluster of segments with multiple voices is identified using the Gaussian mixture model (GMM), which is then subjected to source separation. A deep recurrent neural network (DRNN) based approach is used to separate the multiple instrument segments. The effectiveness of the proposed system is evaluated on a standard Carnatic music dataset. The proposed approach provides close-to-oracle performance for non-overlapping segments and a significant improvement over traditional separation schemes.