 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent State Marginalization as a Low-cost Approach for Improving Exploration
Oct 03, 2022

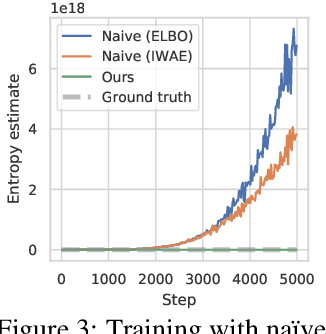
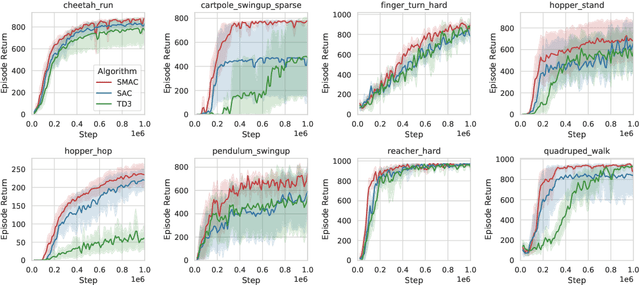
While the maximum entropy (MaxEnt) reinforcement learning (RL) framework -- often touted for its exploration and robustness capabilities -- is usually motivated from a probabilistic perspective, the use of deep probabilistic models has not gained much traction in practice due to their inherent complexity. In this work, we propose the adoption of latent variable policies within the MaxEnt framework, which we show can provably approximate any policy distribution, and additionally, naturally emerges under the use of world models with a latent belief state. We discuss why latent variable policies are difficult to train, how naive approaches can fail, then subsequently introduce a series of improvements centered around low-cost marginalization of the latent state, allowing us to make full use of the latent state at minimal additional cost. We instantiate our method under the actor-critic framework, marginalizing both the actor and critic. The resulting algorithm, referred to as Stochastic Marginal Actor-Critic (SMAC), is simple yet effective. We experimentally validate our method on continuous control tasks, showing that effective marginalization can lead to better exploration and more robust training.
GFlowNets and variational inference
Oct 02, 2022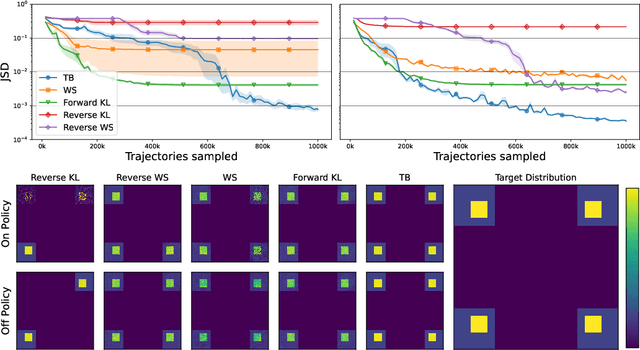
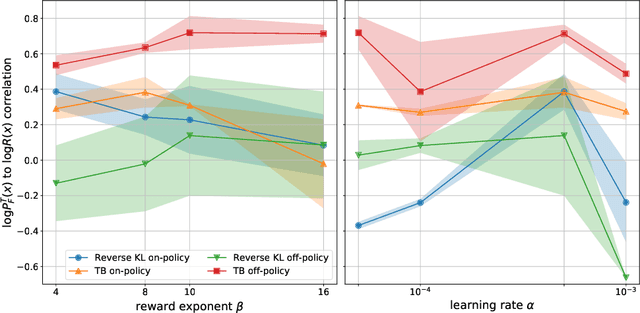
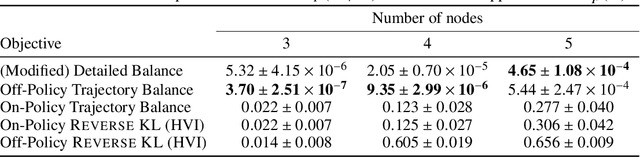
This paper builds bridges between two families of probabilistic algorithms: (hierarchical) variational inference (VI), which is typically used to model distributions over continuous spaces, and generative flow networks (GFlowNets), which have been used for distributions over discrete structures such as graphs. We demonstrate that, in certain cases, VI algorithms are equivalent to special cases of GFlowNets in the sense of equality of expected gradients of their learning objectives. We then point out the differences between the two families and show how these differences emerge experimentally. Notably, GFlowNets, which borrow ideas from reinforcement learning, are more amenable than VI to off-policy training without the cost of high gradient variance induced by importance sampling. We argue that this property of GFlowNets can provide advantages for capturing diversity in multimodal target distributions.
Predictive Inference with Feature Conformal Prediction
Oct 01, 2022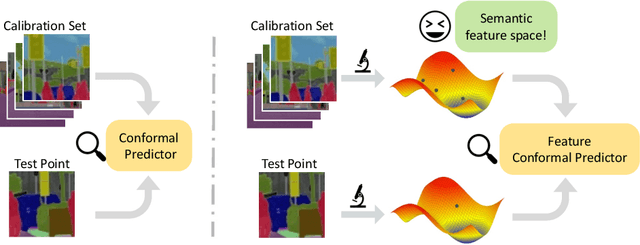

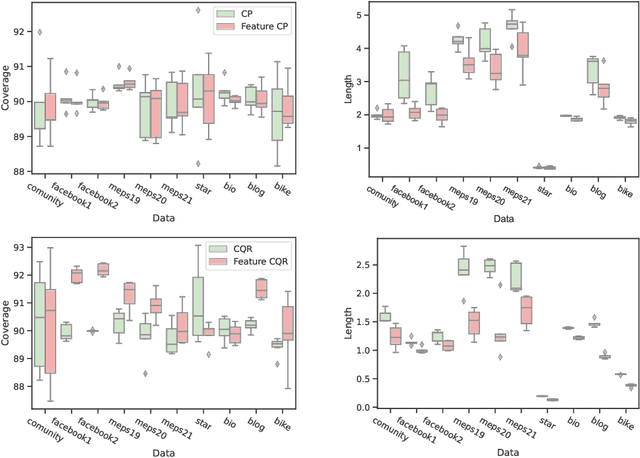
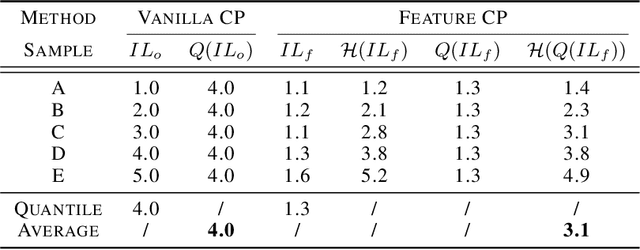
Conformal prediction is a distribution-free technique for establishing valid prediction intervals. Although conventionally people conduct conformal prediction in the output space, this is not the only possibility. In this paper, we propose feature conformal prediction, which extends the scope of conformal prediction to semantic feature spaces by leveraging the inductive bias of deep representation learning. From a theoretical perspective, we demonstrate that feature conformal prediction provably outperforms regular conformal prediction under mild assumptions. Our approach could be combined with not only vanilla conformal prediction, but also other adaptive conformal prediction methods. Experiments on various predictive inference tasks corroborate the efficacy of our method.
Learning GFlowNets from partial episodes for improved convergence and stability
Sep 30, 2022

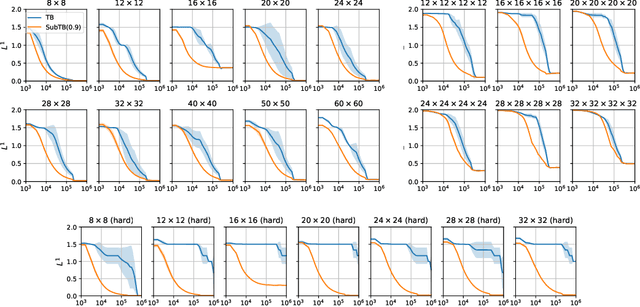
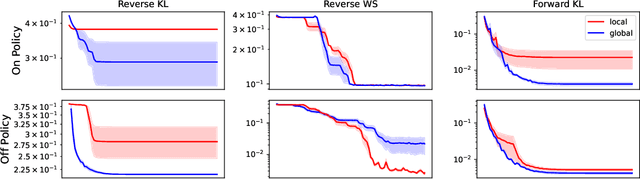
Generative flow networks (GFlowNets) are a family of algorithms for training a sequential sampler of discrete objects under an unnormalized target density and have been successfully used for various probabilistic modeling tasks. Existing training objectives for GFlowNets are either local to states or transitions, or propagate a reward signal over an entire sampling trajectory. We argue that these alternatives represent opposite ends of a gradient bias-variance tradeoff and propose a way to exploit this tradeoff to mitigate its harmful effects. Inspired by the TD($\lambda$) algorithm in reinforcement learning, we introduce subtrajectory balance or SubTB($\lambda$), a GFlowNet training objective that can learn from partial action subsequences of varying lengths. We show that SubTB($\lambda$) accelerates sampler convergence in previously studied and new environments and enables training GFlowNets in environments with longer action sequences and sparser reward landscapes than what was possible before. We also perform a comparative analysis of stochastic gradient dynamics, shedding light on the bias-variance tradeoff in GFlowNet training and the advantages of subtrajectory balance.
Graph-Based Active Machine Learning Method for Diverse and Novel Antimicrobial Peptides Generation and Selection
Sep 18, 2022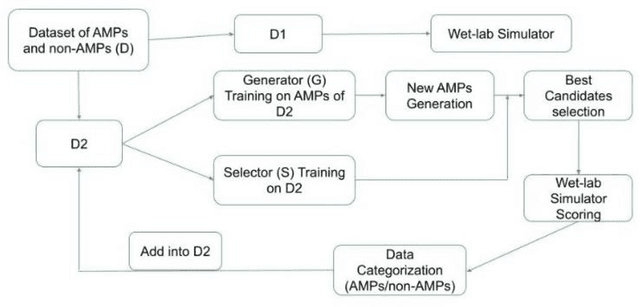

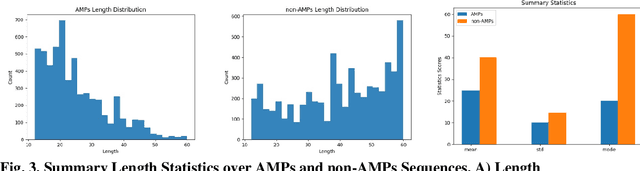
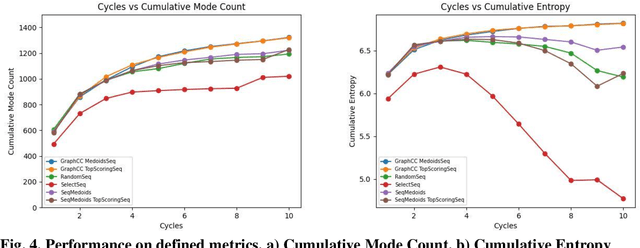
As antibiotic-resistant bacterial strains are rapidly spreading worldwide, infections caused by these strains are emerging as a global crisis causing the death of millions of people every year. Antimicrobial Peptides (AMPs) are one of the candidates to tackle this problem because of their potential diversity, and ability to favorably modulate the host immune response. However, large-scale screening of new AMP candidates is expensive, time-consuming, and now affordable in developing countries, which need the treatments the most. In this work, we propose a novel active machine learning-based framework that statistically minimizes the number of wet-lab experiments needed to design new AMPs, while ensuring a high diversity and novelty of generated AMPs sequences, in multi-rounds of wet-lab AMP screening settings. Combining recurrent neural network models and a graph-based filter (GraphCC), our proposed approach delivers novel and diverse candidates and demonstrates better performances according to our defined metrics.
Designing Biological Sequences via Meta-Reinforcement Learning and Bayesian Optimization
Sep 13, 2022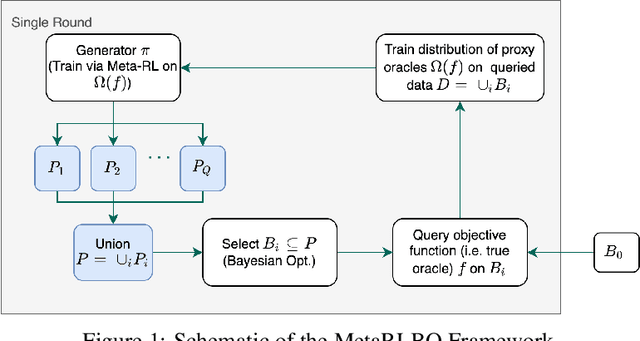
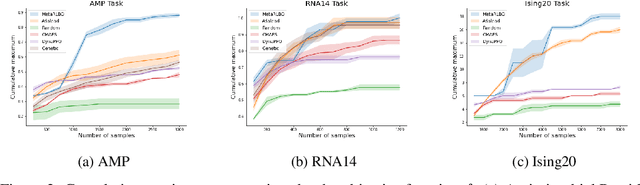
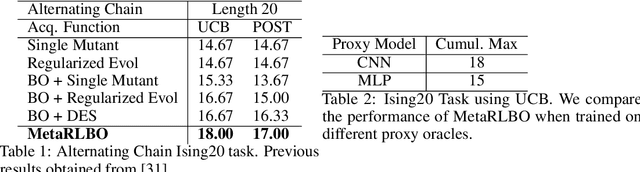
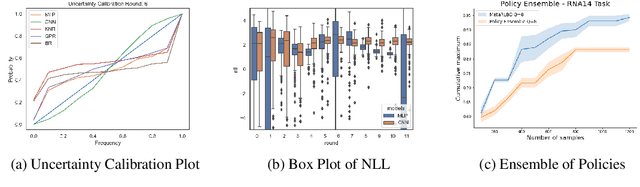
The ability to accelerate the design of biological sequences can have a substantial impact on the progress of the medical field. The problem can be framed as a global optimization problem where the objective is an expensive black-box function such that we can query large batches restricted with a limitation of a low number of rounds. Bayesian Optimization is a principled method for tackling this problem. However, the astronomically large state space of biological sequences renders brute-force iterating over all possible sequences infeasible. In this paper, we propose MetaRLBO where we train an autoregressive generative model via Meta-Reinforcement Learning to propose promising sequences for selection via Bayesian Optimization. We pose this problem as that of finding an optimal policy over a distribution of MDPs induced by sampling subsets of the data acquired in the previous rounds. Our in-silico experiments show that meta-learning over such ensembles provides robustness against reward misspecification and achieves competitive results compared to existing strong baselines.
Unifying Generative Models with GFlowNets
Sep 06, 2022There are many frameworks for deep generative modeling, each often presented with their own specific training algorithms and inference methods. We present a short note on the connections between existing deep generative models and the GFlowNet framework, shedding light on their overlapping traits and providing a unifying viewpoint through the lens of learning with Markovian trajectories. This provides a means for unifying training and inference algorithms, and provides a route to construct an agglomeration of generative models.
AI for Global Climate Cooperation: Modeling Global Climate Negotiations, Agreements, and Long-Term Cooperation in RICE-N
Aug 15, 2022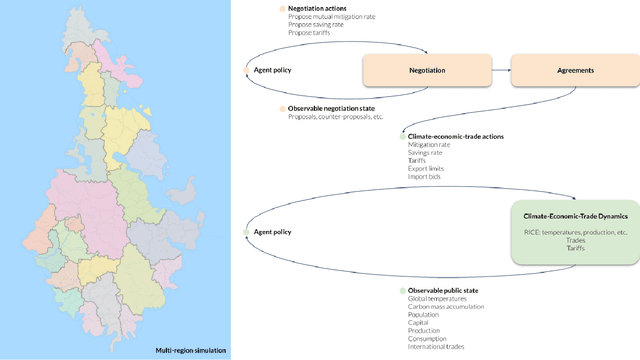
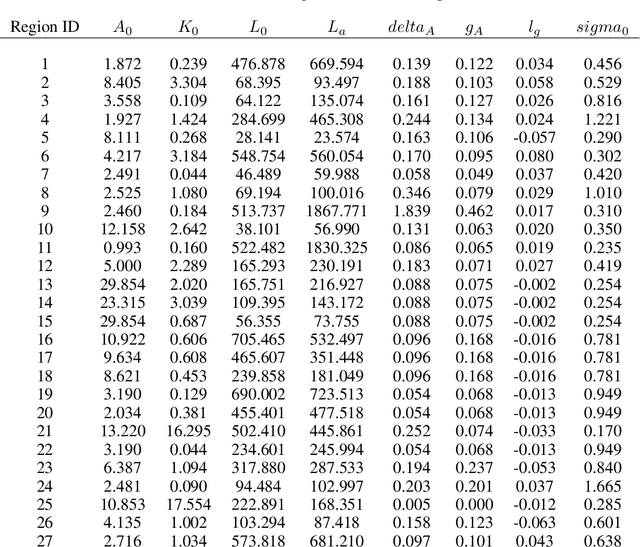
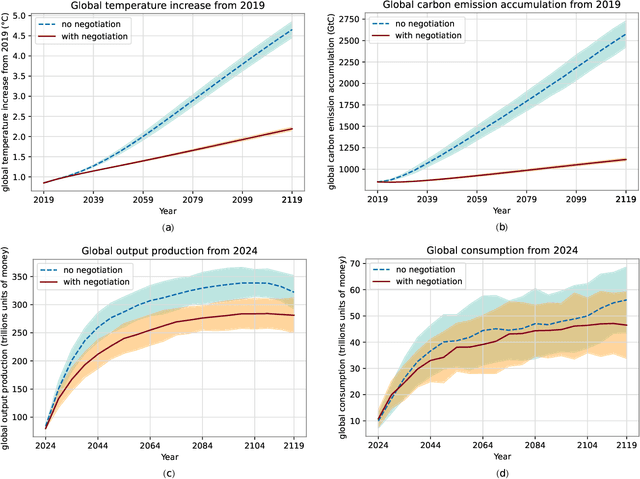

Comprehensive global cooperation is essential to limit global temperature increases while continuing economic development, e.g., reducing severe inequality or achieving long-term economic growth. Achieving long-term cooperation on climate change mitigation with n strategic agents poses a complex game-theoretic problem. For example, agents may negotiate and reach climate agreements, but there is no central authority to enforce adherence to those agreements. Hence, it is critical to design negotiation and agreement frameworks that foster cooperation, allow all agents to meet their individual policy objectives, and incentivize long-term adherence. This is an interdisciplinary challenge that calls for collaboration between researchers in machine learning, economics, climate science, law, policy, ethics, and other fields. In particular, we argue that machine learning is a critical tool to address the complexity of this domain. To facilitate this research, here we introduce RICE-N, a multi-region integrated assessment model that simulates the global climate and economy, and which can be used to design and evaluate the strategic outcomes for different negotiation and agreement frameworks. We also describe how to use multi-agent reinforcement learning to train rational agents using RICE-N. This framework underpinsAI for Global Climate Cooperation, a working group collaboration and competition on climate negotiation and agreement design. Here, we invite the scientific community to design and evaluate their solutions using RICE-N, machine learning, economic intuition, and other domain knowledge. More information can be found on www.ai4climatecoop.org.
Diversifying Design of Nucleic Acid Aptamers Using Unsupervised Machine Learning
Aug 10, 2022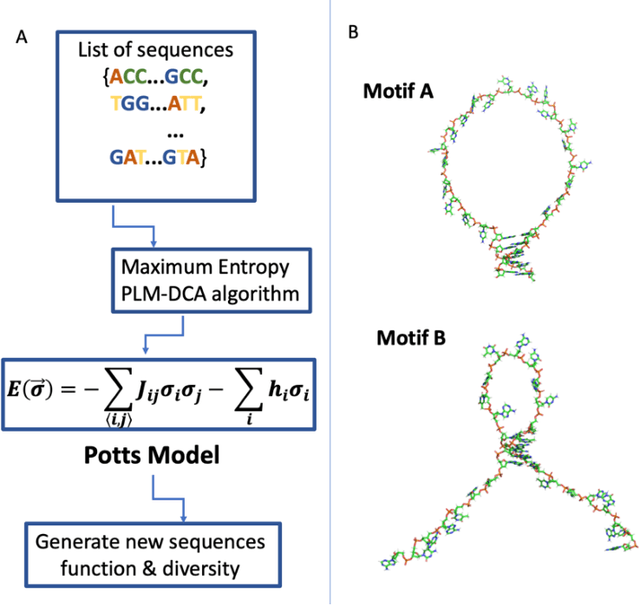
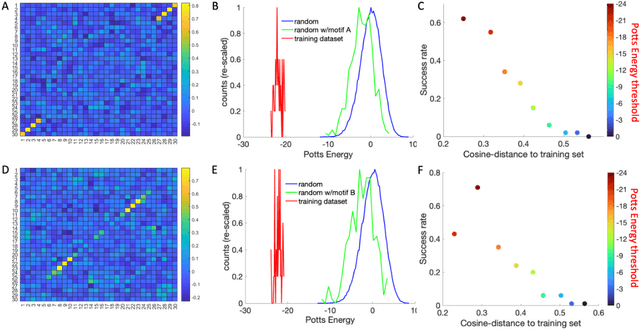
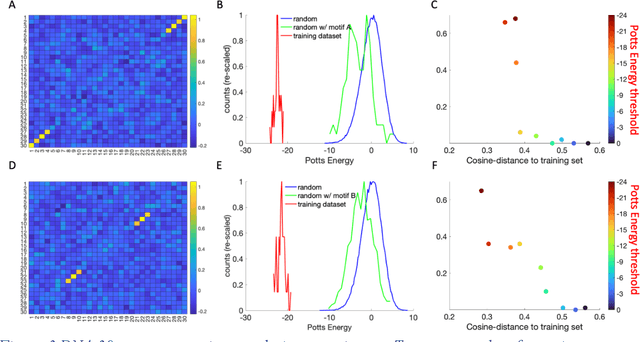
Inverse design of short single-stranded RNA and DNA sequences (aptamers) is the task of finding sequences that satisfy a set of desired criteria. Relevant criteria may be, for example, the presence of specific folding motifs, binding to molecular ligands, sensing properties, etc. Most practical approaches to aptamer design identify a small set of promising candidate sequences using high-throughput experiments (e.g. SELEX), and then optimize performance by introducing only minor modifications to the empirically found candidates. Sequences that possess the desired properties but differ drastically in chemical composition will add diversity to the search space and facilitate the discovery of useful nucleic acid aptamers. Systematic diversification protocols are needed. Here we propose to use an unsupervised machine learning model known as the Potts model to discover new, useful sequences with controllable sequence diversity. We start by training a Potts model using the maximum entropy principle on a small set of empirically identified sequences unified by a common feature. To generate new candidate sequences with a controllable degree of diversity, we take advantage of the model's spectral feature: an energy bandgap separating sequences that are similar to the training set from those that are distinct. By controlling the Potts energy range that is sampled, we generate sequences that are distinct from the training set yet still likely to have the encoded features. To demonstrate performance, we apply our approach to design diverse pools of sequences with specified secondary structure motifs in 30-mer RNA and DNA aptamers.
Controlled Sparsity via Constrained Optimization or: How I Learned to Stop Tuning Penalties and Love Constraints
Aug 08, 2022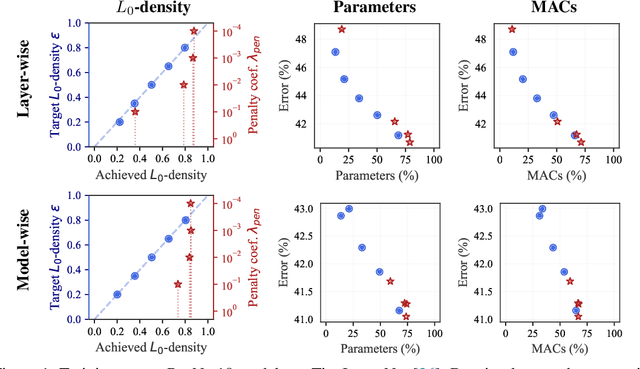

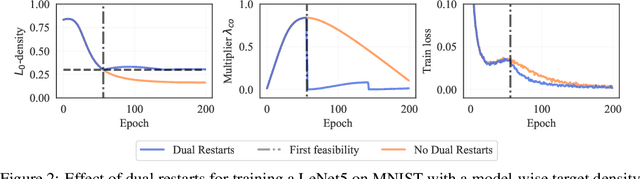
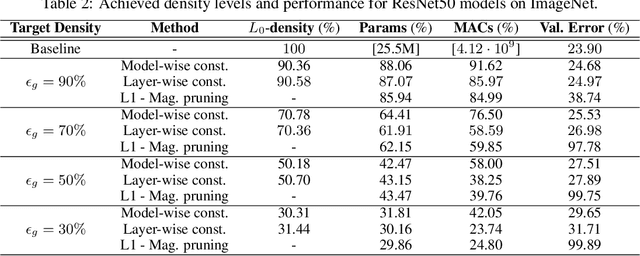
The performance of trained neural networks is robust to harsh levels of pruning. Coupled with the ever-growing size of deep learning models, this observation has motivated extensive research on learning sparse models. In this work, we focus on the task of controlling the level of sparsity when performing sparse learning. Existing methods based on sparsity-inducing penalties involve expensive trial-and-error tuning of the penalty factor, thus lacking direct control of the resulting model sparsity. In response, we adopt a constrained formulation: using the gate mechanism proposed by Louizos et al. (2018), we formulate a constrained optimization problem where sparsification is guided by the training objective and the desired sparsity target in an end-to-end fashion. Experiments on CIFAR-10/100, TinyImageNet, and ImageNet using WideResNet and ResNet{18, 50} models validate the effectiveness of our proposal and demonstrate that we can reliably achieve pre-determined sparsity targets without compromising on predictive performance.