 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Scale Logits for Temperature-Conditional GFlowNets
Oct 04, 2023GFlowNets are probabilistic models that learn a stochastic policy that sequentially generates compositional structures, such as molecular graphs. They are trained with the objective of sampling such objects with probability proportional to the object's reward. Among GFlowNets, the temperature-conditional GFlowNets represent a family of policies indexed by temperature, and each is associated with the correspondingly tempered reward function. The major benefit of temperature-conditional GFlowNets is the controllability of GFlowNets' exploration and exploitation through adjusting temperature. We propose Learning to Scale Logits for temperature-conditional GFlowNets (LSL-GFN), a novel architectural design that greatly accelerates the training of temperature-conditional GFlowNets. It is based on the idea that previously proposed temperature-conditioning approaches introduced numerical challenges in the training of the deep network because different temperatures may give rise to very different gradient profiles and ideal scales of the policy's logits. We find that the challenge is greatly reduced if a learned function of the temperature is used to scale the policy's logits directly. We empirically show that our strategy dramatically improves the performances of GFlowNets, outperforming other baselines, including reinforcement learning and sampling methods, in terms of discovering diverse modes in multiple biochemical tasks.
Discrete, compositional, and symbolic representations through attractor dynamics
Oct 03, 2023Compositionality is an important feature of discrete symbolic systems, such as language and programs, as it enables them to have infinite capacity despite a finite symbol set. It serves as a useful abstraction for reasoning in both cognitive science and in AI, yet the interface between continuous and symbolic processing is often imposed by fiat at the algorithmic level, such as by means of quantization or a softmax sampling step. In this work, we explore how discretization could be implemented in a more neurally plausible manner through the modeling of attractor dynamics that partition the continuous representation space into basins that correspond to sequences of symbols. Building on established work in attractor networks and introducing novel training methods, we show that imposing structure in the symbolic space can produce compositionality in the attractor-supported representation space of rich sensory inputs. Lastly, we argue that our model exhibits the process of an information bottleneck that is thought to play a role in conscious experience, decomposing the rich information of a sensory input into stable components encoding symbolic information.
Leveraging Diffusion Disentangled Representations to Mitigate Shortcuts in Underspecified Visual Tasks
Oct 03, 2023



Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to shortcut learning phenomena, where a model may rely on erroneous, easy-to-learn, cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting the generation of synthetic counterfactuals using Diffusion Probabilistic Models (DPMs). We discover that DPMs have the inherent capability to represent multiple visual cues independently, even when they are largely correlated in the training data. We leverage this characteristic to encourage model diversity and empirically show the efficacy of the approach with respect to several diversification objectives. We show that diffusion-guided diversification can lead models to avert attention from shortcut cues, achieving ensemble diversity performance comparable to previous methods requiring additional data collection.
Delta-AI: Local objectives for amortized inference in sparse graphical models
Oct 03, 2023



We present a new algorithm for amortized inference in sparse probabilistic graphical models (PGMs), which we call $\Delta$-amortized inference ($\Delta$-AI). Our approach is based on the observation that when the sampling of variables in a PGM is seen as a sequence of actions taken by an agent, sparsity of the PGM enables local credit assignment in the agent's policy learning objective. This yields a local constraint that can be turned into a local loss in the style of generative flow networks (GFlowNets) that enables off-policy training but avoids the need to instantiate all the random variables for each parameter update, thus speeding up training considerably. The $\Delta$-AI objective matches the conditional distribution of a variable given its Markov blanket in a tractable learned sampler, which has the structure of a Bayesian network, with the same conditional distribution under the target PGM. As such, the trained sampler recovers marginals and conditional distributions of interest and enables inference of partial subsets of variables. We illustrate $\Delta$-AI's effectiveness for sampling from synthetic PGMs and training latent variable models with sparse factor structure.
Combining Spatial and Temporal Abstraction in Planning for Better Generalization
Sep 30, 2023



Inspired by human conscious planning, we propose Skipper, a model-based reinforcement learning agent that utilizes spatial and temporal abstractions to generalize learned skills in novel situations. It automatically decomposes the task at hand into smaller-scale, more manageable subtasks and hence enables sparse decision-making and focuses its computation on the relevant parts of the environment. This relies on the definition of a high-level proxy problem represented as a directed graph, in which vertices and edges are learned end-to-end using hindsight. Our theoretical analyses provide performance guarantees under appropriate assumptions and establish where our approach is expected to be helpful. Generalization-focused experiments validate Skipper's significant advantage in zero-shot generalization, compared to existing state-of-the-art hierarchical planning methods.
Tree Cross Attention
Sep 29, 2023



Cross Attention is a popular method for retrieving information from a set of context tokens for making predictions. At inference time, for each prediction, Cross Attention scans the full set of $\mathcal{O}(N)$ tokens. In practice, however, often only a small subset of tokens are required for good performance. Methods such as Perceiver IO are cheap at inference as they distill the information to a smaller-sized set of latent tokens $L < N$ on which cross attention is then applied, resulting in only $\mathcal{O}(L)$ complexity. However, in practice, as the number of input tokens and the amount of information to distill increases, the number of latent tokens needed also increases significantly. In this work, we propose Tree Cross Attention (TCA) - a module based on Cross Attention that only retrieves information from a logarithmic $\mathcal{O}(\log(N))$ number of tokens for performing inference. TCA organizes the data in a tree structure and performs a tree search at inference time to retrieve the relevant tokens for prediction. Leveraging TCA, we introduce ReTreever, a flexible architecture for token-efficient inference. We show empirically that Tree Cross Attention (TCA) performs comparable to Cross Attention across various classification and uncertainty regression tasks while being significantly more token-efficient. Furthermore, we compare ReTreever against Perceiver IO, showing significant gains while using the same number of tokens for inference.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023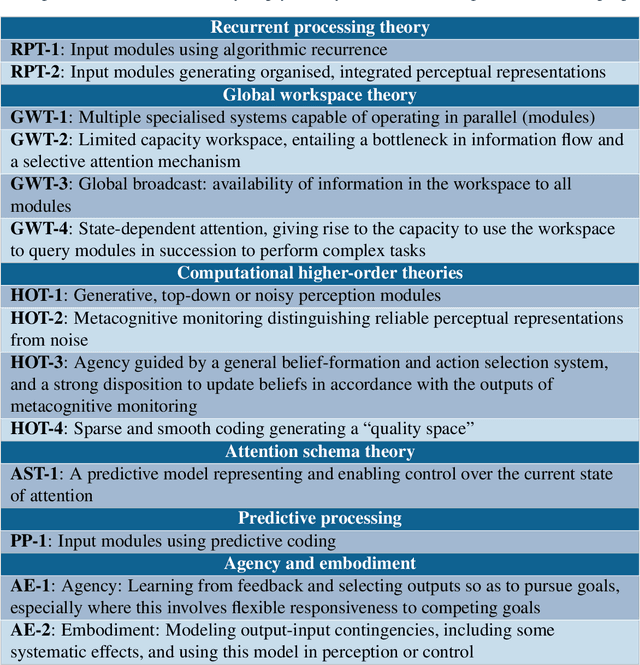
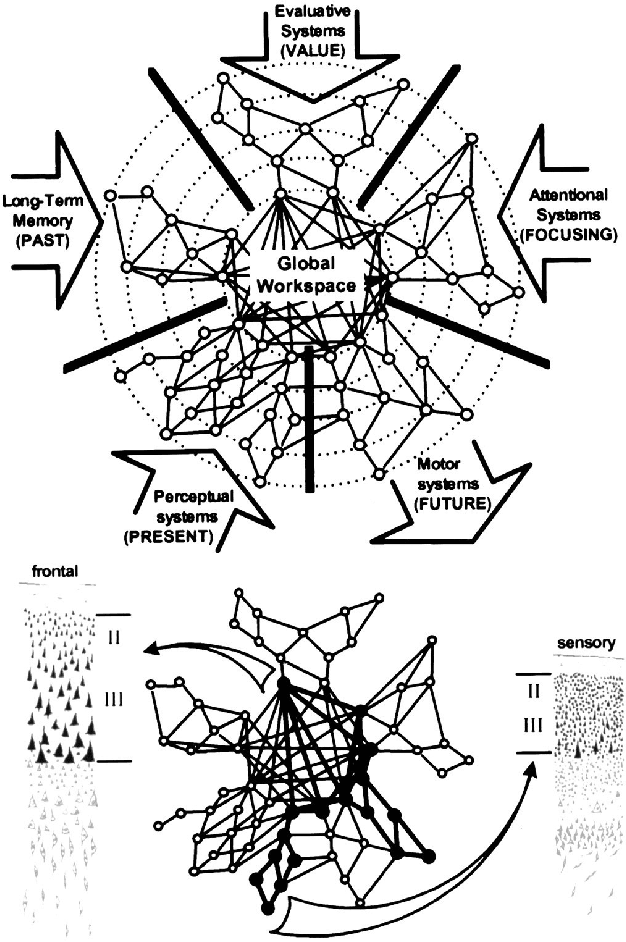
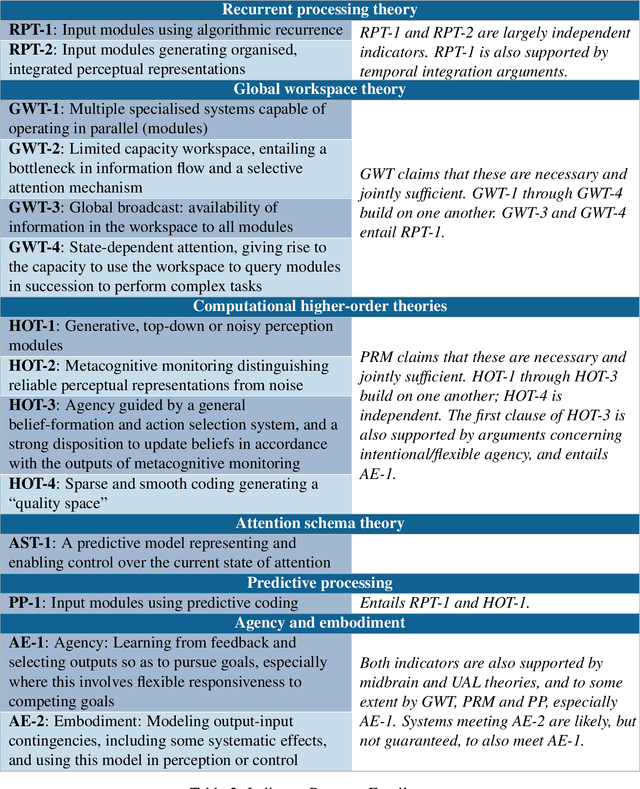
Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
Benchmarking Bayesian Causal Discovery Methods for Downstream Treatment Effect Estimation
Jul 30, 2023



The practical utility of causality in decision-making is widespread and brought about by the intertwining of causal discovery and causal inference. Nevertheless, a notable gap exists in the evaluation of causal discovery methods, where insufficient emphasis is placed on downstream inference. To address this gap, we evaluate seven established baseline causal discovery methods including a newly proposed method based on GFlowNets, on the downstream task of treatment effect estimation. Through the implementation of a distribution-level evaluation, we offer valuable and unique insights into the efficacy of these causal discovery methods for treatment effect estimation, considering both synthetic and real-world scenarios, as well as low-data scenarios. The results of our study demonstrate that some of the algorithms studied are able to effectively capture a wide range of useful and diverse ATE modes, while some tend to learn many low-probability modes which impacts the (unrelaxed) recall and precision.
AI For Global Climate Cooperation 2023 Competition Proceedings
Jul 10, 2023The international community must collaborate to mitigate climate change and sustain economic growth. However, collaboration is hard to achieve, partly because no global authority can ensure compliance with international climate agreements. Combining AI with climate-economic simulations offers a promising solution to design international frameworks, including negotiation protocols and climate agreements, that promote and incentivize collaboration. In addition, these frameworks should also have policy goals fulfillment, and sustained commitment, taking into account climate-economic dynamics and strategic behaviors. These challenges require an interdisciplinary approach across machine learning, economics, climate science, law, policy, ethics, and other fields. Towards this objective, we organized AI for Global Climate Cooperation, a Mila competition in which teams submitted proposals and analyses of international frameworks, based on (modifications of) RICE-N, an AI-driven integrated assessment model (IAM). In particular, RICE-N supports modeling regional decision-making using AI agents. Furthermore, the IAM then models the climate-economic impact of those decisions into the future. Whereas the first track focused only on performance metrics, the proposals submitted to the second track were evaluated both quantitatively and qualitatively. The quantitative evaluation focused on a combination of (i) the degree of mitigation of global temperature rise and (ii) the increase in economic productivity. On the other hand, an interdisciplinary panel of human experts in law, policy, sociology, economics and environmental science, evaluated the solutions qualitatively. In particular, the panel considered the effectiveness, simplicity, feasibility, ethics, and notions of climate justice of the protocols. In the third track, the participants were asked to critique and improve RICE-N.
Simulation-free Schrödinger bridges via score and flow matching
Jul 07, 2023We present simulation-free score and flow matching ([SF]$^2$M), a simulation-free objective for inferring stochastic dynamics given unpaired source and target samples drawn from arbitrary distributions. Our method generalizes both the score-matching loss used in the training of diffusion models and the recently proposed flow matching loss used in the training of continuous normalizing flows. [SF]$^2$M interprets continuous-time stochastic generative modeling as a Schr\"odinger bridge (SB) problem. It relies on static entropy-regularized optimal transport, or a minibatch approximation, to efficiently learn the SB without simulating the learned stochastic process. We find that [SF]$^2$M is more efficient and gives more accurate solutions to the SB problem than simulation-based methods from prior work. Finally, we apply [SF]$^2$M to the problem of learning cell dynamics from snapshot data. Notably, [SF]$^2$M is the first method to accurately model cell dynamics in high dimensions and can recover known gene regulatory networks from simulated data.