 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
SSVP: Synergistic Semantic-Visual Prompting for Industrial Zero-Shot Anomaly Detection
Jan 14, 2026Zero-Shot Anomaly Detection (ZSAD) leverages Vision-Language Models (VLMs) to enable supervision-free industrial inspection. However, existing ZSAD paradigms are constrained by single visual backbones, which struggle to balance global semantic generalization with fine-grained structural discriminability. To bridge this gap, we propose Synergistic Semantic-Visual Prompting (SSVP), that efficiently fuses diverse visual encodings to elevate model's fine-grained perception. Specifically, SSVP introduces the Hierarchical Semantic-Visual Synergy (HSVS) mechanism, which deeply integrates DINOv3's multi-scale structural priors into the CLIP semantic space. Subsequently, the Vision-Conditioned Prompt Generator (VCPG) employs cross-modal attention to guide dynamic prompt generation, enabling linguistic queries to precisely anchor to specific anomaly patterns. Furthermore, to address the discrepancy between global scoring and local evidence, the Visual-Text Anomaly Mapper (VTAM) establishes a dual-gated calibration paradigm. Extensive evaluations on seven industrial benchmarks validate the robustness of our method; SSVP achieves state-of-the-art performance with 93.0\% Image-AUROC and 92.2\% Pixel-AUROC on MVTec-AD, significantly outperforming existing zero-shot approaches.
Density-Adaptive Kernel based Re-Ranking for Person Re-Identification
May 20, 2018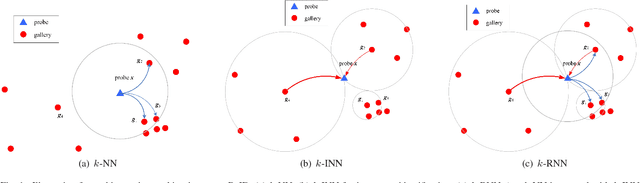
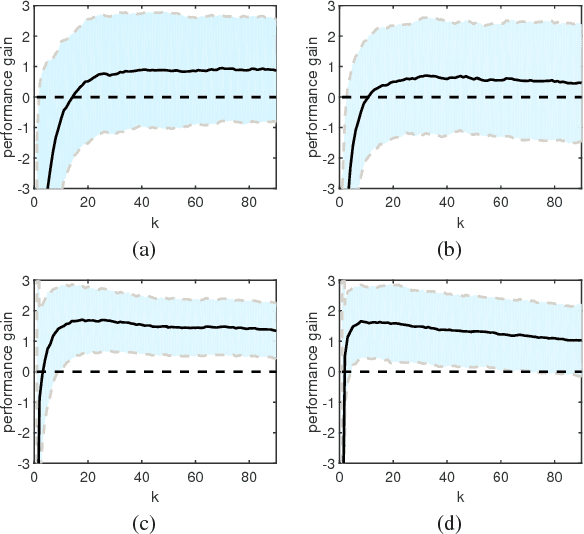
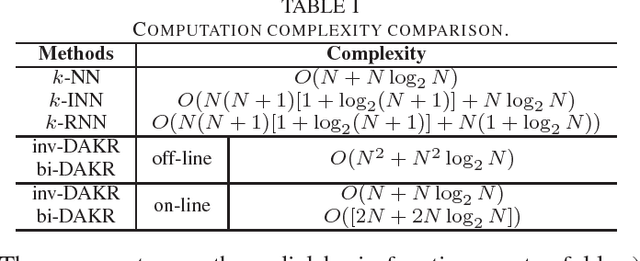
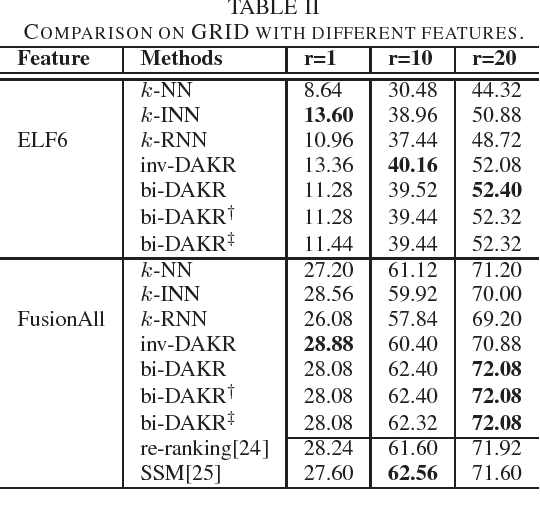
Person Re-Identification (ReID) refers to the task of verifying the identity of a pedestrian observed from non-overlapping surveillance cameras views. Recently, it has been validated that re-ranking could bring extra performance improvements in person ReID. However, the current re-ranking approaches either require feedbacks from users or suffer from burdensome computation cost. In this paper, we propose to exploit a density-adaptive kernel technique to perform efficient and effective re-ranking for person ReID. Specifically, we present two simple yet effective re-ranking methods, termed inverse Density-Adaptive Kernel based Re-ranking (inv-DAKR) and bidirectional Density-Adaptive Kernel based Re-ranking (bi-DAKR), which are based on a smooth kernel function with a density-adaptive parameter. Experiments on six benchmark data sets confirm that our proposals are effective and efficient.