 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTTNet: Improving Video Shadow Detection via Dark-Aware Guidance and Tokenized Temporal Modeling
Nov 10, 2025Video shadow detection confronts two entwined difficulties: distinguishing shadows from complex backgrounds and modeling dynamic shadow deformations under varying illumination. To address shadow-background ambiguity, we leverage linguistic priors through the proposed Vision-language Match Module (VMM) and a Dark-aware Semantic Block (DSB), extracting text-guided features to explicitly differentiate shadows from dark objects. Furthermore, we introduce adaptive mask reweighting to downweight penumbra regions during training and apply edge masks at the final decoder stage for better supervision. For temporal modeling of variable shadow shapes, we propose a Tokenized Temporal Block (TTB) that decouples spatiotemporal learning. TTB summarizes cross-frame shadow semantics into learnable temporal tokens, enabling efficient sequence encoding with minimal computation overhead. Comprehensive Experiments on multiple benchmark datasets demonstrate state-of-the-art accuracy and real-time inference efficiency. Codes are available at https://github.com/city-cheng/DTTNet.
MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution
Jun 17, 2025
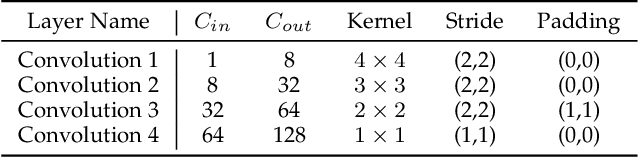


Facial micro-expression recognition (MER) is a challenging problem, due to transient and subtle micro-expression (ME) actions. Most existing methods depend on hand-crafted features, key frames like onset, apex, and offset frames, or deep networks limited by small-scale and low-diversity datasets. In this paper, we propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data. Extensive experiments demonstrate that our framework (i) outperforms the state-of-the-art MER methods on CASME II, SAMM, and SMIC benchmarks, (ii) works well for optical flow estimation and facial landmark detection, and (iii) can capture facial subtle muscle actions in local regions associated with MEs. The code is available at https://github.com/CYF-cuber/MOL.
Modality-Guided Dynamic Graph Fusion and Temporal Diffusion for Self-Supervised RGB-T Tracking
May 06, 2025To reduce the reliance on large-scale annotations, self-supervised RGB-T tracking approaches have garnered significant attention. However, the omission of the object region by erroneous pseudo-label or the introduction of background noise affects the efficiency of modality fusion, while pseudo-label noise triggered by similar object noise can further affect the tracking performance. In this paper, we propose GDSTrack, a novel approach that introduces dynamic graph fusion and temporal diffusion to address the above challenges in self-supervised RGB-T tracking. GDSTrack dynamically fuses the modalities of neighboring frames, treats them as distractor noise, and leverages the denoising capability of a generative model. Specifically, by constructing an adjacency matrix via an Adjacency Matrix Generator (AMG), the proposed Modality-guided Dynamic Graph Fusion (MDGF) module uses a dynamic adjacency matrix to guide graph attention, focusing on and fusing the object's coherent regions. Temporal Graph-Informed Diffusion (TGID) models MDGF features from neighboring frames as interference, and thus improving robustness against similar-object noise. Extensive experiments conducted on four public RGB-T tracking datasets demonstrate that GDSTrack outperforms the existing state-of-the-art methods. The source code is available at https://github.com/LiShenglana/GDSTrack.
Edge Large AI Models: Revolutionizing 6G Networks
May 01, 2025Large artificial intelligence models (LAMs) possess human-like abilities to solve a wide range of real-world problems, exemplifying the potential of experts in various domains and modalities. By leveraging the communication and computation capabilities of geographically dispersed edge devices, edge LAM emerges as an enabling technology to empower the delivery of various real-time intelligent services in 6G. Unlike traditional edge artificial intelligence (AI) that primarily supports a single task using small models, edge LAM is featured by the need of the decomposition and distributed deployment of large models, and the ability to support highly generalized and diverse tasks. However, due to limited communication, computation, and storage resources over wireless networks, the vast number of trainable neurons and the substantial communication overhead pose a formidable hurdle to the practical deployment of edge LAMs. In this paper, we investigate the opportunities and challenges of edge LAMs from the perspectives of model decomposition and resource management. Specifically, we propose collaborative fine-tuning and full-parameter training frameworks, alongside a microservice-assisted inference architecture, to enhance the deployment of edge LAM over wireless networks. Additionally, we investigate the application of edge LAM in air-interface designs, focusing on channel prediction and beamforming. These innovative frameworks and applications offer valuable insights and solutions for advancing 6G technology.
Structured IB: Improving Information Bottleneck with Structured Feature Learning
Dec 11, 2024The Information Bottleneck (IB) principle has emerged as a promising approach for enhancing the generalization, robustness, and interpretability of deep neural networks, demonstrating efficacy across image segmentation, document clustering, and semantic communication. Among IB implementations, the IB Lagrangian method, employing Lagrangian multipliers, is widely adopted. While numerous methods for the optimizations of IB Lagrangian based on variational bounds and neural estimators are feasible, their performance is highly dependent on the quality of their design, which is inherently prone to errors. To address this limitation, we introduce Structured IB, a framework for investigating potential structured features. By incorporating auxiliary encoders to extract missing informative features, we generate more informative representations. Our experiments demonstrate superior prediction accuracy and task-relevant information preservation compared to the original IB Lagrangian method, even with reduced network size.
Facial Action Unit Detection by Adaptively Constraining Self-Attention and Causally Deconfounding Sample
Oct 02, 2024Facial action unit (AU) detection remains a challenging task, due to the subtlety, dynamics, and diversity of AUs. Recently, the prevailing techniques of self-attention and causal inference have been introduced to AU detection. However, most existing methods directly learn self-attention guided by AU detection, or employ common patterns for all AUs during causal intervention. The former often captures irrelevant information in a global range, and the latter ignores the specific causal characteristic of each AU. In this paper, we propose a novel AU detection framework called AC2D by adaptively constraining self-attention weight distribution and causally deconfounding the sample confounder. Specifically, we explore the mechanism of self-attention weight distribution, in which the self-attention weight distribution of each AU is regarded as spatial distribution and is adaptively learned under the constraint of location-predefined attention and the guidance of AU detection. Moreover, we propose a causal intervention module for each AU, in which the bias caused by training samples and the interference from irrelevant AUs are both suppressed. Extensive experiments show that our method achieves competitive performance compared to state-of-the-art AU detection approaches on challenging benchmarks, including BP4D, DISFA, GFT, and BP4D+ in constrained scenarios and Aff-Wild2 in unconstrained scenarios. The code is available at https://github.com/ZhiwenShao/AC2D.
OrientedFormer: An End-to-End Transformer-Based Oriented Object Detector in Remote Sensing Images
Sep 29, 2024Oriented object detection in remote sensing images is a challenging task due to objects being distributed in multi-orientation. Recently, end-to-end transformer-based methods have achieved success by eliminating the need for post-processing operators compared to traditional CNN-based methods. However, directly extending transformers to oriented object detection presents three main issues: 1) objects rotate arbitrarily, necessitating the encoding of angles along with position and size; 2) the geometric relations of oriented objects are lacking in self-attention, due to the absence of interaction between content and positional queries; and 3) oriented objects cause misalignment, mainly between values and positional queries in cross-attention, making accurate classification and localization difficult. In this paper, we propose an end-to-end transformer-based oriented object detector, consisting of three dedicated modules to address these issues. First, Gaussian positional encoding is proposed to encode the angle, position, and size of oriented boxes using Gaussian distributions. Second, Wasserstein self-attention is proposed to introduce geometric relations and facilitate interaction between content and positional queries by utilizing Gaussian Wasserstein distance scores. Third, oriented cross-attention is proposed to align values and positional queries by rotating sampling points around the positional query according to their angles. Experiments on six datasets DIOR-R, a series of DOTA, HRSC2016 and ICDAR2015 show the effectiveness of our approach. Compared with previous end-to-end detectors, the OrientedFormer gains 1.16 and 1.21 AP$_{50}$ on DIOR-R and DOTA-v1.0 respectively, while reducing training epochs from 3$\times$ to 1$\times$. The codes are available at https://github.com/wokaikaixinxin/OrientedFormer.
Hierarchical Learning and Computing over Space-Ground Integrated Networks
Aug 26, 2024



Space-ground integrated networks hold great promise for providing global connectivity, particularly in remote areas where large amounts of valuable data are generated by Internet of Things (IoT) devices, but lacking terrestrial communication infrastructure. The massive data is conventionally transferred to the cloud server for centralized artificial intelligence (AI) models training, raising huge communication overhead and privacy concerns. To address this, we propose a hierarchical learning and computing framework, which leverages the lowlatency characteristic of low-earth-orbit (LEO) satellites and the global coverage of geostationary-earth-orbit (GEO) satellites, to provide global aggregation services for locally trained models on ground IoT devices. Due to the time-varying nature of satellite network topology and the energy constraints of LEO satellites, efficiently aggregating the received local models from ground devices on LEO satellites is highly challenging. By leveraging the predictability of inter-satellite connectivity, modeling the space network as a directed graph, we formulate a network energy minimization problem for model aggregation, which turns out to be a Directed Steiner Tree (DST) problem. We propose a topologyaware energy-efficient routing (TAEER) algorithm to solve the DST problem by finding a minimum spanning arborescence on a substitute directed graph. Extensive simulations under realworld space-ground integrated network settings demonstrate that the proposed TAEER algorithm significantly reduces energy consumption and outperforms benchmarks.
A Survey on Integrated Sensing, Communication, and Computation
Aug 15, 2024



The forthcoming generation of wireless technology, 6G, promises a revolutionary leap beyond traditional data-centric services. It aims to usher in an era of ubiquitous intelligent services, where everything is interconnected and intelligent. This vision requires the seamless integration of three fundamental modules: Sensing for information acquisition, communication for information sharing, and computation for information processing and decision-making. These modules are intricately linked, especially in complex tasks such as edge learning and inference. However, the performance of these modules is interdependent, creating a resource competition for time, energy, and bandwidth. Existing techniques like integrated communication and computation (ICC), integrated sensing and computation (ISC), and integrated sensing and communication (ISAC) have made partial strides in addressing this challenge, but they fall short of meeting the extreme performance requirements. To overcome these limitations, it is essential to develop new techniques that comprehensively integrate sensing, communication, and computation. This integrated approach, known as Integrated Sensing, Communication, and Computation (ISCC), offers a systematic perspective for enhancing task performance. This paper begins with a comprehensive survey of historic and related techniques such as ICC, ISC, and ISAC, highlighting their strengths and limitations. It then explores the state-of-the-art signal designs for ISCC, along with network resource management strategies specifically tailored for ISCC. Furthermore, this paper discusses the exciting research opportunities that lie ahead for implementing ISCC in future advanced networks. By embracing ISCC, we can unlock the full potential of intelligent connectivity, paving the way for groundbreaking applications and services.
GMM-ResNext: Combining Generative and Discriminative Models for Speaker Verification
Jul 03, 2024With the development of deep learning, many different network architectures have been explored in speaker verification. However, most network architectures rely on a single deep learning architecture, and hybrid networks combining different architectures have been little studied in ASV tasks. In this paper, we propose the GMM-ResNext model for speaker verification. Conventional GMM does not consider the score distribution of each frame feature over all Gaussian components and ignores the relationship between neighboring speech frames. So, we extract the log Gaussian probability features based on the raw acoustic features and use ResNext-based network as the backbone to extract the speaker embedding. GMM-ResNext combines Generative and Discriminative Models to improve the generalization ability of deep learning models and allows one to more easily specify meaningful priors on model parameters. A two-path GMM-ResNext model based on two gender-related GMMs has also been proposed. The Experimental results show that the proposed GMM-ResNext achieves relative improvements of 48.1\% and 11.3\% in EER compared with ResNet34 and ECAPA-TDNN on VoxCeleb1-O test set.