 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplex Behavioral Relation Learning for Recommendation via Memory Augmented Transformer Network
Oct 08, 2021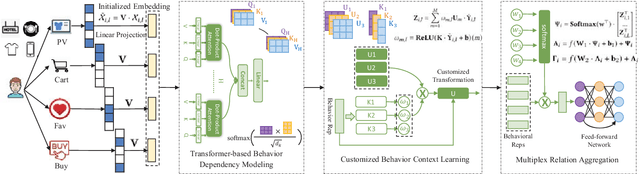

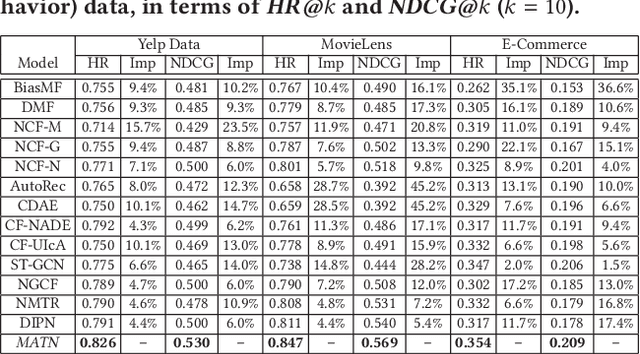
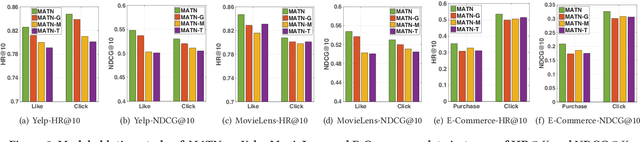
Capturing users' precise preferences is of great importance in various recommender systems (eg., e-commerce platforms), which is the basis of how to present personalized interesting product lists to individual users. In spite of significant progress has been made to consider relations between users and items, most of the existing recommendation techniques solely focus on singular type of user-item interactions. However, user-item interactive behavior is often exhibited with multi-type (e.g., page view, add-to-favorite and purchase) and inter-dependent in nature. The overlook of multiplex behavior relations can hardly recognize the multi-modal contextual signals across different types of interactions, which limit the feasibility of current recommendation methods. To tackle the above challenge, this work proposes a Memory-Augmented Transformer Networks (MATN), to enable the recommendation with multiplex behavioral relational information, and joint modeling of type-specific behavioral context and type-wise behavior inter-dependencies, in a fully automatic manner. In our MATN framework, we first develop a transformer-based multi-behavior relation encoder, to make the learned interaction representations be reflective of the cross-type behavior relations. Furthermore, a memory attention network is proposed to supercharge MATN capturing the contextual signals of different types of behavior into the category-specific latent embedding space. Finally, a cross-behavior aggregation component is introduced to promote the comprehensive collaboration across type-aware interaction behavior representations, and discriminate their inherent contributions in assisting recommendations. Extensive experiments on two benchmark datasets and a real-world e-commence user behavior data demonstrate significant improvements obtained by MATN over baselines. Codes are available at: https://github.com/akaxlh/MATN.
Knowledge-Enhanced Hierarchical Graph Transformer Network for Multi-Behavior Recommendation
Oct 08, 2021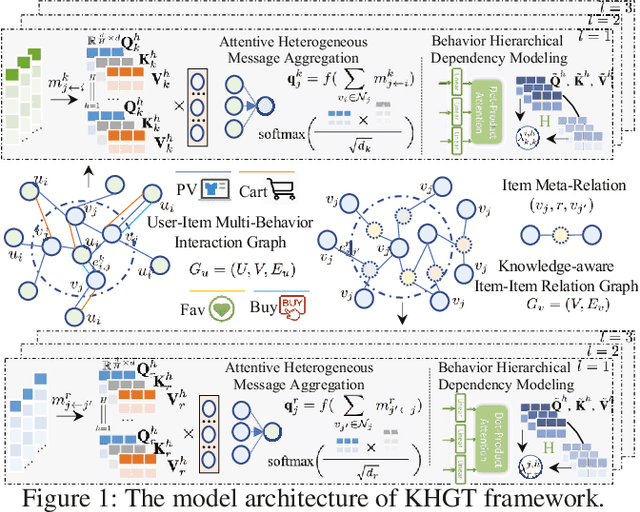

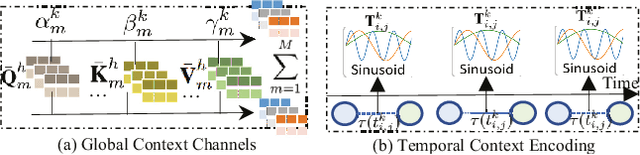
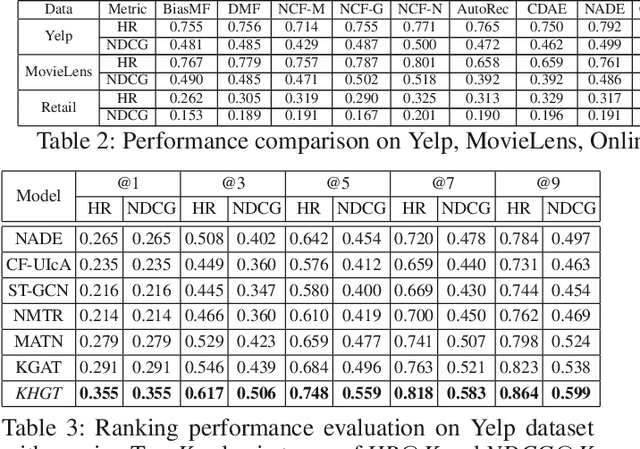
Accurate user and item embedding learning is crucial for modern recommender systems. However, most existing recommendation techniques have thus far focused on modeling users' preferences over singular type of user-item interactions. Many practical recommendation scenarios involve multi-typed user interactive behaviors (e.g., page view, add-to-favorite and purchase), which presents unique challenges that cannot be handled by current recommendation solutions. In particular: i) complex inter-dependencies across different types of user behaviors; ii) the incorporation of knowledge-aware item relations into the multi-behavior recommendation framework; iii) dynamic characteristics of multi-typed user-item interactions. To tackle these challenges, this work proposes a Knowledge-Enhanced Hierarchical Graph Transformer Network (KHGT), to investigate multi-typed interactive patterns between users and items in recommender systems. Specifically, KHGT is built upon a graph-structured neural architecture to i) capture type-specific behavior characteristics; ii) explicitly discriminate which types of user-item interactions are more important in assisting the forecasting task on the target behavior. Additionally, we further integrate the graph attention layer with the temporal encoding strategy, to empower the learned embeddings be reflective of both dedicated multiplex user-item and item-item relations, as well as the underlying interaction dynamics. Extensive experiments conducted on three real-world datasets show that KHGT consistently outperforms many state-of-the-art recommendation methods across various evaluation settings. Our implementation code is available at https://github.com/akaxlh/KHGT.
Graph-Enhanced Multi-Task Learning of Multi-Level Transition Dynamics for Session-based Recommendation
Oct 08, 2021

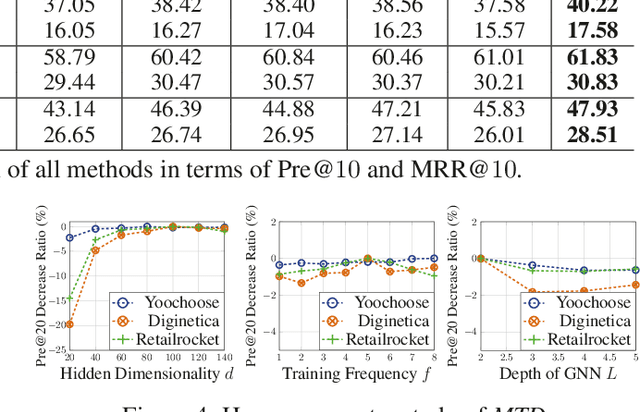
Session-based recommendation plays a central role in a wide spectrum of online applications, ranging from e-commerce to online advertising services. However, the majority of existing session-based recommendation techniques (e.g., attention-based recurrent network or graph neural network) are not well-designed for capturing the complex transition dynamics exhibited with temporally-ordered and multi-level inter-dependent relation structures. These methods largely overlook the relation hierarchy of item transitional patterns. In this paper, we propose a multi-task learning framework with Multi-level Transition Dynamics (MTD), which enables the jointly learning of intra- and inter-session item transition dynamics in automatic and hierarchical manner. Towards this end, we first develop a position-aware attention mechanism to learn item transitional regularities within individual session. Then, a graph-structured hierarchical relation encoder is proposed to explicitly capture the cross-session item transitions in the form of high-order connectivities by performing embedding propagation with the global graph context. The learning process of intra- and inter-session transition dynamics are integrated, to preserve the underlying low- and high-level item relationships in a common latent space. Extensive experiments on three real-world datasets demonstrate the superiority of MTD as compared to state-of-the-art baselines.
Knowledge-aware Coupled Graph Neural Network for Social Recommendation
Oct 08, 2021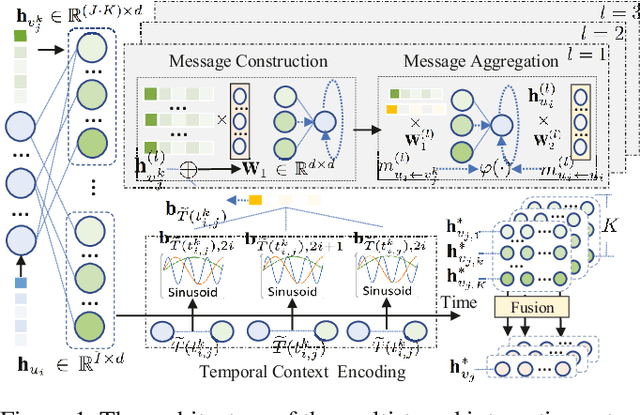

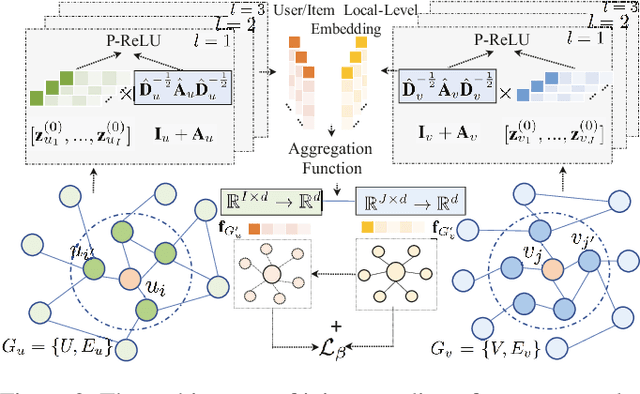

Social recommendation task aims to predict users' preferences over items with the incorporation of social connections among users, so as to alleviate the sparse issue of collaborative filtering. While many recent efforts show the effectiveness of neural network-based social recommender systems, several important challenges have not been well addressed yet: (i) The majority of models only consider users' social connections, while ignoring the inter-dependent knowledge across items; (ii) Most of existing solutions are designed for singular type of user-item interactions, making them infeasible to capture the interaction heterogeneity; (iii) The dynamic nature of user-item interactions has been less explored in many social-aware recommendation techniques. To tackle the above challenges, this work proposes a Knowledge-aware Coupled Graph Neural Network (KCGN) that jointly injects the inter-dependent knowledge across items and users into the recommendation framework. KCGN enables the high-order user- and item-wise relation encoding by exploiting the mutual information for global graph structure awareness. Additionally, we further augment KCGN with the capability of capturing dynamic multi-typed user-item interactive patterns. Experimental studies on real-world datasets show the effectiveness of our method against many strong baselines in a variety of settings. Source codes are available at: https://github.com/xhcdream/KCGN.
Graph Meta Network for Multi-Behavior Recommendation
Oct 08, 2021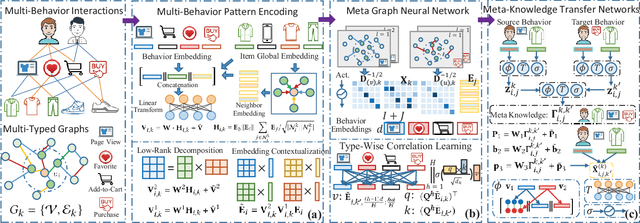

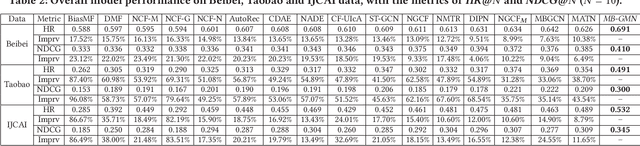
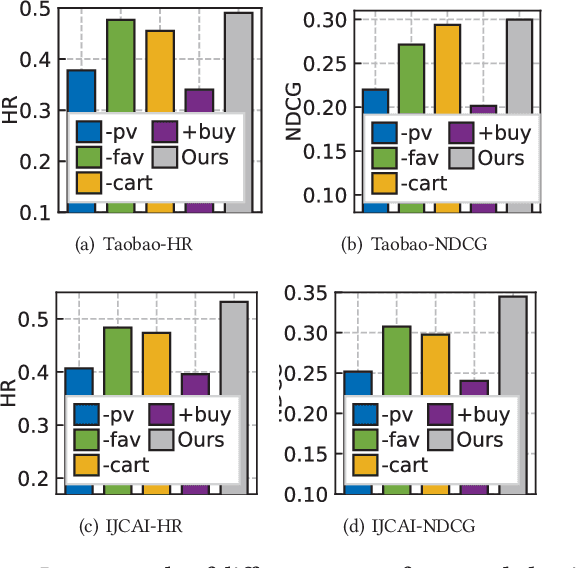
Modern recommender systems often embed users and items into low-dimensional latent representations, based on their observed interactions. In practical recommendation scenarios, users often exhibit various intents which drive them to interact with items with multiple behavior types (e.g., click, tag-as-favorite, purchase). However, the diversity of user behaviors is ignored in most of the existing approaches, which makes them difficult to capture heterogeneous relational structures across different types of interactive behaviors. Exploring multi-typed behavior patterns is of great importance to recommendation systems, yet is very challenging because of two aspects: i) The complex dependencies across different types of user-item interactions; ii) Diversity of such multi-behavior patterns may vary by users due to their personalized preference. To tackle the above challenges, we propose a Multi-Behavior recommendation framework with Graph Meta Network to incorporate the multi-behavior pattern modeling into a meta-learning paradigm. Our developed MB-GMN empowers the user-item interaction learning with the capability of uncovering type-dependent behavior representations, which automatically distills the behavior heterogeneity and interaction diversity for recommendations. Extensive experiments on three real-world datasets show the effectiveness of MB-GMN by significantly boosting the recommendation performance as compared to various state-of-the-art baselines. The source code is available athttps://github.com/akaxlh/MB-GMN.
Social Recommendation with Self-Supervised Metagraph Informax Network
Oct 08, 2021
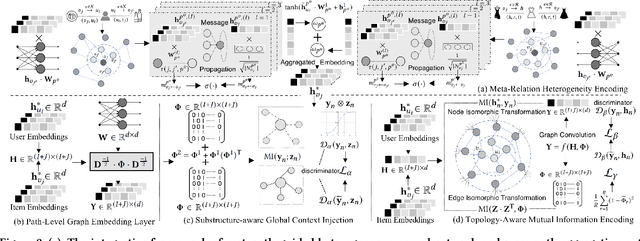

In recent years, researchers attempt to utilize online social information to alleviate data sparsity for collaborative filtering, based on the rationale that social networks offers the insights to understand the behavioral patterns. However, due to the overlook of inter-dependent knowledge across items (e.g., categories of products), existing social recommender systems are insufficient to distill the heterogeneous collaborative signals from both user and item sides. In this work, we propose a Self-Supervised Metagraph Infor-max Network (SMIN) which investigates the potential of jointly incorporating social- and knowledge-aware relational structures into the user preference representation for recommendation. To model relation heterogeneity, we design a metapath-guided heterogeneous graph neural network to aggregate feature embeddings from different types of meta-relations across users and items, em-powering SMIN to maintain dedicated representations for multi-faceted user- and item-wise dependencies. Additionally, to inject high-order collaborative signals, we generalize the mutual information learning paradigm under the self-supervised graph-based collaborative filtering. This endows the expressive modeling of user-item interactive patterns, by exploring global-level collaborative relations and underlying isomorphic transformation property of graph topology. Experimental results on several real-world datasets demonstrate the effectiveness of our SMIN model over various state-of-the-art recommendation methods. We release our source code at https://github.com/SocialRecsys/SMIN.
Exploring Separable Attention for Multi-Contrast MR Image Super-Resolution
Sep 03, 2021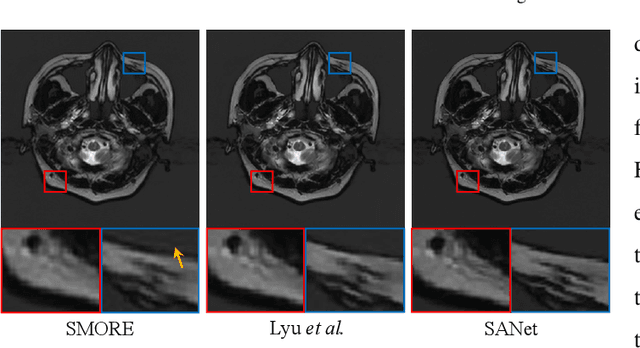
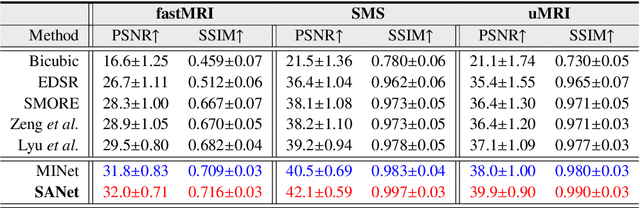
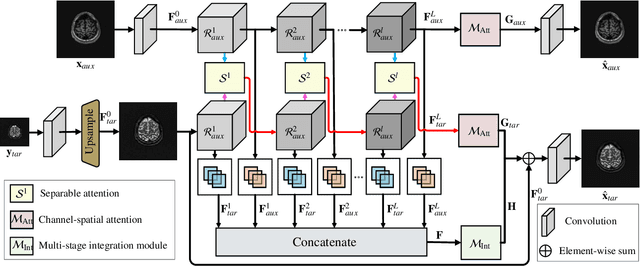
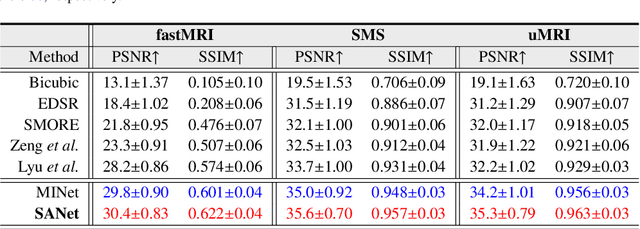
Super-resolving the Magnetic Resonance (MR) image of a target contrast under the guidance of the corresponding auxiliary contrast, which provides additional anatomical information, is a new and effective solution for fast MR imaging. However, current multi-contrast super-resolution (SR) methods tend to concatenate different contrasts directly, ignoring their relationships in different clues, \eg, in the foreground and background. In this paper, we propose a separable attention network (comprising a foreground priority attention and background separation attention), named SANet. Our method can explore the foreground and background areas in the forward and reverse directions with the help of the auxiliary contrast, enabling it to learn clearer anatomical structures and edge information for the SR of a target-contrast MR image. SANet provides three appealing benefits: (1) It is the first model to explore a separable attention mechanism that uses the auxiliary contrast to predict the foreground and background regions, diverting more attention to refining any uncertain details between these regions and correcting the fine areas in the reconstructed results. (2) A multi-stage integration module is proposed to learn the response of multi-contrast fusion at different stages, obtain the dependency between the fused features, and improve their representation ability. (3) Extensive experiments with various state-of-the-art multi-contrast SR methods on fastMRI and clinical \textit{in vivo} datasets demonstrate the superiority of our model.
Heterogeneous relational message passing networks for molecular dynamics simulations
Sep 02, 2021
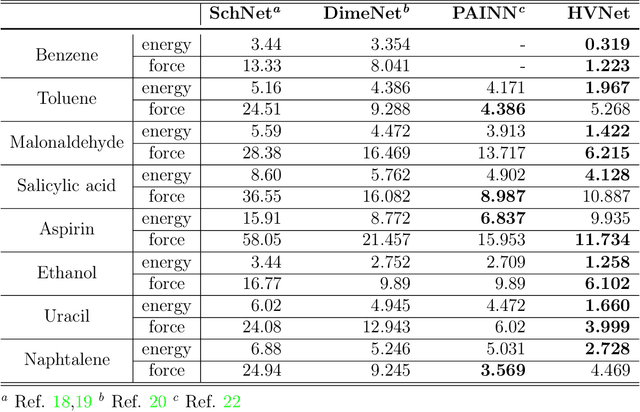
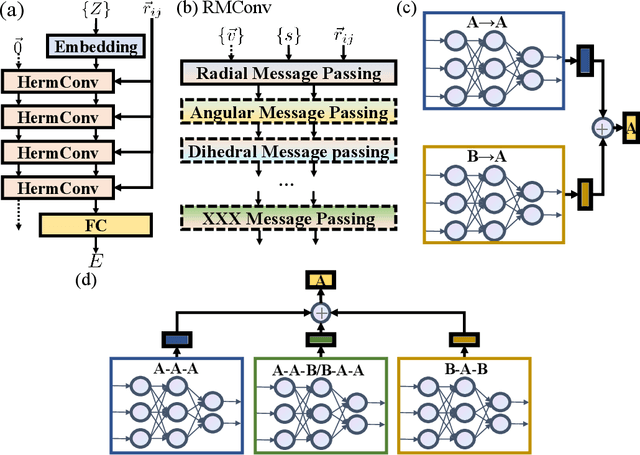
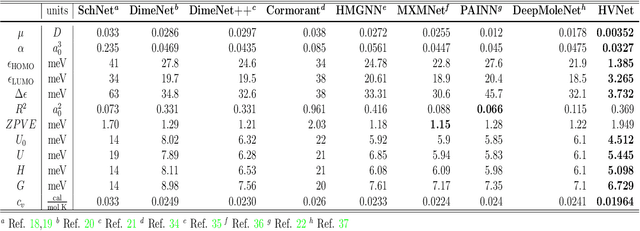
With many frameworks based on message passing neural networks proposed to predict molecular and bulk properties, machine learning methods have tremendously shifted the paradigms of computational sciences underpinning physics, material science, chemistry, and biology. While existing machine learning models have yielded superior performances in many occasions, most of them model and process molecular systems in terms of homogeneous graph, which severely limits the expressive power for representing diverse interactions. In practice, graph data with multiple node and edge types is ubiquitous and more appropriate for molecular systems. Thus, we propose the heterogeneous relational message passing network (HermNet), an end-to-end heterogeneous graph neural networks, to efficiently express multiple interactions in a single model with {\it ab initio} accuracy. HermNet performs impressively against many top-performing models on both molecular and extended systems. Specifically, HermNet outperforms other tested models in nearly 75\%, 83\% and 94\% of tasks on MD17, QM9 and extended systems datasets, respectively. Finally, we elucidate how the design of HermNet is compatible with quantum mechanics from the perspective of the density functional theory. Besides, HermNet is a universal framework, whose sub-networks could be replaced by other advanced models.
Fully Non-Homogeneous Atmospheric Scattering Modeling with Convolutional Neural Networks for Single Image Dehazing
Aug 25, 2021
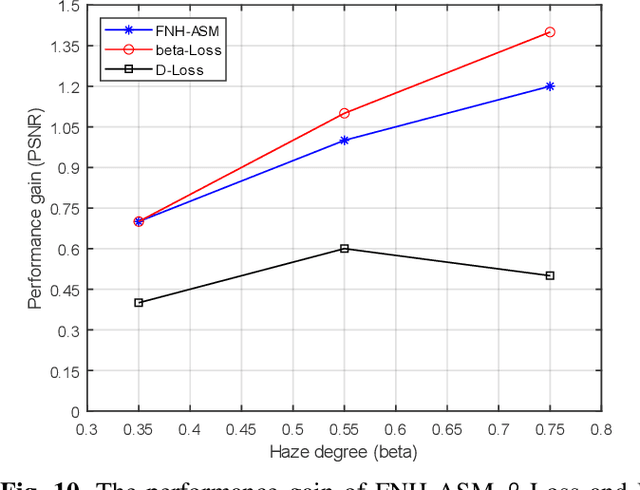


In recent years, single image dehazing models (SIDM) based on atmospheric scattering model (ASM) have achieved remarkable results. However, it is noted that ASM-based SIDM degrades its performance in dehazing real world hazy images due to the limited modelling ability of ASM where the atmospheric light factor (ALF) and the angular scattering coefficient (ASC) are assumed as constants for one image. Obviously, the hazy images taken in real world cannot always satisfy this assumption. Such generating modelling mismatch between the real-world images and ASM sets up the upper bound of trained ASM-based SIDM for dehazing. Bearing this in mind, in this study, a new fully non-homogeneous atmospheric scattering model (FNH-ASM) is proposed for well modeling the hazy images under complex conditions where ALF and ASC are pixel dependent. However, FNH-ASM brings difficulty in practical application. In FNH-ASM based SIDM, the estimation bias of parameters at different positions lead to different distortion of dehazing result. Hence, in order to reduce the influence of parameter estimation bias on dehazing results, two new cost sensitive loss functions, beta-Loss and D-Loss, are innovatively developed for limiting the parameter bias of sensitive positions that have a greater impact on the dehazing result. In the end, based on FNH-ASM, an end-to-end CNN-based dehazing network, FNHD-Net, is developed, which applies beta-Loss and D-Loss. Experimental results demonstrate the effectiveness and superiority of our proposed FNHD-Net for dehazing on both synthetic and real-world images. And the performance improvement of our method increases more obviously in dense and heterogeneous haze scenes.
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution
Jul 05, 2021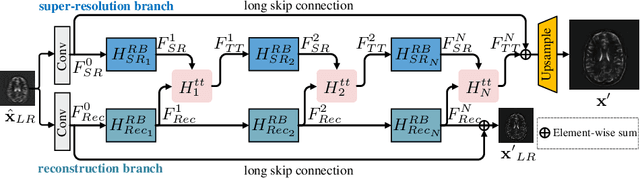
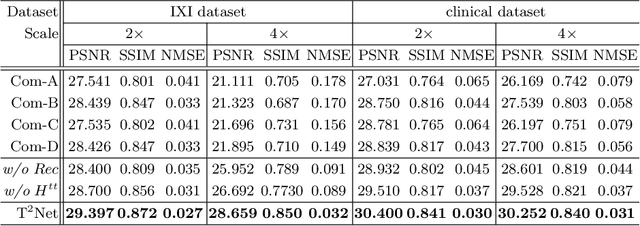
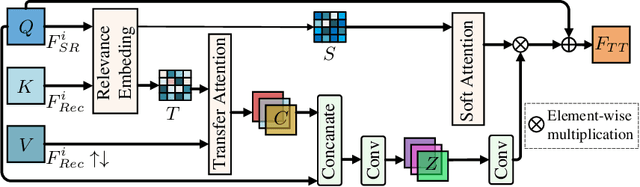
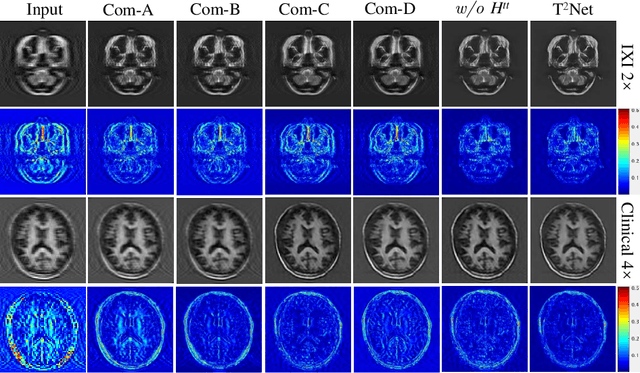
The core problem of Magnetic Resonance Imaging (MRI) is the trade off between acceleration and image quality. Image reconstruction and super-resolution are two crucial techniques in Magnetic Resonance Imaging (MRI). Current methods are designed to perform these tasks separately, ignoring the correlations between them. In this work, we propose an end-to-end task transformer network (T$^2$Net) for joint MRI reconstruction and super-resolution, which allows representations and feature transmission to be shared between multiple task to achieve higher-quality, super-resolved and motion-artifacts-free images from highly undersampled and degenerated MRI data. Our framework combines both reconstruction and super-resolution, divided into two sub-branches, whose features are expressed as queries and keys. Specifically, we encourage joint feature learning between the two tasks, thereby transferring accurate task information. We first use two separate CNN branches to extract task-specific features. Then, a task transformer module is designed to embed and synthesize the relevance between the two tasks. Experimental results show that our multi-task model significantly outperforms advanced sequential methods, both quantitatively and qualitatively.