 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Few-sample BERT Fine-tuning
Jul 02, 2020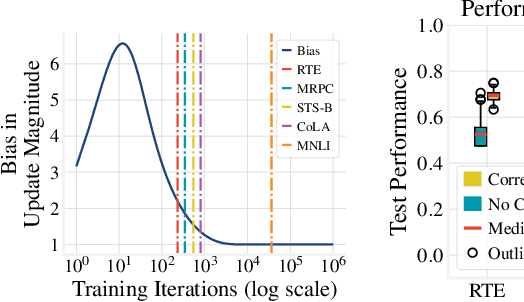
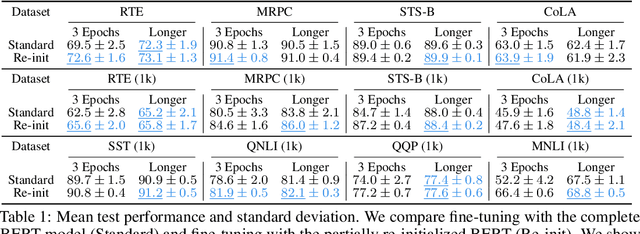

We study the problem of few-sample fine-tuning of BERT contextual representations, and identify three sub-optimal choices in current, broadly adopted practices. First, we observe that the omission of the gradient bias correction in the BERTAdam optimizer results in fine-tuning instability. We also find that parts of the BERT network provide a detrimental starting point for fine-tuning, and simply re-initializing these layers speeds up learning and improves performance. Finally, we study the effect of training time, and observe that commonly used recipes often do not allocate sufficient time for training. In light of these findings, we re-visit recently proposed methods to improve few-sample fine-tuning with BERT and re-evaluate their effectiveness. Generally, we observe a decrease in their relative impact when modifying the fine-tuning process based on our findings.
What is Learned in Visually Grounded Neural Syntax Acquisition
May 18, 2020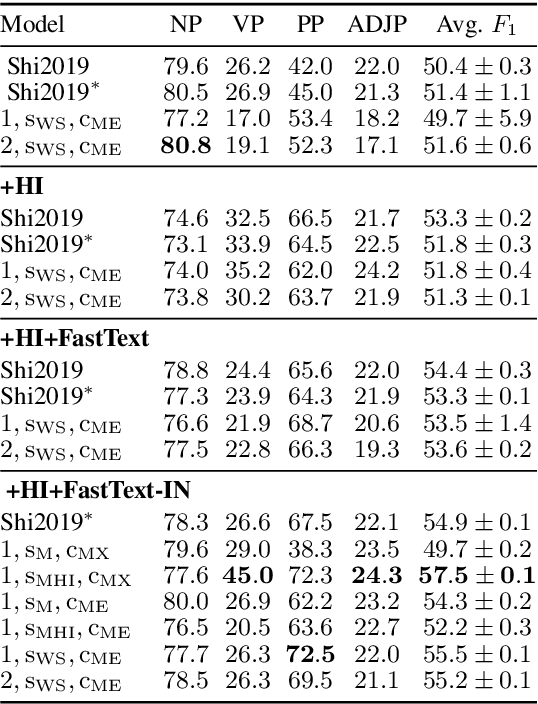
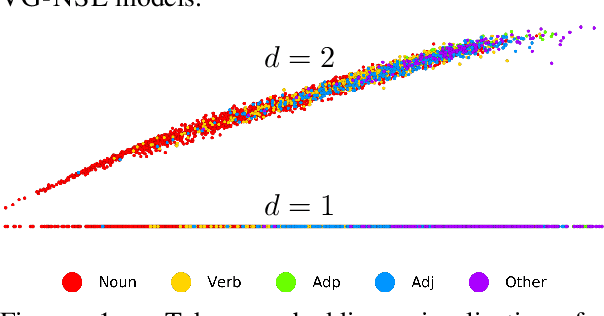
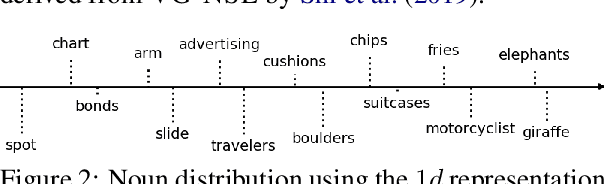
Visual features are a promising signal for learning bootstrap textual models. However, blackbox learning models make it difficult to isolate the specific contribution of visual components. In this analysis, we consider the case study of the Visually Grounded Neural Syntax Learner (Shi et al., 2019), a recent approach for learning syntax from a visual training signal. By constructing simplified versions of the model, we isolate the core factors that yield the model's strong performance. Contrary to what the model might be capable of learning, we find significantly less expressive versions produce similar predictions and perform just as well, or even better. We also find that a simple lexical signal of noun concreteness plays the main role in the model's predictions as opposed to more complex syntactic reasoning.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
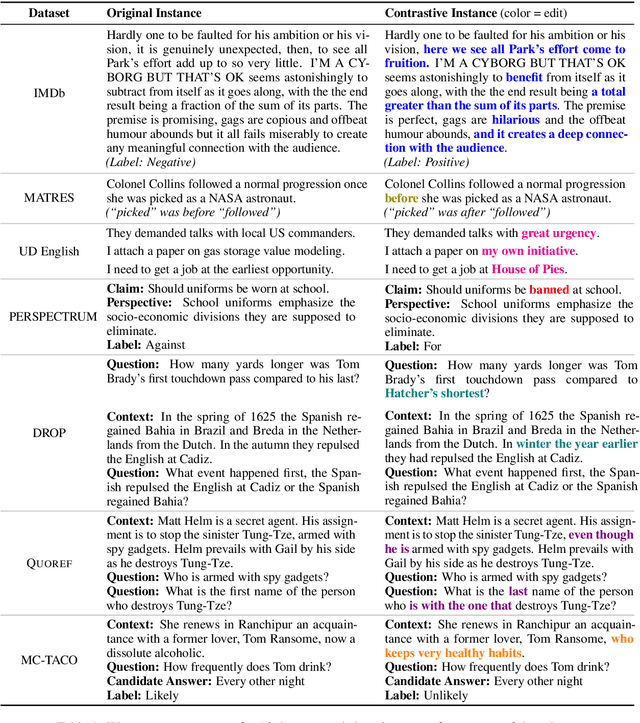
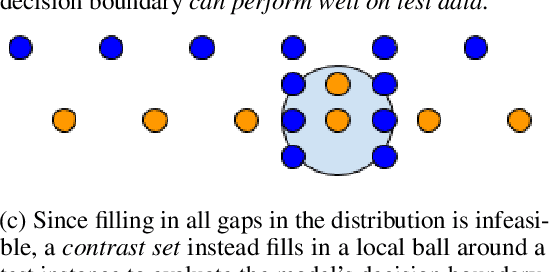
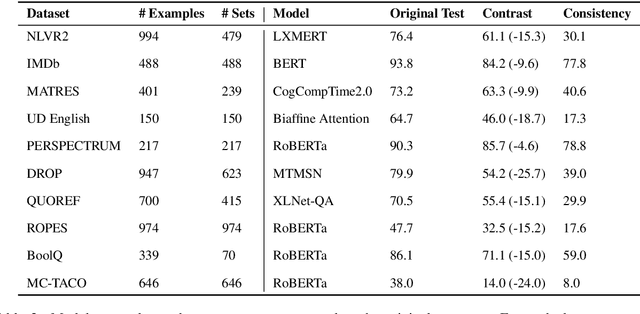
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Retouchdown: Adding Touchdown to StreetLearn as a Shareable Resource for Language Grounding Tasks in Street View
Jan 10, 2020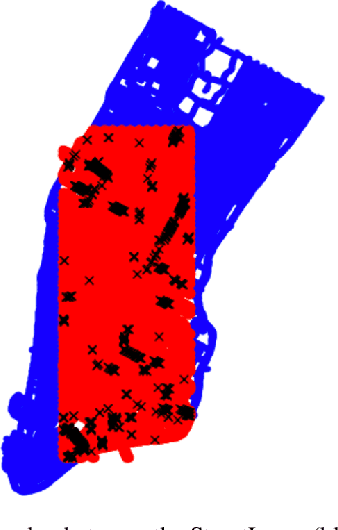
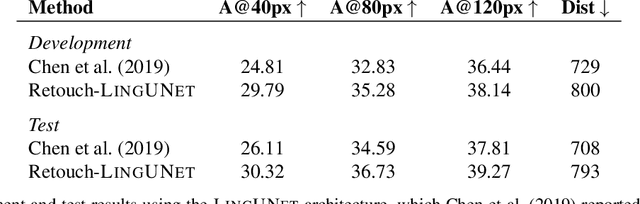

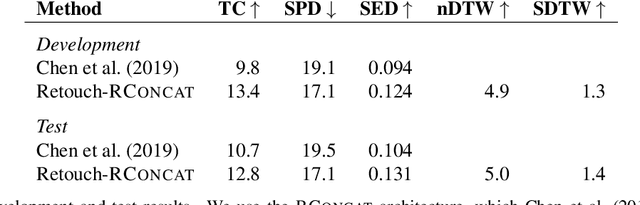
The Touchdown dataset (Chen et al., 2019) provides instructions by human annotators for navigation through New York City streets and for resolving spatial descriptions at a given location. To enable the wider research community to work effectively with the Touchdown tasks, we are publicly releasing the 29k raw Street View panoramas needed for Touchdown. We follow the process used for the StreetLearn data release (Mirowski et al., 2019) to check panoramas for personally identifiable information and blur them as necessary. These have been added to the StreetLearn dataset and can be obtained via the same process as used previously for StreetLearn. We also provide a reference implementation for both of the Touchdown tasks: vision and language navigation (VLN) and spatial description resolution (SDR). We compare our model results to those given in Chen et al. (2019) and show that the panoramas we have added to StreetLearn fully support both Touchdown tasks and can be used effectively for further research and comparison.
Interactive Classification by Asking Informative Questions
Nov 09, 2019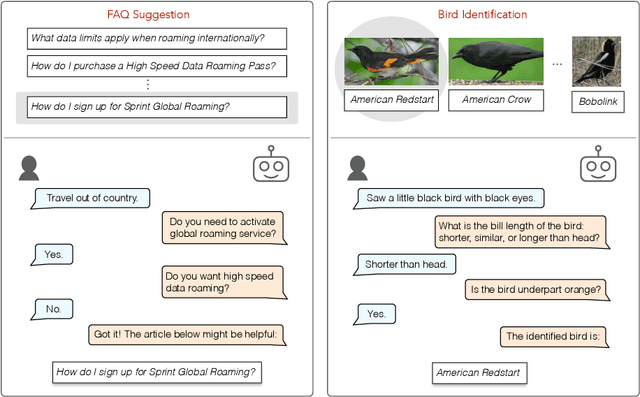
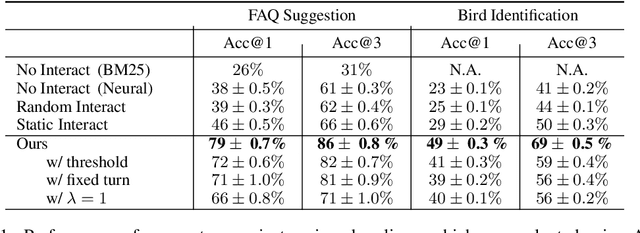
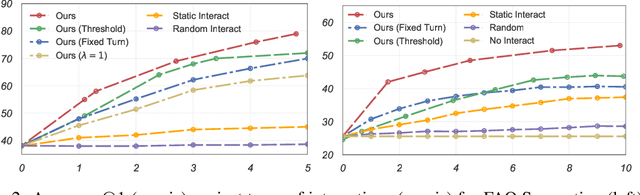
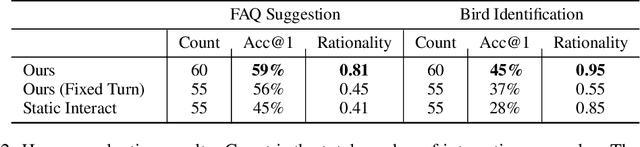
Natural language systems often rely on a single, potentially ambiguous input to make one final prediction, which may simplify the problem but degrade end user experience. Instead of making predictions with the natural language query only, we ask the user for additional information using a small number of binary and multiple-choice questions in order to better help users accomplish their goals while minimizing their effort. At each turn, our system decides between asking the most informative question or making the final classification prediction. Our approach enables bootstrapping the system using simple crowdsourcing annotations without expensive human-to-human interaction data. Evaluation demonstrates that our method substantially increases classification accuracy, while effectively balancing the number of questions with the improvement to final accuracy.
Learning to Map Natural Language Instructions to Physical Quadcopter Control using Simulated Flight
Oct 21, 2019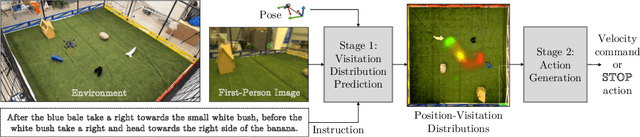
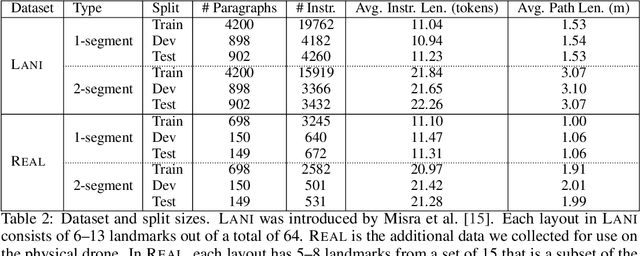
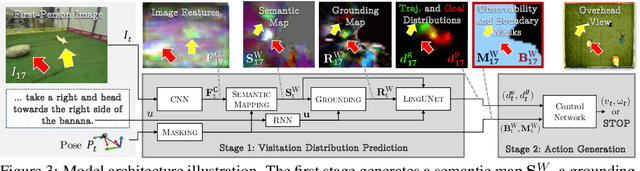
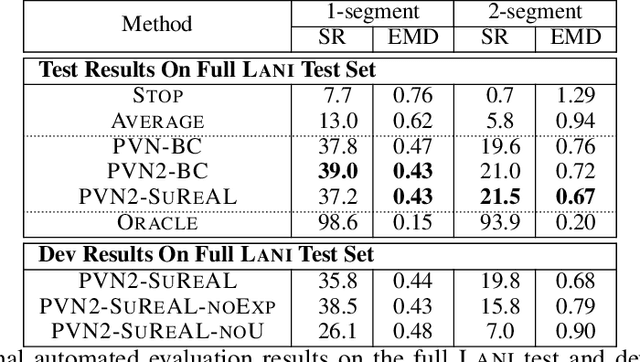
We propose a joint simulation and real-world learning framework for mapping navigation instructions and raw first-person observations to continuous control. Our model estimates the need for environment exploration, predicts the likelihood of visiting environment positions during execution, and controls the agent to both explore and visit high-likelihood positions. We introduce Supervised Reinforcement Asynchronous Learning (SuReAL). Learning uses both simulation and real environments without requiring autonomous flight in the physical environment during training, and combines supervised learning for predicting positions to visit and reinforcement learning for continuous control. We evaluate our approach on a natural language instruction-following task with a physical quadcopter, and demonstrate effective execution and exploration behavior.
Executing Instructions in Situated Collaborative Interactions
Oct 17, 2019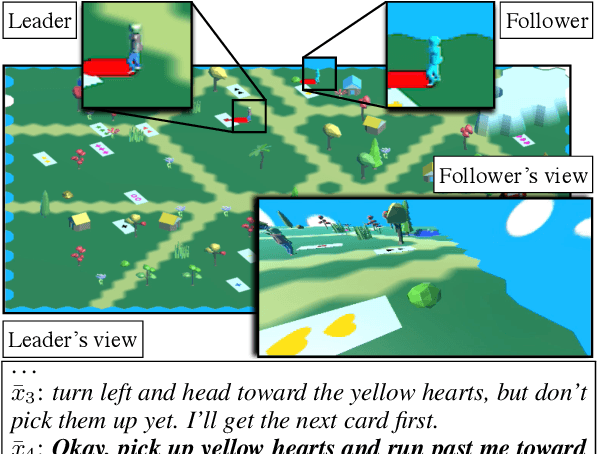
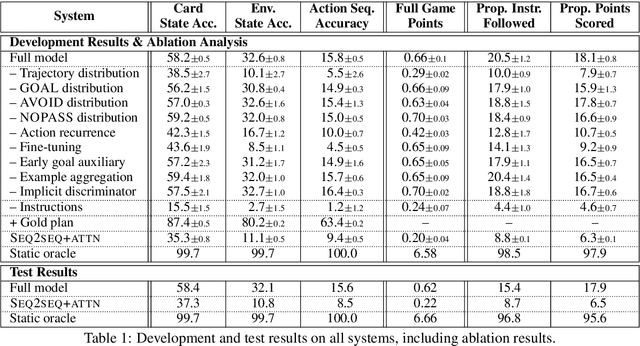
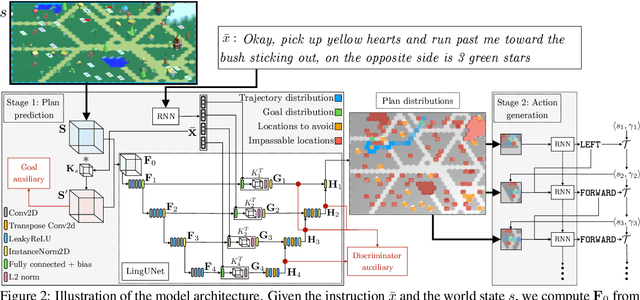

We study a collaborative scenario where a user not only instructs a system to complete tasks, but also acts alongside it. This allows the user to adapt to the system abilities by changing their language or deciding to simply accomplish some tasks themselves, and requires the system to effectively recover from errors as the user strategically assigns it new goals. We build a game environment to study this scenario, and learn to map user instructions to system actions. We introduce a learning approach focused on recovery from cascading errors between instructions, and modeling methods to explicitly reason about instructions with multiple goals. We evaluate with a new evaluation protocol using recorded interactions and online games with human users, and observe how users adapt to the system abilities.
NLVR2 Visual Bias Analysis
Sep 23, 2019

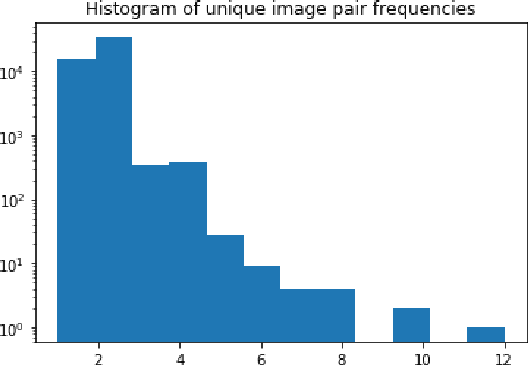
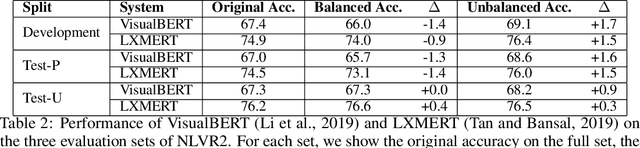
NLVR2 (Suhr et al., 2019) was designed to be robust for language bias through a data collection process that resulted in each natural language sentence appearing with both true and false labels. The process did not provide a similar measure of control for visual bias. This technical report analyzes the potential for visual bias in NLVR2. We show that some amount of visual bias likely exists. Finally, we identify a subset of the test data that allows to test for model performance in a way that is robust to such potential biases. We show that the performance of existing models (Li et al., 2019; Tan and Bansal 2019) is relatively robust to this potential bias. We propose to add the evaluation on this subset of the data to the NLVR2 evaluation protocol, and update the official release to include it. A notebook including an implementation of the code used to replicate this analysis is available at http://nlvr.ai/NLVR2BiasAnalysis.html.
BERTScore: Evaluating Text Generation with BERT
Apr 21, 2019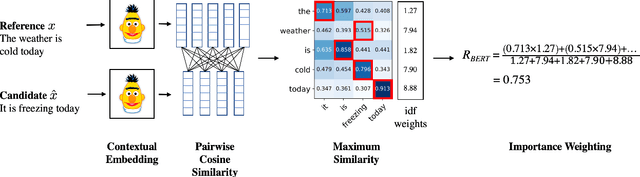
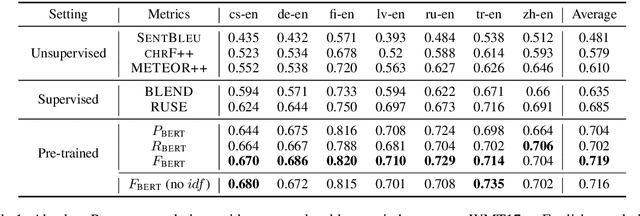
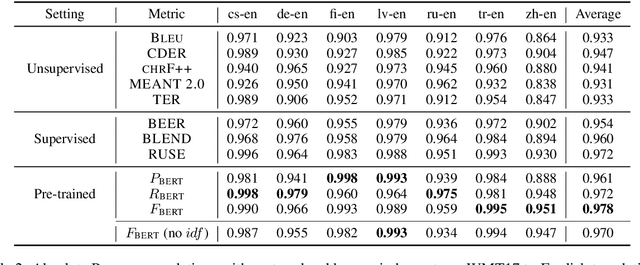
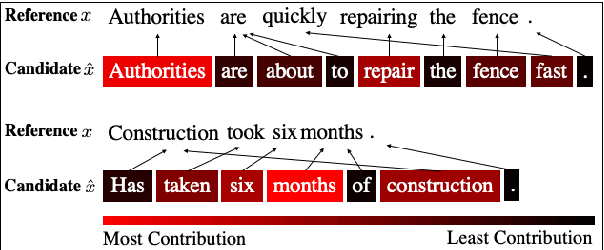
We propose BERTScore, an automatic evaluation metric for text generation. Analogous to common metrics, \method computes a similarity score for each token in the candidate sentence with each token in the reference. However, instead of looking for exact matches, we compute similarity using contextualized BERT embeddings. We evaluate on several machine translation and image captioning benchmarks, and show that BERTScore correlates better with human judgments than existing metrics, often significantly outperforming even task-specific supervised metrics.
Mapping Navigation Instructions to Continuous Control Actions with Position-Visitation Prediction
Dec 10, 2018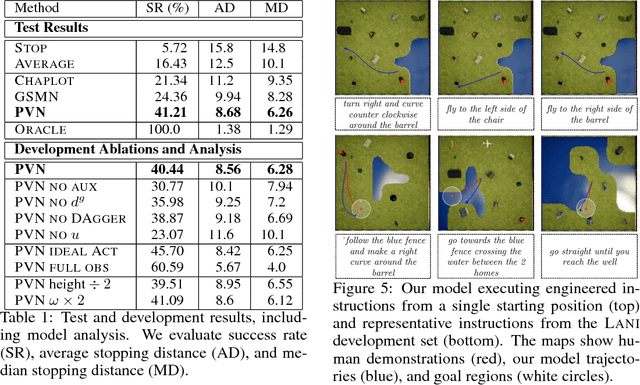
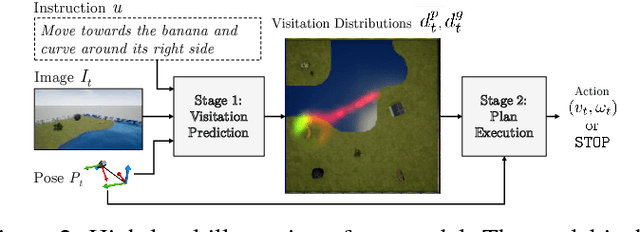
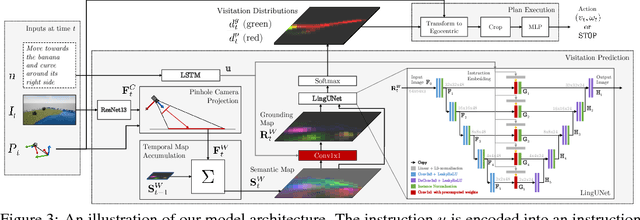

We propose an approach for mapping natural language instructions and raw observations to continuous control of a quadcopter drone. Our model predicts interpretable position-visitation distributions indicating where the agent should go during execution and where it should stop, and uses the predicted distributions to select the actions to execute. This two-step model decomposition allows for simple and efficient training using a combination of supervised learning and imitation learning. We evaluate our approach with a realistic drone simulator, and demonstrate absolute task-completion accuracy improvements of 16.85% over two state-of-the-art instruction-following methods.
* Appeared in Conference on Robot Learning 2018