 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Viability of using LLMs for SW/HW Co-Design: An Example in Designing CiM DNN Accelerators
Jun 12, 2023



Deep Neural Networks (DNNs) have demonstrated impressive performance across a wide range of tasks. However, deploying DNNs on edge devices poses significant challenges due to stringent power and computational budgets. An effective solution to this issue is software-hardware (SW-HW) co-design, which allows for the tailored creation of DNN models and hardware architectures that optimally utilize available resources. However, SW-HW co-design traditionally suffers from slow optimization speeds because their optimizers do not make use of heuristic knowledge, also known as the ``cold start'' problem. In this study, we present a novel approach that leverages Large Language Models (LLMs) to address this issue. By utilizing the abundant knowledge of pre-trained LLMs in the co-design optimization process, we effectively bypass the cold start problem, substantially accelerating the design process. The proposed method achieves a significant speedup of 25x. This advancement paves the way for the rapid and efficient deployment of DNNs on edge devices.
Conditional Diffusion Models for Weakly Supervised Medical Image Segmentation
Jun 06, 2023



Recent advances in denoising diffusion probabilistic models have shown great success in image synthesis tasks. While there are already works exploring the potential of this powerful tool in image semantic segmentation, its application in weakly supervised semantic segmentation (WSSS) remains relatively under-explored. Observing that conditional diffusion models (CDM) is capable of generating images subject to specific distributions, in this work, we utilize category-aware semantic information underlied in CDM to get the prediction mask of the target object with only image-level annotations. More specifically, we locate the desired class by approximating the derivative of the output of CDM w.r.t the input condition. Our method is different from previous diffusion model methods with guidance from an external classifier, which accumulates noises in the background during the reconstruction process. Our method outperforms state-of-the-art CAM and diffusion model methods on two public medical image segmentation datasets, which demonstrates that CDM is a promising tool in WSSS. Also, experiment shows our method is more time-efficient than existing diffusion model methods, making it practical for wider applications.
Additional Positive Enables Better Representation Learning for Medical Images
May 31, 2023


This paper presents a new way to identify additional positive pairs for BYOL, a state-of-the-art (SOTA) self-supervised learning framework, to improve its representation learning ability. Unlike conventional BYOL which relies on only one positive pair generated by two augmented views of the same image, we argue that information from different images with the same label can bring more diversity and variations to the target features, thus benefiting representation learning. To identify such pairs without any label, we investigate TracIn, an instance-based and computationally efficient influence function, for BYOL training. Specifically, TracIn is a gradient-based method that reveals the impact of a training sample on a test sample in supervised learning. We extend it to the self-supervised learning setting and propose an efficient batch-wise per-sample gradient computation method to estimate the pairwise TracIn to represent the similarity of samples in the mini-batch during training. For each image, we select the most similar sample from other images as the additional positive and pull their features together with BYOL loss. Experimental results on two public medical datasets (i.e., ISIC 2019 and ChestX-ray) demonstrate that the proposed method can improve the classification performance compared to other competitive baselines in both semi-supervised and transfer learning settings.
TinyML Design Contest for Life-Threatening Ventricular Arrhythmia Detection
May 23, 2023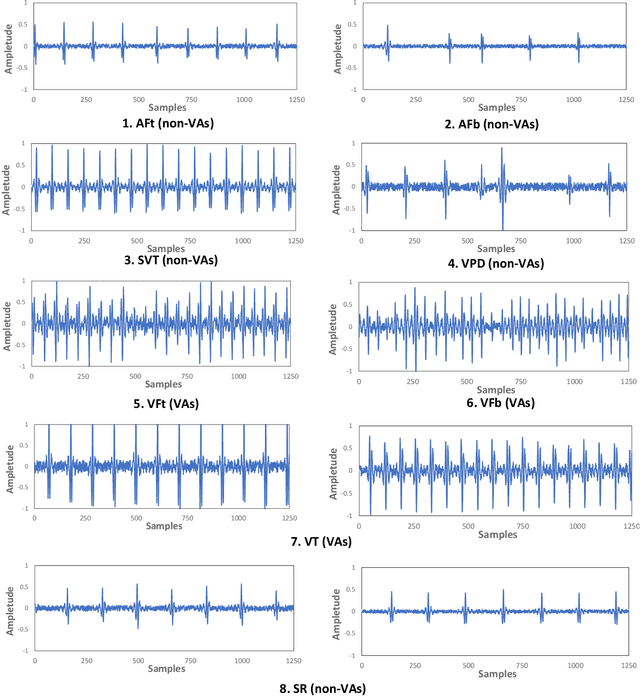

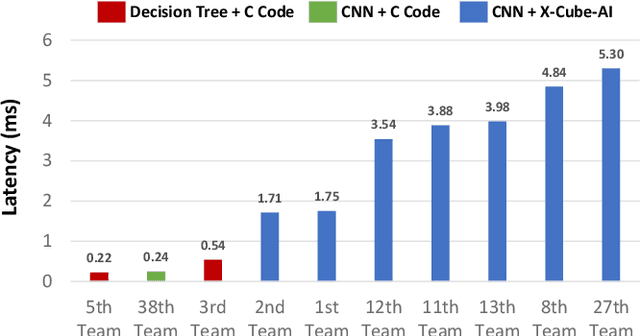
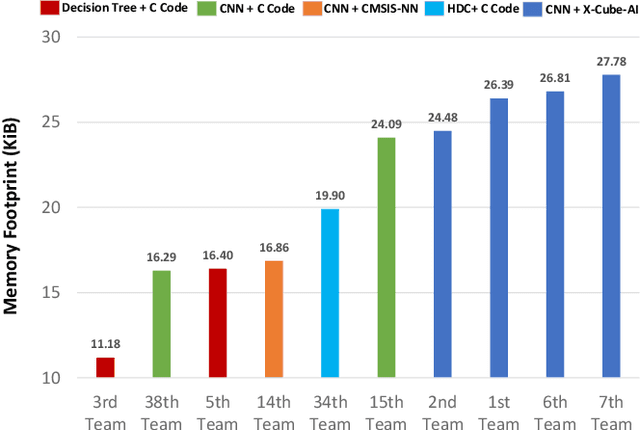
The first ACM/IEEE TinyML Design Contest (TDC) held at the 41st International Conference on Computer-Aided Design (ICCAD) in 2022 is a challenging, multi-month, research and development competition. TDC'22 focuses on real-world medical problems that require the innovation and implementation of artificial intelligence/machine learning (AI/ML) algorithms on implantable devices. The challenge problem of TDC'22 is to develop a novel AI/ML-based real-time detection algorithm for life-threatening ventricular arrhythmia over low-power microcontrollers utilized in Implantable Cardioverter-Defibrillators (ICDs). The dataset contains more than 38,000 5-second intracardiac electrograms (IEGMs) segments over 8 different types of rhythm from 90 subjects. The dedicated hardware platform is NUCLEO-L432KC manufactured by STMicroelectronics. TDC'22, which is open to multi-person teams world-wide, attracted more than 150 teams from over 50 organizations. This paper first presents the medical problem, dataset, and evaluation procedure in detail. It further demonstrates and discusses the designs developed by the leading teams as well as representative results. This paper concludes with the direction of improvement for the future TinyML design for health monitoring applications.
Negative Feedback Training: A Novel Concept to Improve Robustness of NVCiM DNN Accelerators
May 23, 2023



Compute-in-Memory (CiM) utilizing non-volatile memory (NVM) devices presents a highly promising and efficient approach for accelerating deep neural networks (DNNs). By concurrently storing network weights and performing matrix operations within the same crossbar structure, CiM accelerators offer DNN inference acceleration with minimal area requirements and exceptional energy efficiency. However, the stochasticity and intrinsic variations of NVM devices often lead to performance degradation, such as reduced classification accuracy, compared to expected outcomes. Although several methods have been proposed to mitigate device variation and enhance robustness, most of them rely on overall modulation and lack constraints on the training process. Drawing inspiration from the negative feedback mechanism, we introduce a novel training approach that uses a multi-exit mechanism as negative feedback to enhance the performance of DNN models in the presence of device variation. Our negative feedback training method surpasses state-of-the-art techniques by achieving an impressive improvement of up to 12.49% in addressing DNN robustness against device variation.
Fair Multi-Exit Framework for Facial Attribute Classification
Jan 08, 2023



Fairness has become increasingly pivotal in facial recognition. Without bias mitigation, deploying unfair AI would harm the interest of the underprivileged population. In this paper, we observe that though the higher accuracy that features from the deeper layer of a neural networks generally offer, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit framework. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented, where the internal classifiers are trained to be more accurate and fairer. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Moreover, our framework can be applied to most existing fairness-aware frameworks. Experiment results show that the proposed framework can largely improve the fairness condition over the state-of-the-art in CelebA and UTK Face datasets.
Development of A Real-time POCUS Image Quality Assessment and Acquisition Guidance System
Dec 19, 2022

Point-of-care ultrasound (POCUS) is one of the most commonly applied tools for cardiac function imaging in the clinical routine of the emergency department and pediatric intensive care unit. The prior studies demonstrate that AI-assisted software can guide nurses or novices without prior sonography experience to acquire POCUS by recognizing the interest region, assessing image quality, and providing instructions. However, these AI algorithms cannot simply replace the role of skilled sonographers in acquiring diagnostic-quality POCUS. Unlike chest X-ray, CT, and MRI, which have standardized imaging protocols, POCUS can be acquired with high inter-observer variability. Though being with variability, they are usually all clinically acceptable and interpretable. In challenging clinical environments, sonographers employ novel heuristics to acquire POCUS in complex scenarios. To help novice learners to expedite the training process while reducing the dependency on experienced sonographers in the curriculum implementation, We will develop a framework to perform real-time AI-assisted quality assessment and probe position guidance to provide training process for novice learners with less manual intervention.
FedCoCo: A Memory Efficient Federated Self-supervised Framework for On-Device Visual Representation Learning
Dec 02, 2022



The ubiquity of edge devices has led to a growing amount of unlabeled data produced at the edge. Deep learning models deployed on edge devices are required to learn from these unlabeled data to continuously improve accuracy. Self-supervised representation learning has achieved promising performances using centralized unlabeled data. However, the increasing awareness of privacy protection limits centralizing the distributed unlabeled image data on edge devices. While federated learning has been widely adopted to enable distributed machine learning with privacy preservation, without a data selection method to efficiently select streaming data, the traditional federated learning framework fails to handle these huge amounts of decentralized unlabeled data with limited storage resources on edge. To address these challenges, we propose a Federated on-device Contrastive learning framework with Coreset selection, which we call FedCoCo, to automatically select a coreset that consists of the most representative samples into the replay buffer on each device. It preserves data privacy as each client does not share raw data while learning good visual representations. Experiments demonstrate the effectiveness and significance of the proposed method in visual representation learning.
Unsupervised Feature Clustering Improves Contrastive Representation Learning for Medical Image Segmentation
Nov 15, 2022Self-supervised instance discrimination is an effective contrastive pretext task to learn feature representations and address limited medical image annotations. The idea is to make features of transformed versions of the same images similar while forcing all other augmented images' representations to contrast. However, this instance-based contrastive learning leaves performance on the table by failing to maximize feature affinity between images with similar content while counter-productively pushing their representations apart. Recent improvements on this paradigm (e.g., leveraging multi-modal data, different images in longitudinal studies, spatial correspondences) either relied on additional views or made stringent assumptions about data properties, which can sacrifice generalizability and applicability. To address this challenge, we propose a new self-supervised contrastive learning method that uses unsupervised feature clustering to better select positive and negative image samples. More specifically, we produce pseudo-classes by hierarchically clustering features obtained by an auto-encoder in an unsupervised manner, and prevent destructive interference during contrastive learning by avoiding the selection of negatives from the same pseudo-class. Experiments on 2D skin dermoscopic image segmentation and 3D multi-class whole heart CT segmentation demonstrate that our method outperforms state-of-the-art self-supervised contrastive techniques on these tasks.
ImageCAS: A Large-Scale Dataset and Benchmark for Coronary Artery Segmentation based on Computed Tomography Angiography Images
Nov 03, 2022Cardiovascular disease (CVD) accounts for about half of non-communicable diseases. Vessel stenosis in the coronary artery is considered to be the major risk of CVD. Computed tomography angiography (CTA) is one of the widely used noninvasive imaging modalities in coronary artery diagnosis due to its superior image resolution. Clinically, segmentation of coronary arteries is essential for the diagnosis and quantification of coronary artery disease. Recently, a variety of works have been proposed to address this problem. However, on one hand, most works rely on in-house datasets, and only a few works published their datasets to the public which only contain tens of images. On the other hand, their source code have not been published, and most follow-up works have not made comparison with existing works, which makes it difficult to judge the effectiveness of the methods and hinders the further exploration of this challenging yet critical problem in the community. In this paper, we propose a large-scale dataset for coronary artery segmentation on CTA images. In addition, we have implemented a benchmark in which we have tried our best to implement several typical existing methods. Furthermore, we propose a strong baseline method which combines multi-scale patch fusion and two-stage processing to extract the details of vessels. Comprehensive experiments show that the proposed method achieves better performance than existing works on the proposed large-scale dataset. The benchmark and the dataset are published at https://github.com/XiaoweiXu/ImageCAS-A-Large-Scale-Dataset-and-Benchmark-for-Coronary-Artery-Segmentation-based-on-CT.