 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Self-Evolve
Mar 19, 2026We introduce Learning to Self-Evolve (LSE), a reinforcement learning framework that trains large language models (LLMs) to improve their own contexts at test time. We situate LSE in the setting of test-time self-evolution, where a model iteratively refines its context from feedback on seen problems to perform better on new ones. Existing approaches rely entirely on the inherent reasoning ability of the model and never explicitly train it for this task. LSE reduces the multi-step evolution problem to a single-step RL objective, where each context edit is rewarded by the improvement in downstream performance. We pair this objective with a tree-guided evolution loop. On Text-to-SQL generation (BIRD) and general question answering (MMLU-Redux), a 4B-parameter model trained with LSE outperforms self-evolving policies powered by GPT-5 and Claude Sonnet 4.5, as well as prompt optimization methods including GEPA and TextGrad, and transfers to guide other models without additional training. Our results highlight the effectiveness of treating self-evolution as a learnable skill.
DARE-bench: Evaluating Modeling and Instruction Fidelity of LLMs in Data Science
Feb 27, 2026The fast-growing demands in using Large Language Models (LLMs) to tackle complex multi-step data science tasks create an emergent need for accurate benchmarking. There are two major gaps in existing benchmarks: (i) the lack of standardized, process-aware evaluation that captures instruction adherence and process fidelity, and (ii) the scarcity of accurately labeled training data. To bridge these gaps, we introduce DARE-bench, a benchmark designed for machine learning modeling and data science instruction following. Unlike many existing benchmarks that rely on human- or model-based judges, all tasks in DARE-bench have verifiable ground truth, ensuring objective and reproducible evaluation. To cover a broad range of tasks and support agentic tools, DARE-bench consists of 6,300 Kaggle-derived tasks and provides both large-scale training data and evaluation sets. Extensive evaluations show that even highly capable models such as gpt-o4-mini struggle to achieve good performance, especially in machine learning modeling tasks. Using DARE-bench training tasks for fine-tuning can substantially improve model performance. For example, supervised fine-tuning boosts Qwen3-32B's accuracy by 1.83x and reinforcement learning boosts Qwen3-4B's accuracy by more than 8x. These significant improvements verify the importance of DARE-bench both as an accurate evaluation benchmark and critical training data.
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Feb 11, 2026Recent advances in large language model (LLM) have empowered autonomous agents to perform complex tasks that require multi-turn interactions with tools and environments. However, scaling such agent training is limited by the lack of diverse and reliable environments. In this paper, we propose Agent World Model (AWM), a fully synthetic environment generation pipeline. Using this pipeline, we scale to 1,000 environments covering everyday scenarios, in which agents can interact with rich toolsets (35 tools per environment on average) and obtain high-quality observations. Notably, these environments are code-driven and backed by databases, providing more reliable and consistent state transitions than environments simulated by LLMs. Moreover, they enable more efficient agent interaction compared with collecting trajectories from realistic environments. To demonstrate the effectiveness of this resource, we perform large-scale reinforcement learning for multi-turn tool-use agents. Thanks to the fully executable environments and accessible database states, we can also design reliable reward functions. Experiments on three benchmarks show that training exclusively in synthetic environments, rather than benchmark-specific ones, yields strong out-of-distribution generalization. The code is available at https://github.com/Snowflake-Labs/agent-world-model.
LEMON: Lossless model expansion
Oct 12, 2023



Scaling of deep neural networks, especially Transformers, is pivotal for their surging performance and has further led to the emergence of sophisticated reasoning capabilities in foundation models. Such scaling generally requires training large models from scratch with random initialization, failing to leverage the knowledge acquired by their smaller counterparts, which are already resource-intensive to obtain. To tackle this inefficiency, we present $\textbf{L}$ossl$\textbf{E}$ss $\textbf{MO}$del Expansio$\textbf{N}$ (LEMON), a recipe to initialize scaled models using the weights of their smaller but pre-trained counterparts. This is followed by model training with an optimized learning rate scheduler tailored explicitly for the scaled models, substantially reducing the training time compared to training from scratch. Notably, LEMON is versatile, ensuring compatibility with various network structures, including models like Vision Transformers and BERT. Our empirical results demonstrate that LEMON reduces computational costs by 56.7% for Vision Transformers and 33.2% for BERT when compared to training from scratch.
NTK-SAP: Improving neural network pruning by aligning training dynamics
Apr 06, 2023



Pruning neural networks before training has received increasing interest due to its potential to reduce training time and memory. One popular method is to prune the connections based on a certain metric, but it is not entirely clear what metric is the best choice. Recent advances in neural tangent kernel (NTK) theory suggest that the training dynamics of large enough neural networks is closely related to the spectrum of the NTK. Motivated by this finding, we propose to prune the connections that have the least influence on the spectrum of the NTK. This method can help maintain the NTK spectrum, which may help align the training dynamics to that of its dense counterpart. However, one possible issue is that the fixed-weight-NTK corresponding to a given initial point can be very different from the NTK corresponding to later iterates during the training phase. We further propose to sample multiple realizations of random weights to estimate the NTK spectrum. Note that our approach is weight-agnostic, which is different from most existing methods that are weight-dependent. In addition, we use random inputs to compute the fixed-weight-NTK, making our method data-agnostic as well. We name our foresight pruning algorithm Neural Tangent Kernel Spectrum-Aware Pruning (NTK-SAP). Empirically, our method achieves better performance than all baselines on multiple datasets.
Double Dynamic Sparse Training for GANs
Feb 28, 2023



The past decade has witnessed a drastic increase in modern deep neural networks (DNNs) size, especially for generative adversarial networks (GANs). Since GANs usually suffer from high computational complexity, researchers have shown an increased interest in applying pruning methods to reduce the training and inference costs of GANs. Among different pruning methods invented for supervised learning, dynamic sparse training (DST) has gained increasing attention recently as it enjoys excellent training efficiency with comparable performance to post-hoc pruning. Hence, applying DST on GANs, where we train a sparse GAN with a fixed parameter count throughout training, seems to be a good candidate for reducing GAN training costs. However, a few challenges, including the degrading training instability, emerge due to the adversarial nature of GANs. Hence, we introduce a quantity called balance ratio (BR) to quantify the balance of the generator and the discriminator. We conduct a series of experiments to show the importance of BR in understanding sparse GAN training. Building upon single dynamic sparse training (SDST), where only the generator is adjusted during training, we propose double dynamic sparse training (DDST) to control the BR during GAN training. Empirically, DDST automatically determines the density of the discriminator and greatly boosts the performance of sparse GANs on multiple datasets.
Global Convergence of MAML and Theory-Inspired Neural Architecture Search for Few-Shot Learning
Mar 17, 2022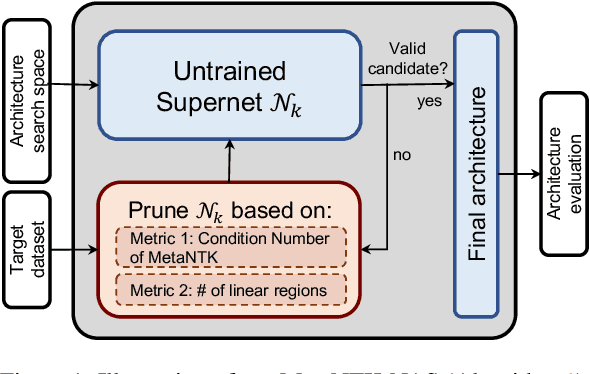
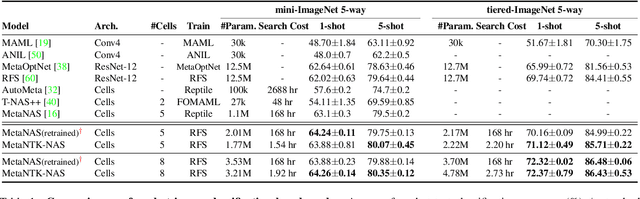
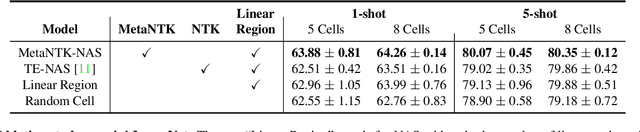
Model-agnostic meta-learning (MAML) and its variants have become popular approaches for few-shot learning. However, due to the non-convexity of deep neural nets (DNNs) and the bi-level formulation of MAML, the theoretical properties of MAML with DNNs remain largely unknown. In this paper, we first prove that MAML with over-parameterized DNNs is guaranteed to converge to global optima at a linear rate. Our convergence analysis indicates that MAML with over-parameterized DNNs is equivalent to kernel regression with a novel class of kernels, which we name as Meta Neural Tangent Kernels (MetaNTK). Then, we propose MetaNTK-NAS, a new training-free neural architecture search (NAS) method for few-shot learning that uses MetaNTK to rank and select architectures. Empirically, we compare our MetaNTK-NAS with previous NAS methods on two popular few-shot learning benchmarks, miniImageNet, and tieredImageNet. We show that the performance of MetaNTK-NAS is comparable or better than the state-of-the-art NAS method designed for few-shot learning while enjoying more than 100x speedup. We believe the efficiency of MetaNTK-NAS makes itself more practical for many real-world tasks.