 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety of Sampled-Data Systems with Control Barrier Functions via Approximate Discrete Time Models
Mar 22, 2022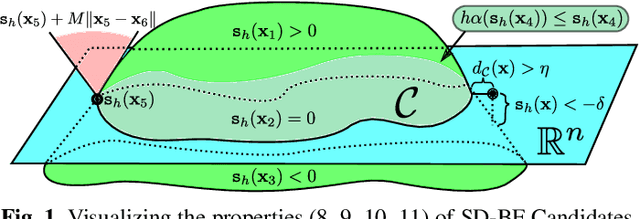
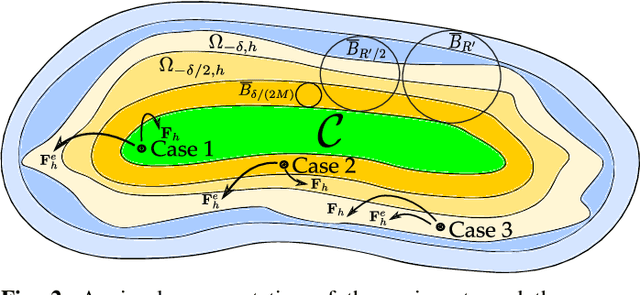
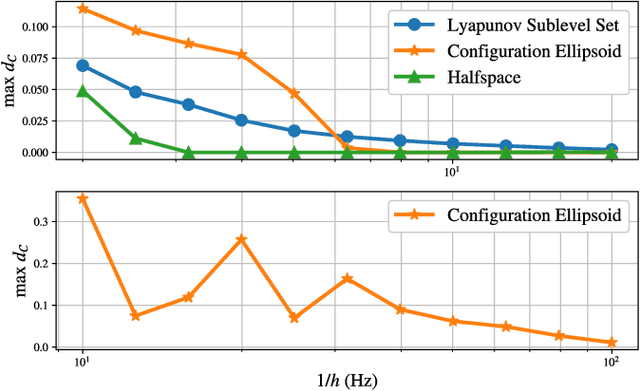

Control Barrier Functions (CBFs) have been demonstrated to be a powerful tool for safety-critical controller design for nonlinear systems. Existing design paradigms do not address the gap between theory (controller design with continuous time models) and practice (the discrete time sampled implementation of the resulting controllers); this can lead to poor performance and violations of safety for hardware instantiations. We propose an approach to close this gap by synthesizing sampled-data counterparts to these CBF-based controllers using approximate discrete time models and Sampled-Data Control Barrier Functions (SD-CBFs). Using properties of a system's continuous time model, we establish a relationship between SD-CBFs and a notion of practical safety for sampled-data systems. Furthermore, we construct convex optimization-based controllers that formally endow nonlinear systems with safety guarantees in practice. We demonstrate the efficacy of these controllers in simulation.
MLNav: Learning to Safely Navigate on Martian Terrains
Mar 09, 2022
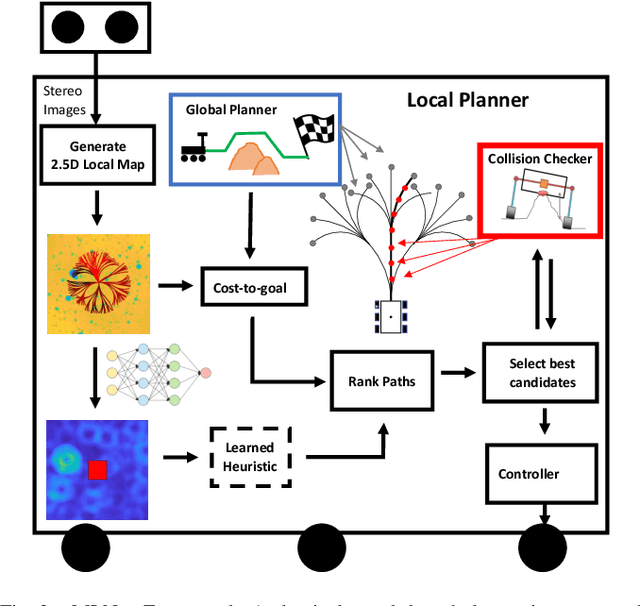
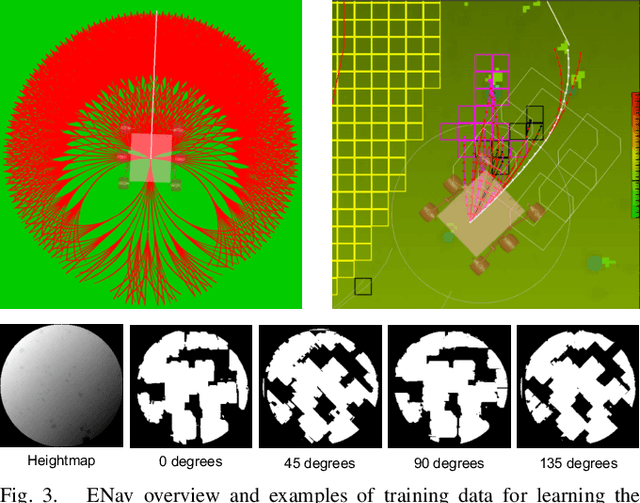

We present MLNav, a learning-enhanced path planning framework for safety-critical and resource-limited systems operating in complex environments, such as rovers navigating on Mars. MLNav makes judicious use of machine learning to enhance the efficiency of path planning while fully respecting safety constraints. In particular, the dominant computational cost in such safety-critical settings is running a model-based safety checker on the proposed paths. Our learned search heuristic can simultaneously predict the feasibility for all path options in a single run, and the model-based safety checker is only invoked on the top-scoring paths. We validate in high-fidelity simulations using both real Martian terrain data collected by the Perseverance rover, as well as a suite of challenging synthetic terrains. Our experiments show that: (i) compared to the baseline ENav path planner on board the Perserverance rover, MLNav can provide a significant improvement in multiple key metrics, such as a 10x reduction in collision checks when navigating real Martian terrains, despite being trained with synthetic terrains; and (ii) MLNav can successfully navigate highly challenging terrains where the baseline ENav fails to find a feasible path before timing out.
Self-Supervised Online Learning for Safety-Critical Control using Stereo Vision
Mar 02, 2022
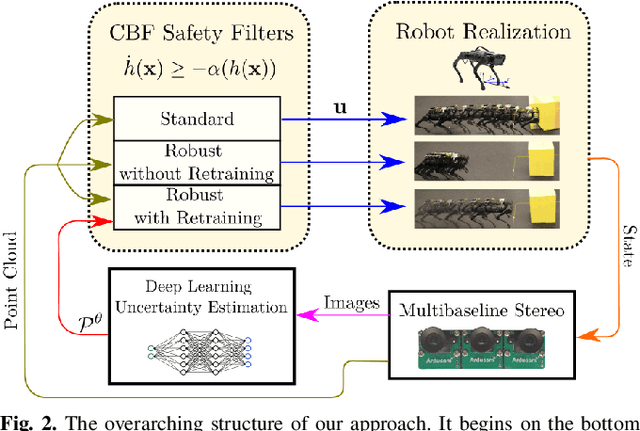
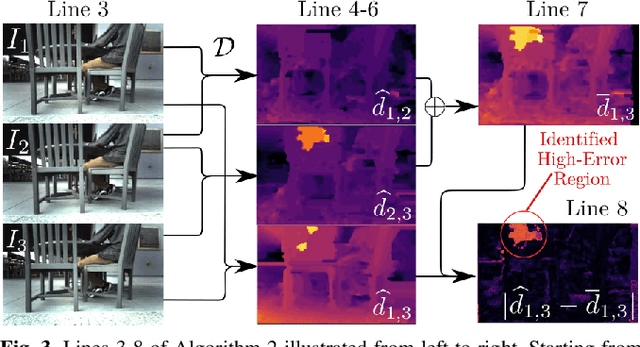
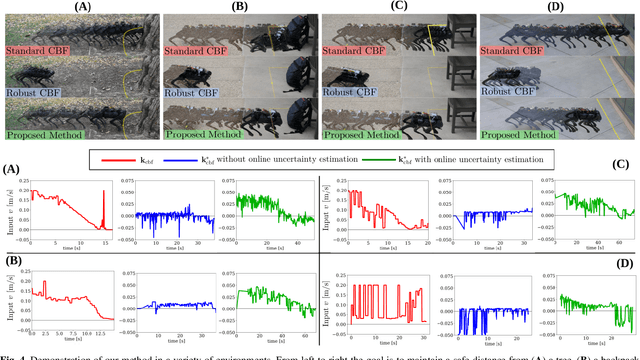
With the increasing prevalence of complex vision-based sensing methods for use in obstacle identification and state estimation, characterizing environment-dependent measurement errors has become a difficult and essential part of modern robotics. This paper presents a self-supervised learning approach to safety-critical control. In particular, the uncertainty associated with stereo vision is estimated, and adapted online to new visual environments, wherein this estimate is leveraged in a safety-critical controller in a robust fashion. To this end, we propose an algorithm that exploits the structure of stereo-vision to learn an uncertainty estimate without the need for ground-truth data. We then robustify existing Control Barrier Function-based controllers to provide safety in the presence of this uncertainty estimate. We demonstrate the efficacy of our method on a quadrupedal robot in a variety of environments. When not using our method safety is violated. With offline training alone we observe the robot is safe, but overly-conservative. With our online method the quadruped remains safe and conservatism is reduced.
LyaNet: A Lyapunov Framework for Training Neural ODEs
Feb 05, 2022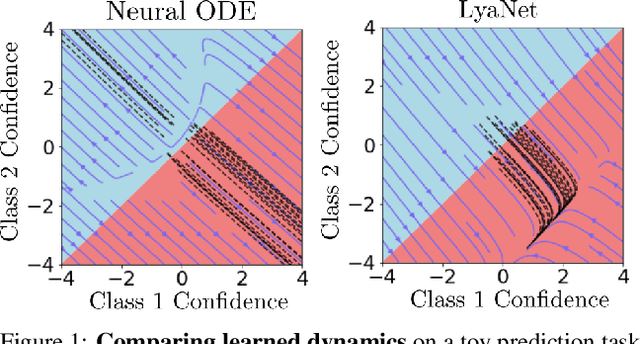
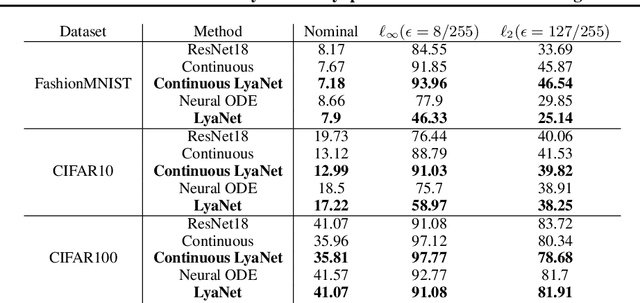
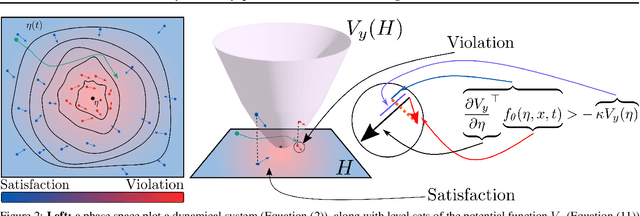
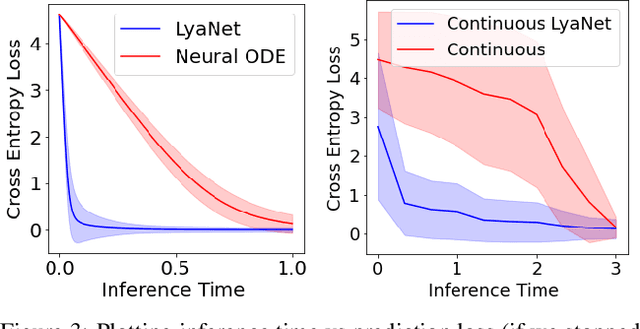
We propose a method for training ordinary differential equations by using a control-theoretic Lyapunov condition for stability. Our approach, called LyaNet, is based on a novel Lyapunov loss formulation that encourages the inference dynamics to converge quickly to the correct prediction. Theoretically, we show that minimizing Lyapunov loss guarantees exponential convergence to the correct solution and enables a novel robustness guarantee. We also provide practical algorithms, including one that avoids the cost of backpropagating through a solver or using the adjoint method. Relative to standard Neural ODE training, we empirically find that LyaNet can offer improved prediction performance, faster convergence of inference dynamics, and improved adversarial robustness. Our code available at https://github.com/ivandariojr/LyapunovLearning .
Safety-Aware Preference-Based Learning for Safety-Critical Control
Dec 15, 2021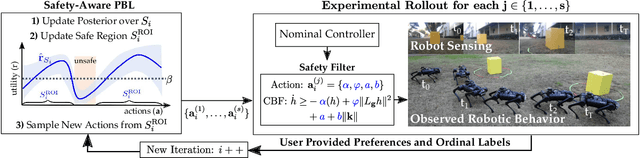
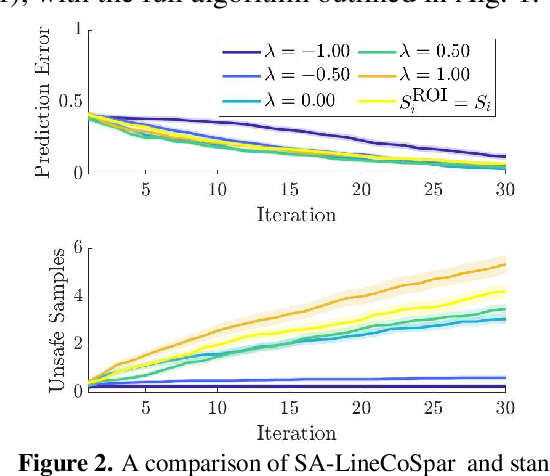
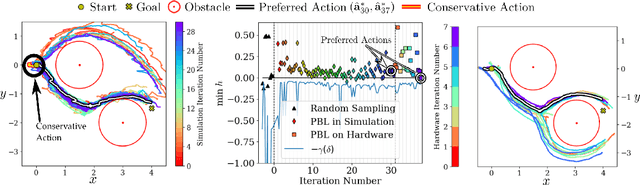

Bringing dynamic robots into the wild requires a tenuous balance between performance and safety. Yet controllers designed to provide robust safety guarantees often result in conservative behavior, and tuning these controllers to find the ideal trade-off between performance and safety typically requires domain expertise or a carefully constructed reward function. This work presents a design paradigm for systematically achieving behaviors that balance performance and robust safety by integrating safety-aware Preference-Based Learning (PBL) with Control Barrier Functions (CBFs). Fusing these concepts -- safety-aware learning and safety-critical control -- gives a robust means to achieve safe behaviors on complex robotic systems in practice. We demonstrate the capability of this design paradigm to achieve safe and performant perception-based autonomous operation of a quadrupedal robot both in simulation and experimentally on hardware.
Self-Supervised Keypoint Discovery in Behavioral Videos
Dec 09, 2021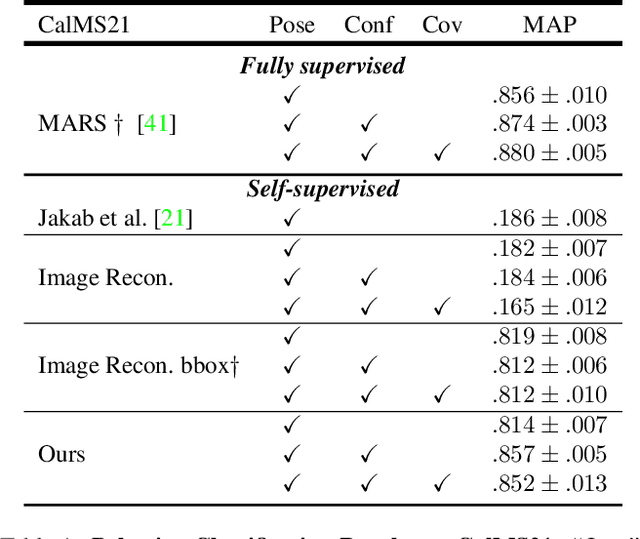
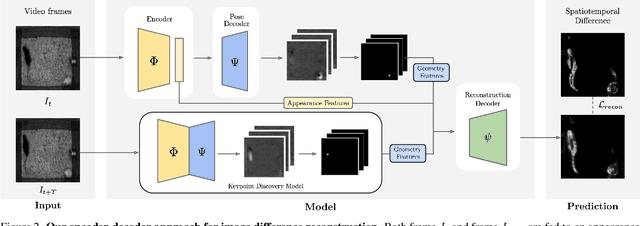

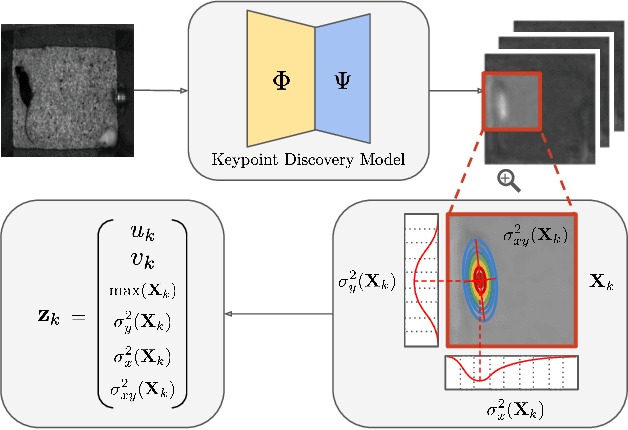
We propose a method for learning the posture and structure of agents from unlabelled behavioral videos. Starting from the observation that behaving agents are generally the main sources of movement in behavioral videos, our method uses an encoder-decoder architecture with a geometric bottleneck to reconstruct the difference between video frames. By focusing only on regions of movement, our approach works directly on input videos without requiring manual annotations, such as keypoints or bounding boxes. Experiments on a variety of agent types (mouse, fly, human, jellyfish, and trees) demonstrate the generality of our approach and reveal that our discovered keypoints represent semantically meaningful body parts, which achieve state-of-the-art performance on keypoint regression among self-supervised methods. Additionally, our discovered keypoints achieve comparable performance to supervised keypoints on downstream tasks, such as behavior classification, suggesting that our method can dramatically reduce the cost of model training vis-a-vis supervised methods.
Automatic Synthesis of Diverse Weak Supervision Sources for Behavior Analysis
Nov 30, 2021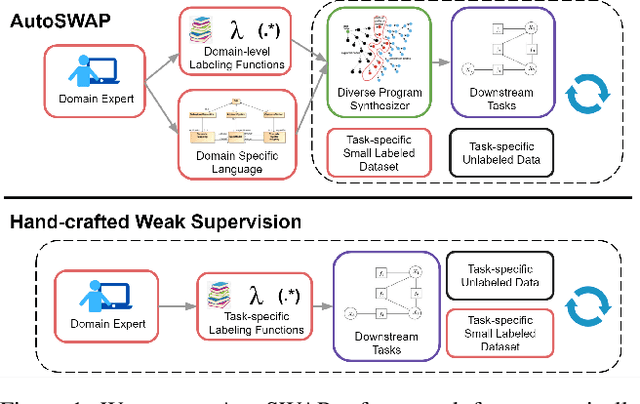



Obtaining annotations for large training sets is expensive, especially in behavior analysis settings where domain knowledge is required for accurate annotations. Weak supervision has been studied to reduce annotation costs by using weak labels from task-level labeling functions to augment ground truth labels. However, domain experts are still needed to hand-craft labeling functions for every studied task. To reduce expert effort, we present AutoSWAP: a framework for automatically synthesizing data-efficient task-level labeling functions. The key to our approach is to efficiently represent expert knowledge in a reusable domain specific language and domain-level labeling functions, with which we use state-of-the-art program synthesis techniques and a small labeled dataset to generate labeling functions. Additionally, we propose a novel structural diversity cost that allows for direct synthesis of diverse sets of labeling functions with minimal overhead, further improving labeling function data efficiency. We evaluate AutoSWAP in three behavior analysis domains and demonstrate that AutoSWAP outperforms existing approaches using only a fraction of the data. Our results suggest that AutoSWAP is an effective way to automatically generate labeling functions that can significantly reduce expert effort for behavior analysis.
On the Implicit Biases of Architecture & Gradient Descent
Oct 08, 2021
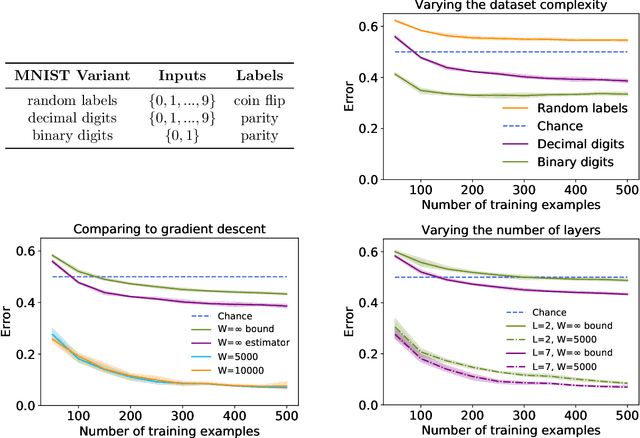
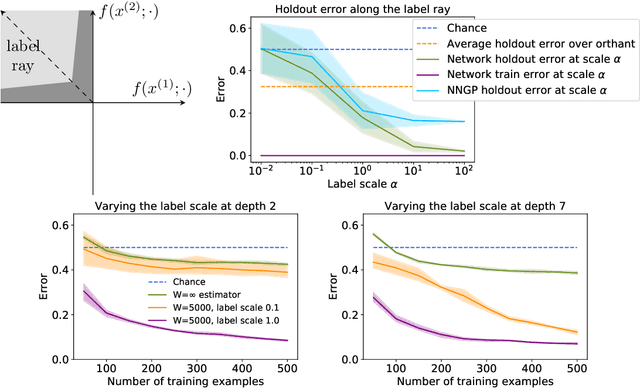
Do neural networks generalise because of bias in the functions returned by gradient descent, or bias already present in the network architecture? Por qu\'e no los dos? This paper finds that while typical networks that fit the training data already generalise fairly well, gradient descent can further improve generalisation by selecting networks with a large margin. This conclusion is based on a careful study of the behaviour of infinite width networks trained by Bayesian inference and finite width networks trained by gradient descent. To measure the implicit bias of architecture, new technical tools are developed to both analytically bound and consistently estimate the average test error of the neural network--Gaussian process (NNGP) posterior. This error is found to be already better than chance, corroborating the findings of Valle-P\'erez et al. (2019) and underscoring the importance of architecture. Going beyond this result, this paper finds that test performance can be substantially improved by selecting a function with much larger margin than is typical under the NNGP posterior. This highlights a curious fact: minimum a posteriori functions can generalise best, and gradient descent can select for those functions. In summary, new technical tools suggest a nuanced portrait of generalisation involving both the implicit biases of architecture and gradient descent. Code for this paper is available at: https://github.com/jxbz/implicit-bias/.
Natural Multicontact Walking for Robotic Assistive Devices via Musculoskeletal Models and Hybrid Zero Dynamics
Sep 10, 2021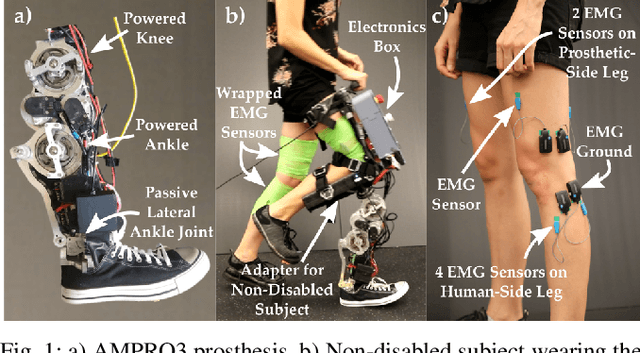
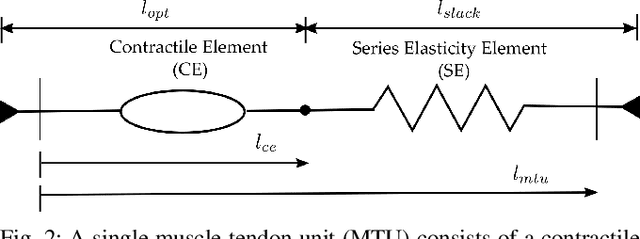
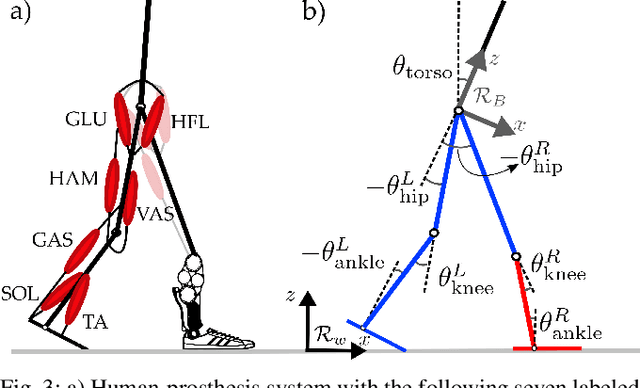
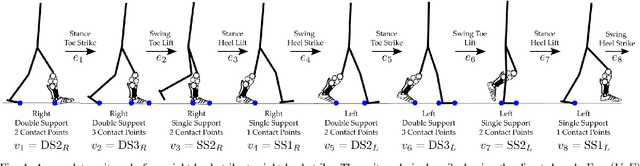
Generating provably stable walking gaits that yield natural locomotion when executed on robotic-assistive devices is a challenging task that often requires hand-tuning by domain experts. This paper presents an alternative methodology, where we propose the addition of musculoskeletal models directly into the gait generation process to intuitively shape the resulting behavior. In particular, we construct a multi-domain hybrid system model that combines the system dynamics with muscle models to represent natural multicontact walking. Stable walking gaits can then be formally generated for this model via the hybrid zero dynamics method. We experimentally apply our framework towards achieving multicontact locomotion on a dual-actuated transfemoral prosthesis, AMPRO3. The results demonstrate that enforcing feasible muscle dynamics produces gaits that yield natural locomotion (as analyzed via electromyography), without the need for extensive manual tuning. Moreover, these gaits yield similar behavior to expert-tuned gaits. We conclude that the novel approach of combining robotic walking methods (specifically HZD) with muscle models successfully generates anthropomorphic robotic-assisted locomotion.
Unsupervised Learning of Neurosymbolic Encoders
Jul 28, 2021

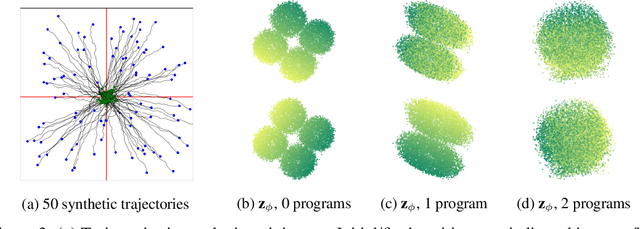
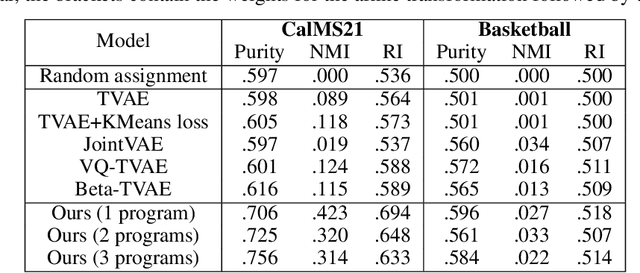
We present a framework for the unsupervised learning of neurosymbolic encoders, i.e., encoders obtained by composing neural networks with symbolic programs from a domain-specific language. Such a framework can naturally incorporate symbolic expert knowledge into the learning process and lead to more interpretable and factorized latent representations than fully neural encoders. Also, models learned this way can have downstream impact, as many analysis workflows can benefit from having clean programmatic descriptions. We ground our learning algorithm in the variational autoencoding (VAE) framework, where we aim to learn a neurosymbolic encoder in conjunction with a standard decoder. Our algorithm integrates standard VAE-style training with modern program synthesis techniques. We evaluate our method on learning latent representations for real-world trajectory data from animal biology and sports analytics. We show that our approach offers significantly better separation than standard VAEs and leads to practical gains on downstream tasks.