 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Power of AI-Generated Content for Semantic Communication
Apr 10, 2024



Semantic Communication (SemCom) is envisaged as the next-generation paradigm to address challenges stemming from the conflicts between the increasing volume of transmission data and the scarcity of spectrum resources. However, existing SemCom systems face drawbacks, such as low explainability, modality rigidity, and inadequate reconstruction functionality. Recognizing the transformative capabilities of AI-generated content (AIGC) technologies in content generation, this paper explores a pioneering approach by integrating them into SemCom to address the aforementioned challenges. We employ a three-layer model to illustrate the proposed AIGC-assisted SemCom (AIGC-SCM) architecture, emphasizing its clear deviation from existing SemCom. Grounded in this model, we investigate various AIGC technologies with the potential to augment SemCom's performance. In alignment with SemCom's goal of conveying semantic meanings, we also introduce the new evaluation methods for our AIGC-SCM system. Subsequently, we explore communication scenarios where our proposed AIGC-SCM can realize its potential. For practical implementation, we construct a detailed integration workflow and conduct a case study in a virtual reality image transmission scenario. The results demonstrate our ability to maintain a high degree of alignment between the reconstructed content and the original source information, while substantially minimizing the data volume required for transmission. These findings pave the way for further enhancements in communication efficiency and the improvement of Quality of Service. At last, we present future directions for AIGC-SCM studies.
GRA: Detecting Oriented Objects through Group-wise Rotating and Attention
Mar 19, 2024



Oriented object detection, an emerging task in recent years, aims to identify and locate objects across varied orientations. This requires the detector to accurately capture the orientation information, which varies significantly within and across images. Despite the existing substantial efforts, simultaneously ensuring model effectiveness and parameter efficiency remains challenging in this scenario. In this paper, we propose a lightweight yet effective Group-wise Rotating and Attention (GRA) module to replace the convolution operations in backbone networks for oriented object detection. GRA can adaptively capture fine-grained features of objects with diverse orientations, comprising two key components: Group-wise Rotating and Group-wise Attention. Group-wise Rotating first divides the convolution kernel into groups, where each group extracts different object features by rotating at a specific angle according to the object orientation. Subsequently, Group-wise Attention is employed to adaptively enhance the object-related regions in the feature. The collaborative effort of these components enables GRA to effectively capture the various orientation information while maintaining parameter efficiency. Extensive experimental results demonstrate the superiority of our method. For example, GRA achieves a new state-of-the-art (SOTA) on the DOTA-v2.0 benchmark, while saving the parameters by nearly 50% compared to the previous SOTA method. Code will be released.
2023 Low-Power Computer Vision Challenge (LPCVC) Summary
Mar 11, 2024



This article describes the 2023 IEEE Low-Power Computer Vision Challenge (LPCVC). Since 2015, LPCVC has been an international competition devoted to tackling the challenge of computer vision (CV) on edge devices. Most CV researchers focus on improving accuracy, at the expense of ever-growing sizes of machine models. LPCVC balances accuracy with resource requirements. Winners must achieve high accuracy with short execution time when their CV solutions run on an embedded device, such as Raspberry PI or Nvidia Jetson Nano. The vision problem for 2023 LPCVC is segmentation of images acquired by Unmanned Aerial Vehicles (UAVs, also called drones) after disasters. The 2023 LPCVC attracted 60 international teams that submitted 676 solutions during the submission window of one month. This article explains the setup of the competition and highlights the winners' methods that improve accuracy and shorten execution time.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024



This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
STAR-RIS-Assisted Privacy Protection in Semantic Communication System
Jun 22, 2023



Semantic communication (SemCom) has emerged as a promising architecture in the realm of intelligent communication paradigms. SemCom involves extracting and compressing the core information at the transmitter while enabling the receiver to interpret it based on established knowledge bases (KBs). This approach enhances communication efficiency greatly. However, the open nature of wireless transmission and the presence of homogeneous KBs among subscribers of identical data type pose a risk of privacy leakage in SemCom. To address this challenge, we propose to leverage the simultaneous transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) to achieve privacy protection in a SemCom system. In this system, the STAR-RIS is utilized to enhance the signal transmission of the SemCom between a base station and a destination user, as well as to covert the signal to interference specifically for the eavesdropper (Eve). Simulation results demonstrate that our generated task-level disturbance outperforms other benchmarks in protecting SemCom privacy, as evidenced by the significantly lower task success rate achieved by Eve.
Keyword-Based Diverse Image Retrieval by Semantics-aware Contrastive Learning and Transformer
May 06, 2023



In addition to relevance, diversity is an important yet less studied performance metric of cross-modal image retrieval systems, which is critical to user experience. Existing solutions for diversity-aware image retrieval either explicitly post-process the raw retrieval results from standard retrieval systems or try to learn multi-vector representations of images to represent their diverse semantics. However, neither of them is good enough to balance relevance and diversity. On the one hand, standard retrieval systems are usually biased to common semantics and seldom exploit diversity-aware regularization in training, which makes it difficult to promote diversity by post-processing. On the other hand, multi-vector representation methods are not guaranteed to learn robust multiple projections. As a result, irrelevant images and images of rare or unique semantics may be projected inappropriately, which degrades the relevance and diversity of the results generated by some typical algorithms like top-k. To cope with these problems, this paper presents a new method called CoLT that tries to generate much more representative and robust representations for accurately classifying images. Specifically, CoLT first extracts semantics-aware image features by enhancing the preliminary representations of an existing one-to-one cross-modal system with semantics-aware contrastive learning. Then, a transformer-based token classifier is developed to subsume all the features into their corresponding categories. Finally, a post-processing algorithm is designed to retrieve images from each category to form the final retrieval result. Extensive experiments on two real-world datasets Div400 and Div150Cred show that CoLT can effectively boost diversity, and outperforms the existing methods as a whole (with a higher F1 score).
Adaptive Rotated Convolution for Rotated Object Detection
Mar 14, 2023



Rotated object detection aims to identify and locate objects in images with arbitrary orientation. In this scenario, the oriented directions of objects vary considerably across different images, while multiple orientations of objects exist within an image. This intrinsic characteristic makes it challenging for standard backbone networks to extract high-quality features of these arbitrarily orientated objects. In this paper, we present Adaptive Rotated Convolution (ARC) module to handle the aforementioned challenges. In our ARC module, the convolution kernels rotate adaptively to extract object features with varying orientations in different images, and an efficient conditional computation mechanism is introduced to accommodate the large orientation variations of objects within an image. The two designs work seamlessly in rotated object detection problem. Moreover, ARC can conveniently serve as a plug-and-play module in various vision backbones to boost their representation ability to detect oriented objects accurately. Experiments on commonly used benchmarks (DOTA and HRSC2016) demonstrate that equipped with our proposed ARC module in the backbone network, the performance of multiple popular oriented object detectors is significantly improved (e.g. +3.03% mAP on Rotated RetinaNet and +4.16% on CFA). Combined with the highly competitive method Oriented R-CNN, the proposed approach achieves state-of-the-art performance on the DOTA dataset with 81.77% mAP.
Weighted Sum Secrecy Rate Maximization for RIS-Assisted Full Duplex systems
Jun 17, 2022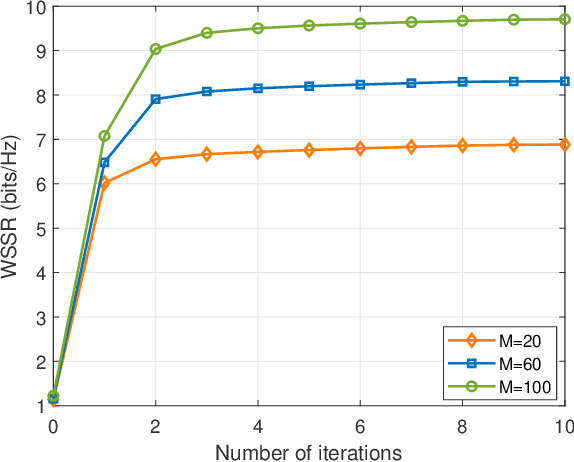
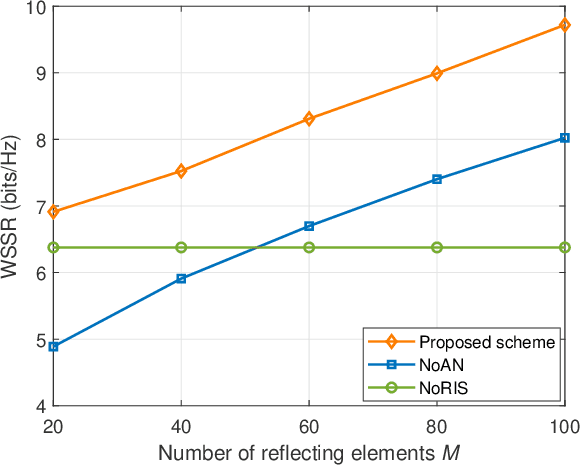
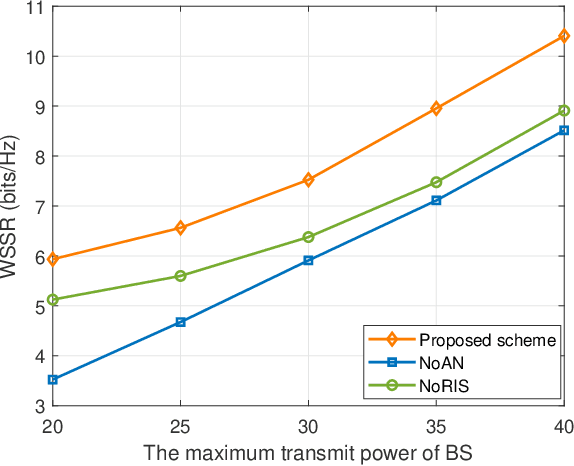
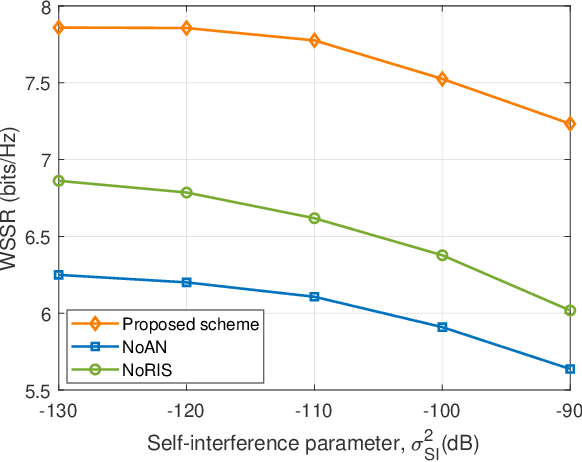
This letter considers the secure communication in a reconfigurable intelligent surface (RIS) aided full duplex (FD) system. A FD base station (BS) serves an uplink (UL) user and a downlink (DL) user simultaneously over the same timefrequency dimension assisted by a RIS in the presence of an eavesdropper. In addition, the BS transmits artificial noise (AN) to interfere the eavesdropper's channel. We aim to maximize the weighted sum secrecy rate of UL and DL users by jointly optimizing the transmit beamforming, receive beamforming and AN covariance matrix at the BS, and passive beamforming at the RIS. To handle the non-convex problem, we decompose it into tractable subproblems and propose an efficient algorithm based on alternating optimization framework. Specifically, the receive beamforming is derived as a closed-form solution while other variables are obtained by using semidefinite relaxation (SDR) method and successive convex approximation (SCA) algorithm. Simulation results demonstrate the superior performance of our proposed scheme compared to other baseline schemes.
Denial-of-Service Attacks on Learned Image Compression
May 26, 2022
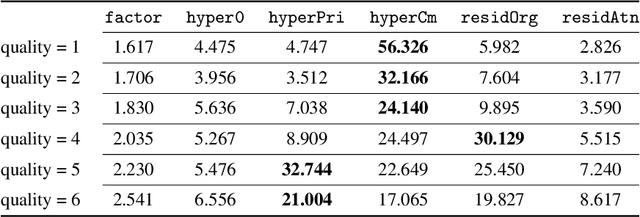
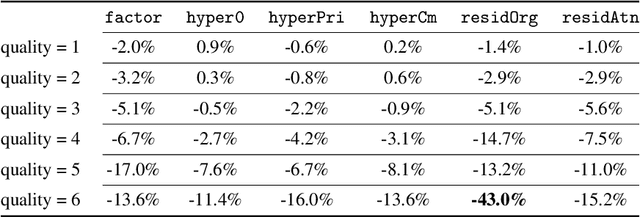

Deep learning techniques have shown promising results in image compression, with competitive bitrate and image reconstruction quality from compressed latent. However, while image compression has progressed towards higher peak signal-to-noise ratio (PSNR) and fewer bits per pixel (bpp), their robustness to corner-case images has never received deliberation. In this work, we, for the first time, investigate the robustness of image compression systems where imperceptible perturbation of input images can precipitate a significant increase in the bitrate of their compressed latent. To characterize the robustness of state-of-the-art learned image compression, we mount white and black-box attacks. Our results on several image compression models with various bitrate qualities show that they are surprisingly fragile, where the white-box attack achieves up to 56.326x and black-box 1.947x bpp change. To improve robustness, we propose a novel model which incorporates attention modules and a basic factorized entropy model, resulting in a promising trade-off between the PSNR/bpp ratio and robustness to adversarial attacks that surpasses existing learned image compressors.
Reconfigurable Intelligent Surfaces for Energy Efficiency in Full-duplex Communication System
May 24, 2022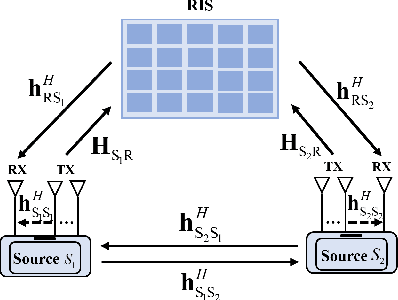
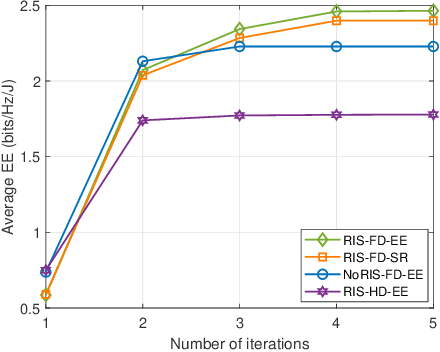
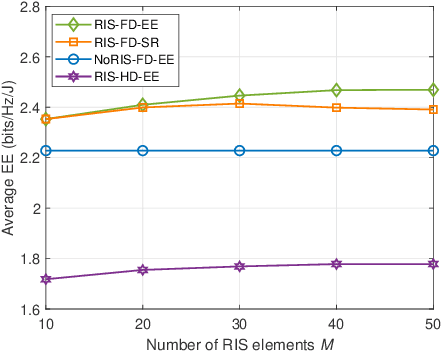
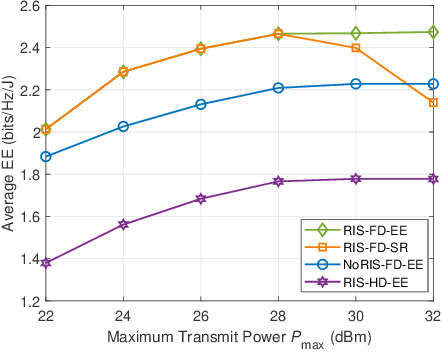
In this letter, we study the reconfigurable intelligent surfaces (RIS) aided full-duplex (FD) communication system. By jointly designing the active beamforming of two multi-antenna sources and passive beamforming of RIS, we aim to maximize the energy efficiency of the system, where extra self-interference cancellation power consumption in FD system is also considered. We divide the optimization problem into active and passive beamforming design subproblems, and adopt the alternative optimization framework to solve them iteratively. Dinkelbach's method is used to tackle the fractional objective function in active beamforming problem. Penalty method and successive convex approximation are exploited for passive beamforming design. Simulation results show the energy efficiency of our scheme outperforms other benchmarks.