 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoll the dice & look before you leap: Going beyond the creative limits of next-token prediction
Apr 21, 2025



We design a suite of minimal algorithmic tasks that are a loose abstraction of open-ended real-world tasks. This allows us to cleanly and controllably quantify the creative limits of the present-day language model. Much like real-world tasks that require a creative, far-sighted leap of thought, our tasks require an implicit, open-ended stochastic planning step that either (a) discovers new connections in an abstract knowledge graph (like in wordplay, drawing analogies, or research) or (b) constructs new patterns (like in designing math problems or new proteins). In these tasks, we empirically and conceptually argue how next-token learning is myopic and memorizes excessively; comparatively, multi-token approaches, namely teacherless training and diffusion models, excel in producing diverse and original output. Secondly, in our tasks, we find that to elicit randomness from the Transformer without hurting coherence, it is better to inject noise right at the input layer (via a method we dub hash-conditioning) rather than defer to temperature sampling from the output layer. Thus, our work offers a principled, minimal test-bed for analyzing open-ended creative skills, and offers new arguments for going beyond next-token learning and softmax-based sampling. We make part of the code available under https://github.com/chenwu98/algorithmic-creativity
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Oct 24, 2024



Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
Modeling the Biological Pathology Continuum with HSIC-regularized Wasserstein Auto-encoders
Jan 20, 2019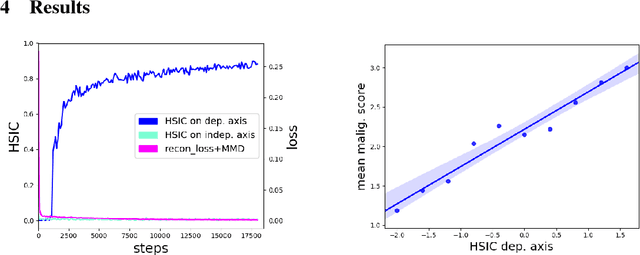
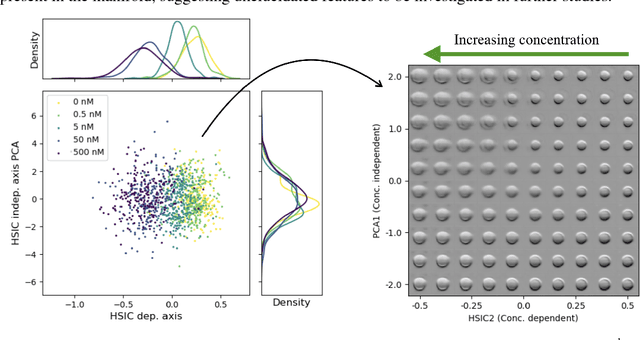
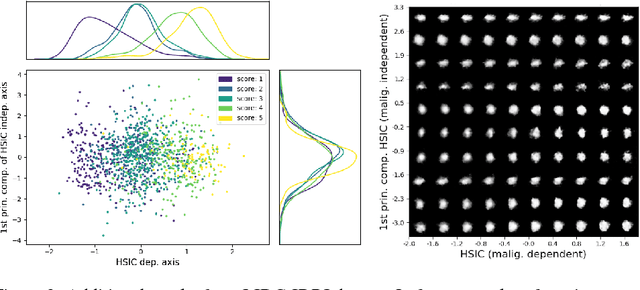
A crucial challenge in image-based modeling of biomedical data is to identify trends and features that separate normality and pathology. In many cases, the morphology of the imaged object exhibits continuous change as it deviates from normality, and thus a generative model can be trained to model this morphological continuum. Moreover, given side information that correlates to certain trend in morphological change, a latent variable model can be regularized such that its latent representation reflects this side information. In this work, we use the Wasserstein Auto-encoder to model this pathology continuum, and apply the Hilbert-Schmitt Independence Criterion (HSIC) to enforce dependency between certain latent features and the provided side information. We experimentally show that the model can provide disentangled and interpretable latent representations and also generate a continuum of morphological changes that corresponds to change in the side information.