 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-CARD: Efficient and Robust Codec Avatar Driving for Real-time Mobile Telepresence
Apr 24, 2023



Real-time and robust photorealistic avatars for telepresence in AR/VR have been highly desired for enabling immersive photorealistic telepresence. However, there still exists one key bottleneck: the considerable computational expense needed to accurately infer facial expressions captured from headset-mounted cameras with a quality level that can match the realism of the avatar's human appearance. To this end, we propose a framework called Auto-CARD, which for the first time enables real-time and robust driving of Codec Avatars when exclusively using merely on-device computing resources. This is achieved by minimizing two sources of redundancy. First, we develop a dedicated neural architecture search technique called AVE-NAS for avatar encoding in AR/VR, which explicitly boosts both the searched architectures' robustness in the presence of extreme facial expressions and hardware friendliness on fast evolving AR/VR headsets. Second, we leverage the temporal redundancy in consecutively captured images during continuous rendering and develop a mechanism dubbed LATEX to skip the computation of redundant frames. Specifically, we first identify an opportunity from the linearity of the latent space derived by the avatar decoder and then propose to perform adaptive latent extrapolation for redundant frames. For evaluation, we demonstrate the efficacy of our Auto-CARD framework in real-time Codec Avatar driving settings, where we achieve a 5.05x speed-up on Meta Quest 2 while maintaining a comparable or even better animation quality than state-of-the-art avatar encoder designs.
Robust Tickets Can Transfer Better: Drawing More Transferable Subnetworks in Transfer Learning
Apr 24, 2023Transfer learning leverages feature representations of deep neural networks (DNNs) pretrained on source tasks with rich data to empower effective finetuning on downstream tasks. However, the pretrained models are often prohibitively large for delivering generalizable representations, which limits their deployment on edge devices with constrained resources. To close this gap, we propose a new transfer learning pipeline, which leverages our finding that robust tickets can transfer better, i.e., subnetworks drawn with properly induced adversarial robustness can win better transferability over vanilla lottery ticket subnetworks. Extensive experiments and ablation studies validate that our proposed transfer learning pipeline can achieve enhanced accuracy-sparsity trade-offs across both diverse downstream tasks and sparsity patterns, further enriching the lottery ticket hypothesis.
ERSAM: Neural Architecture Search For Energy-Efficient and Real-Time Social Ambiance Measurement
Mar 24, 2023Social ambiance describes the context in which social interactions happen, and can be measured using speech audio by counting the number of concurrent speakers. This measurement has enabled various mental health tracking and human-centric IoT applications. While on-device Socal Ambiance Measure (SAM) is highly desirable to ensure user privacy and thus facilitate wide adoption of the aforementioned applications, the required computational complexity of state-of-the-art deep neural networks (DNNs) powered SAM solutions stands at odds with the often constrained resources on mobile devices. Furthermore, only limited labeled data is available or practical when it comes to SAM under clinical settings due to various privacy constraints and the required human effort, further challenging the achievable accuracy of on-device SAM solutions. To this end, we propose a dedicated neural architecture search framework for Energy-efficient and Real-time SAM (ERSAM). Specifically, our ERSAM framework can automatically search for DNNs that push forward the achievable accuracy vs. hardware efficiency frontier of mobile SAM solutions. For example, ERSAM-delivered DNNs only consume 40 mW x 12 h energy and 0.05 seconds processing latency for a 5 seconds audio segment on a Pixel 3 phone, while only achieving an error rate of 14.3% on a social ambiance dataset generated by LibriSpeech. We can expect that our ERSAM framework can pave the way for ubiquitous on-device SAM solutions which are in growing demand.
INGeo: Accelerating Instant Neural Scene Reconstruction with Noisy Geometry Priors
Dec 05, 2022



We present a method that accelerates reconstruction of 3D scenes and objects, aiming to enable instant reconstruction on edge devices such as mobile phones and AR/VR headsets. While recent works have accelerated scene reconstruction training to minute/second-level on high-end GPUs, there is still a large gap to the goal of instant training on edge devices which is yet highly desired in many emerging applications such as immersive AR/VR. To this end, this work aims to further accelerate training by leveraging geometry priors of the target scene. Our method proposes strategies to alleviate the noise of the imperfect geometry priors to accelerate the training speed on top of the highly optimized Instant-NGP. On the NeRF Synthetic dataset, our work uses half of the training iterations to reach an average test PSNR of >30.
Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Nov 18, 2022



Vision Transformers (ViTs) have shown impressive performance but still require a high computation cost as compared to convolutional neural networks (CNNs), due to the global similarity measurements and thus a quadratic complexity with the input tokens. Existing efficient ViTs adopt local attention (e.g., Swin) or linear attention (e.g., Performer), which sacrifice ViTs' capabilities of capturing either global or local context. In this work, we ask an important research question: Can ViTs learn both global and local context while being more efficient during inference? To this end, we propose a framework called Castling-ViT, which trains ViTs using both linear-angular attention and masked softmax-based quadratic attention, but then switches to having only linear angular attention during ViT inference. Our Castling-ViT leverages angular kernels to measure the similarities between queries and keys via spectral angles. And we further simplify it with two techniques: (1) a novel linear-angular attention mechanism: we decompose the angular kernels into linear terms and high-order residuals, and only keep the linear terms; and (2) we adopt two parameterized modules to approximate high-order residuals: a depthwise convolution and an auxiliary masked softmax attention to help learn both global and local information, where the masks for softmax attention are regularized to gradually become zeros and thus incur no overhead during ViT inference. Extensive experiments and ablation studies on three tasks consistently validate the effectiveness of the proposed Castling-ViT, e.g., achieving up to a 1.8% higher accuracy or 40% MACs reduction on ImageNet classification and 1.2 higher mAP on COCO detection under comparable FLOPs, as compared to ViTs with vanilla softmax-based attentions.
ViTALiTy: Unifying Low-rank and Sparse Approximation for Vision Transformer Acceleration with a Linear Taylor Attention
Nov 09, 2022Vision Transformer (ViT) has emerged as a competitive alternative to convolutional neural networks for various computer vision applications. Specifically, ViT multi-head attention layers make it possible to embed information globally across the overall image. Nevertheless, computing and storing such attention matrices incurs a quadratic cost dependency on the number of patches, limiting its achievable efficiency and scalability and prohibiting more extensive real-world ViT applications on resource-constrained devices. Sparse attention has been shown to be a promising direction for improving hardware acceleration efficiency for NLP models. However, a systematic counterpart approach is still missing for accelerating ViT models. To close the above gap, we propose a first-of-its-kind algorithm-hardware codesigned framework, dubbed ViTALiTy, for boosting the inference efficiency of ViTs. Unlike sparsity-based Transformer accelerators for NLP, ViTALiTy unifies both low-rank and sparse components of the attention in ViTs. At the algorithm level, we approximate the dot-product softmax operation via first-order Taylor attention with row-mean centering as the low-rank component to linearize the cost of attention blocks and further boost the accuracy by incorporating a sparsity-based regularization. At the hardware level, we develop a dedicated accelerator to better leverage the resulting workload and pipeline from ViTALiTy's linear Taylor attention which requires the execution of only the low-rank component, to further boost the hardware efficiency. Extensive experiments and ablation studies validate that ViTALiTy offers boosted end-to-end efficiency (e.g., $3\times$ faster and $3\times$ energy-efficient) under comparable accuracy, with respect to the state-of-the-art solution.
Losses Can Be Blessings: Routing Self-Supervised Speech Representations Towards Efficient Multilingual and Multitask Speech Processing
Nov 02, 2022



Self-supervised learning (SSL) for rich speech representations has achieved empirical success in low-resource Automatic Speech Recognition (ASR) and other speech processing tasks, which can mitigate the necessity of a large amount of transcribed speech and thus has driven a growing demand for on-device ASR and other speech processing. However, advanced speech SSL models have become increasingly large, which contradicts the limited on-device resources. This gap could be more severe in multilingual/multitask scenarios requiring simultaneously recognizing multiple languages or executing multiple speech processing tasks. Additionally, strongly overparameterized speech SSL models tend to suffer from overfitting when being finetuned on low-resource speech corpus. This work aims to enhance the practical usage of speech SSL models towards a win-win in both enhanced efficiency and alleviated overfitting via our proposed S$^3$-Router framework, which for the first time discovers that simply discarding no more than 10\% of model weights via only finetuning model connections of speech SSL models can achieve better accuracy over standard weight finetuning on downstream speech processing tasks. More importantly, S$^3$-Router can serve as an all-in-one technique to enable (1) a new finetuning scheme, (2) an efficient multilingual/multitask solution, (3) a state-of-the-art ASR pruning technique, and (4) a new tool to quantitatively analyze the learned speech representation. We believe S$^3$-Router has provided a new perspective for practical deployment of speech SSL models. Our codes are available at: https://github.com/GATECH-EIC/S3-Router.
NASA: Neural Architecture Search and Acceleration for Hardware Inspired Hybrid Networks
Oct 24, 2022



Multiplication is arguably the most cost-dominant operation in modern deep neural networks (DNNs), limiting their achievable efficiency and thus more extensive deployment in resource-constrained applications. To tackle this limitation, pioneering works have developed handcrafted multiplication-free DNNs, which require expert knowledge and time-consuming manual iteration, calling for fast development tools. To this end, we propose a Neural Architecture Search and Acceleration framework dubbed NASA, which enables automated multiplication-reduced DNN development and integrates a dedicated multiplication-reduced accelerator for boosting DNNs' achievable efficiency. Specifically, NASA adopts neural architecture search (NAS) spaces that augment the state-of-the-art one with hardware-inspired multiplication-free operators, such as shift and adder, armed with a novel progressive pretrain strategy (PGP) together with customized training recipes to automatically search for optimal multiplication-reduced DNNs; On top of that, NASA further develops a dedicated accelerator, which advocates a chunk-based template and auto-mapper dedicated for NASA-NAS resulting DNNs to better leverage their algorithmic properties for boosting hardware efficiency. Experimental results and ablation studies consistently validate the advantages of NASA's algorithm-hardware co-design framework in terms of achievable accuracy and efficiency tradeoffs. Codes are available at https://github.com/RICE-EIC/NASA.
ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
Oct 18, 2022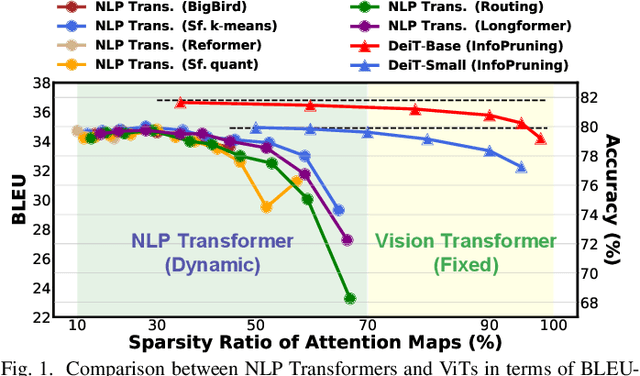
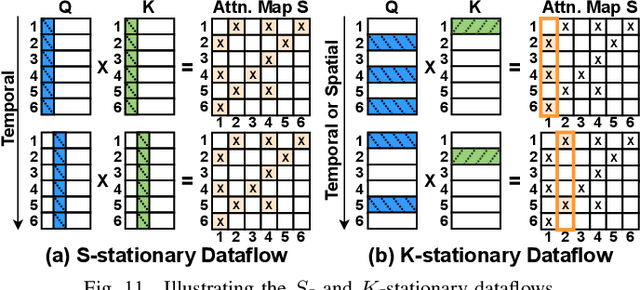
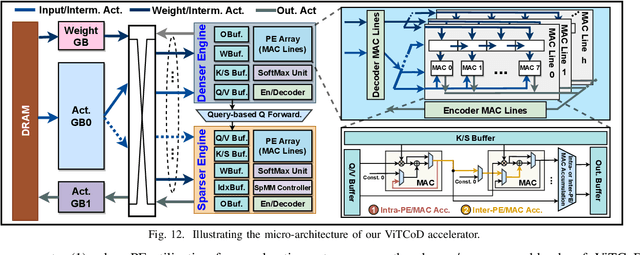
Vision Transformers (ViTs) have achieved state-of-the-art performance on various vision tasks. However, ViTs' self-attention module is still arguably a major bottleneck, limiting their achievable hardware efficiency. Meanwhile, existing accelerators dedicated to NLP Transformers are not optimal for ViTs. This is because there is a large difference between ViTs and NLP Transformers: ViTs have a relatively fixed number of input tokens, whose attention maps can be pruned by up to 90% even with fixed sparse patterns; while NLP Transformers need to handle input sequences of varying numbers of tokens and rely on on-the-fly predictions of dynamic sparse attention patterns for each input to achieve a decent sparsity (e.g., >=50%). To this end, we propose a dedicated algorithm and accelerator co-design framework dubbed ViTCoD for accelerating ViTs. Specifically, on the algorithm level, ViTCoD prunes and polarizes the attention maps to have either denser or sparser fixed patterns for regularizing two levels of workloads without hurting the accuracy, largely reducing the attention computations while leaving room for alleviating the remaining dominant data movements; on top of that, we further integrate a lightweight and learnable auto-encoder module to enable trading the dominant high-cost data movements for lower-cost computations. On the hardware level, we develop a dedicated accelerator to simultaneously coordinate the enforced denser/sparser workloads and encoder/decoder engines for boosted hardware utilization. Extensive experiments and ablation studies validate that ViTCoD largely reduces the dominant data movement costs, achieving speedups of up to 235.3x, 142.9x, 86.0x, 10.1x, and 6.8x over general computing platforms CPUs, EdgeGPUs, GPUs, and prior-art Transformer accelerators SpAtten and Sanger under an attention sparsity of 90%, respectively.
SuperTickets: Drawing Task-Agnostic Lottery Tickets from Supernets via Jointly Architecture Searching and Parameter Pruning
Jul 08, 2022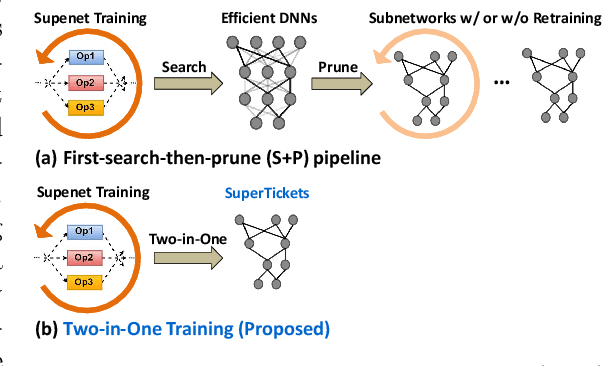
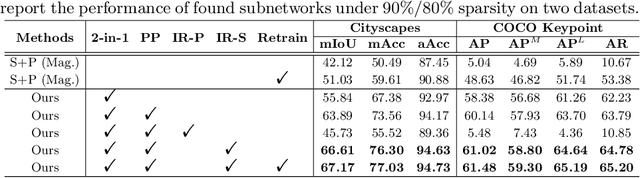
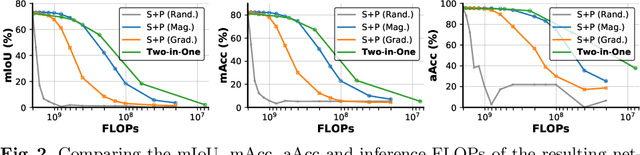
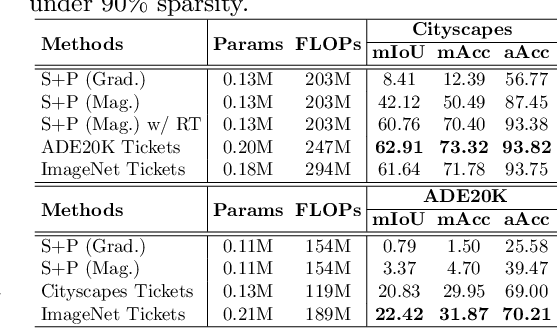
Neural architecture search (NAS) has demonstrated amazing success in searching for efficient deep neural networks (DNNs) from a given supernet. In parallel, the lottery ticket hypothesis has shown that DNNs contain small subnetworks that can be trained from scratch to achieve a comparable or higher accuracy than original DNNs. As such, it is currently a common practice to develop efficient DNNs via a pipeline of first search and then prune. Nevertheless, doing so often requires a search-train-prune-retrain process and thus prohibitive computational cost. In this paper, we discover for the first time that both efficient DNNs and their lottery subnetworks (i.e., lottery tickets) can be directly identified from a supernet, which we term as SuperTickets, via a two-in-one training scheme with jointly architecture searching and parameter pruning. Moreover, we develop a progressive and unified SuperTickets identification strategy that allows the connectivity of subnetworks to change during supernet training, achieving better accuracy and efficiency trade-offs than conventional sparse training. Finally, we evaluate whether such identified SuperTickets drawn from one task can transfer well to other tasks, validating their potential of handling multiple tasks simultaneously. Extensive experiments and ablation studies on three tasks and four benchmark datasets validate that our proposed SuperTickets achieve boosted accuracy and efficiency trade-offs than both typical NAS and pruning pipelines, regardless of having retraining or not. Codes and pretrained models are available at https://github.com/RICE-EIC/SuperTickets.