 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Data Denoising for Recommendation
May 26, 2023In real-world scenarios, most platforms collect both large-scale, naturally noisy implicit feedback and small-scale yet highly relevant explicit feedback. Due to the issue of data sparsity, implicit feedback is often the default choice for training recommender systems (RS), however, such data could be very noisy due to the randomness and diversity of user behaviors. For instance, a large portion of clicks may not reflect true user preferences and many purchases may result in negative reviews or returns. Fortunately, by utilizing the strengths of both types of feedback to compensate for the weaknesses of the other, we can mitigate the above issue at almost no cost. In this work, we propose an Automated Data Denoising framework, \textbf{\textit{AutoDenoise}}, for recommendation, which uses a small number of explicit data as validation set to guide the recommender training. Inspired by the generalized definition of curriculum learning (CL), AutoDenoise learns to automatically and dynamically assign the most appropriate (discrete or continuous) weights to each implicit data sample along the training process under the guidance of the validation performance. Specifically, we use a delicately designed controller network to generate the weights, combine the weights with the loss of each input data to train the recommender system, and optimize the controller with reinforcement learning to maximize the expected accuracy of the trained RS on the noise-free validation set. Thorough experiments indicate that AutoDenoise is able to boost the performance of the state-of-the-art recommendation algorithms on several public benchmark datasets.
UP5: Unbiased Foundation Model for Fairness-aware Recommendation
May 20, 2023



Recent advancements in foundation models such as large language models (LLM) have propelled them to the forefront of recommender systems (RS). Moreover, fairness in RS is critical since many users apply it for decision-making and demand fulfillment. However, at present, there is a lack of understanding regarding the level of fairness exhibited by recommendation foundation models and the appropriate methods for equitably treating different groups of users in foundation models. In this paper, we focus on user-side unfairness problem and show through a thorough examination that there is unfairness involved in LLMs that lead to unfair recommendation results. To eliminate bias from LLM for fairness-aware recommendation, we introduce a novel Unbiased P5 (UP5) foundation model based on Counterfactually-Fair-Prompting (CFP) techniques. CFP includes two sub-modules: a personalized prefix prompt that enhances fairness with respect to individual sensitive attributes, and a Prompt Mixture that integrates multiple counterfactually-fair prompts for a set of sensitive attributes. Experiments are conducted on two real-world datasets, MovieLens-1M and Insurance, and results are compared with both matching-based and sequential-based fairness-aware recommendation models. The results show that UP5 achieves better recommendation performance and meanwhile exhibits a high level of fairness.
How to Index Item IDs for Recommendation Foundation Models
May 12, 2023Recommendation foundation model utilizes large language models (LLM) for recommendation by converting recommendation tasks into natural language tasks. It enables generative recommendation which directly generates the item(s) to recommend rather than calculating a ranking score for each and every candidate item in traditional recommendation models, simplifying the recommendation pipeline from multi-stage filtering to single-stage filtering. To avoid generating excessively long text when deciding which item(s) to recommend, creating LLM-compatible item IDs is essential for recommendation foundation models. In this study, we systematically examine the item indexing problem for recommendation foundation models, using P5 as the representative backbone model and replicating its results with various indexing methods. To emphasize the importance of item indexing, we first discuss the issues of several trivial item indexing methods, such as independent indexing, title indexing, and random indexing. We then propose four simple yet effective solutions, including sequential indexing, collaborative indexing, semantic (content-based) indexing, and hybrid indexing. Our reproducibility study of P5 highlights the significant influence of item indexing methods on the model performance, and our results on real-world datasets validate the effectiveness of our proposed solutions.
OpenAGI: When LLM Meets Domain Experts
Apr 12, 2023



Human intelligence has the remarkable ability to assemble basic skills into complex ones so as to solve complex tasks. This ability is equally important for Artificial Intelligence (AI), and thus, we assert that in addition to the development of large, comprehensive intelligent models, it is equally crucial to equip such models with the capability to harness various domain-specific expert models for complex task-solving in the pursuit of Artificial General Intelligence (AGI). Recent developments in Large Language Models (LLMs) have demonstrated remarkable learning and reasoning abilities, making them promising as a controller to select, synthesize, and execute external models to solve complex tasks. In this project, we develop OpenAGI, an open-source AGI research platform, specifically designed to offer complex, multi-step tasks and accompanied by task-specific datasets, evaluation metrics, and a diverse range of extensible models. OpenAGI formulates complex tasks as natural language queries, serving as input to the LLM. The LLM subsequently selects, synthesizes, and executes models provided by OpenAGI to address the task. Furthermore, we propose a Reinforcement Learning from Task Feedback (RLTF) mechanism, which uses the task-solving result as feedback to improve the LLM's task-solving ability. Thus, the LLM is responsible for synthesizing various external models for solving complex tasks, while RLTF provides feedback to improve its task-solving ability, enabling a feedback loop for self-improving AI. We believe that the paradigm of LLMs operating various expert models for complex task-solving is a promising approach towards AGI. To facilitate the community's long-term improvement and evaluation of AGI's ability, we open-source the code, benchmark, and evaluation methods of the OpenAGI project at https://github.com/agiresearch/OpenAGI.
Fairness-aware Differentially Private Collaborative Filtering
Mar 16, 2023Recently, there has been an increasing adoption of differential privacy guided algorithms for privacy-preserving machine learning tasks. However, the use of such algorithms comes with trade-offs in terms of algorithmic fairness, which has been widely acknowledged. Specifically, we have empirically observed that the classical collaborative filtering method, trained by differentially private stochastic gradient descent (DP-SGD), results in a disparate impact on user groups with respect to different user engagement levels. This, in turn, causes the original unfair model to become even more biased against inactive users. To address the above issues, we propose \textbf{DP-Fair}, a two-stage framework for collaborative filtering based algorithms. Specifically, it combines differential privacy mechanisms with fairness constraints to protect user privacy while ensuring fair recommendations. The experimental results, based on Amazon datasets, and user history logs collected from Etsy, one of the largest e-commerce platforms, demonstrate that our proposed method exhibits superior performance in terms of both overall accuracy and user group fairness on both shallow and deep recommendation models compared to vanilla DP-SGD.
Causal Inference for Recommendation: Foundations, Methods and Applications
Jan 08, 2023



Recommender systems are important and powerful tools for various personalized services. Traditionally, these systems use data mining and machine learning techniques to make recommendations based on correlations found in the data. However, relying solely on correlation without considering the underlying causal mechanism may lead to various practical issues such as fairness, explainability, robustness, bias, echo chamber and controllability problems. Therefore, researchers in related area have begun incorporating causality into recommendation systems to address these issues. In this survey, we review the existing literature on causal inference in recommender systems. We discuss the fundamental concepts of both recommender systems and causal inference as well as their relationship, and review the existing work on causal methods for different problems in recommender systems. Finally, we discuss open problems and future directions in the field of causal inference for recommendations.
A Survey on Trustworthy Recommender Systems
Jul 25, 2022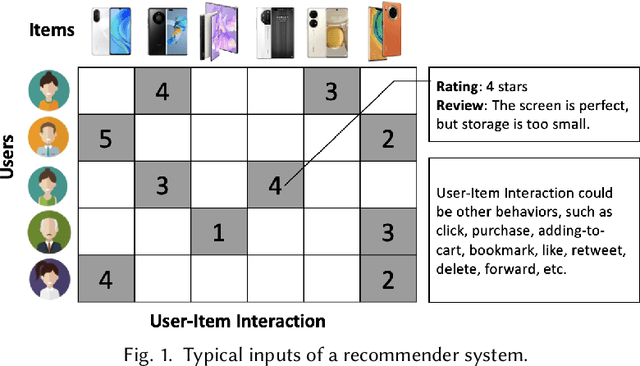


Recommender systems (RS), serving at the forefront of Human-centered AI, are widely deployed in almost every corner of the web and facilitate the human decision-making process. However, despite their enormous capabilities and potential, RS may also lead to undesired counter-effects on users, items, producers, platforms, or even the society at large, such as compromised user trust due to non-transparency, unfair treatment of different consumers, or producers, privacy concerns due to extensive use of user's private data for personalization, just to name a few. All of these create an urgent need for Trustworthy Recommender Systems (TRS) so as to mitigate or avoid such adverse impacts and risks. In this survey, we will introduce techniques related to trustworthy and responsible recommendation, including but not limited to explainable recommendation, fairness in recommendation, privacy-aware recommendation, robustness in recommendation, user controllable recommendation, as well as the relationship between these different perspectives in terms of trustworthy and responsible recommendation. Through this survey, we hope to deliver readers with a comprehensive view of the research area and raise attention to the community about the importance, existing research achievements, and future research directions on trustworthy recommendation.
Fairness in Recommendation: A Survey
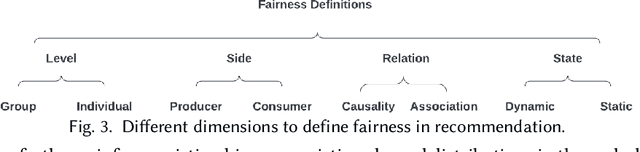
Jun 01, 2022
As one of the most pervasive applications of machine learning, recommender systems are playing an important role on assisting human decision making. The satisfaction of users and the interests of platforms are closely related to the quality of the generated recommendation results. However, as a highly data-driven system, recommender system could be affected by data or algorithmic bias and thus generate unfair results, which could weaken the reliance of the systems. As a result, it is crucial to address the potential unfairness problems in recommendation settings. Recently, there has been growing attention on fairness considerations in recommender systems with more and more literature on approaches to promote fairness in recommendation. However, the studies are rather fragmented and lack a systematic organization, thus making it difficult to penetrate for new researchers to the domain. This motivates us to provide a systematic survey of existing works on fairness in recommendation. This survey focuses on the foundations for fairness in recommendation literature. It first presents a brief introduction about fairness in basic machine learning tasks such as classification and ranking in order to provide a general overview of fairness research, as well as introduce the more complex situations and challenges that need to be considered when studying fairness in recommender systems. After that, the survey will introduce fairness in recommendation with a focus on the taxonomies of current fairness definitions, the typical techniques for improving fairness, as well as the datasets for fairness studies in recommendation. The survey also talks about the challenges and opportunities in fairness research with the hope of promoting the fair recommendation research area and beyond.
AutoLossGen: Automatic Loss Function Generation for Recommender Systems
Apr 27, 2022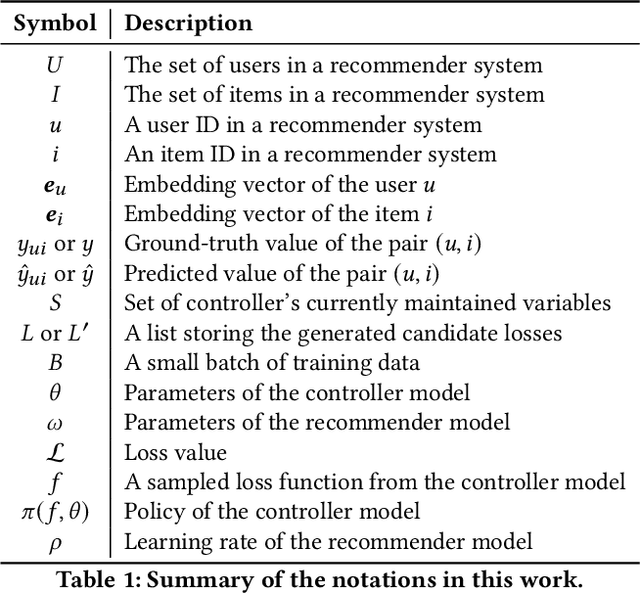
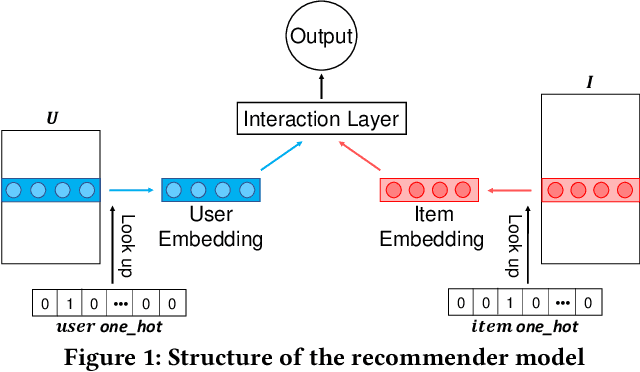

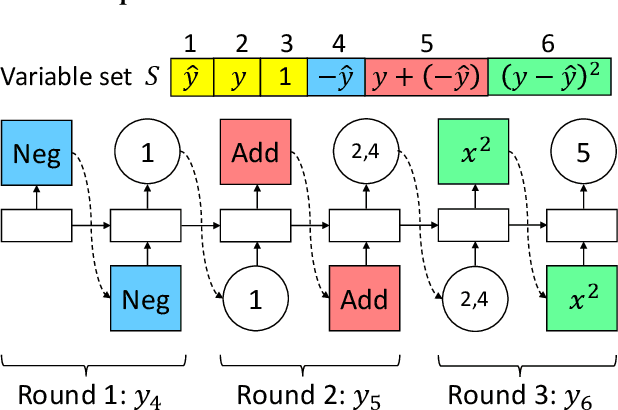
In recommendation systems, the choice of loss function is critical since a good loss may significantly improve the model performance. However, manually designing a good loss is a big challenge due to the complexity of the problem. A large fraction of previous work focuses on handcrafted loss functions, which needs significant expertise and human effort. In this paper, inspired by the recent development of automated machine learning, we propose an automatic loss function generation framework, AutoLossGen, which is able to generate loss functions directly constructed from basic mathematical operators without prior knowledge on loss structure. More specifically, we develop a controller model driven by reinforcement learning to generate loss functions, and develop iterative and alternating optimization schedule to update the parameters of both the controller model and the recommender model. One challenge for automatic loss generation in recommender systems is the extreme sparsity of recommendation datasets, which leads to the sparse reward problem for loss generation and search. To solve the problem, we further develop a reward filtering mechanism for efficient and effective loss generation. Experimental results show that our framework manages to create tailored loss functions for different recommendation models and datasets, and the generated loss gives better recommendation performance than commonly used baseline losses. Besides, most of the generated losses are transferable, i.e., the loss generated based on one model and dataset also works well for another model or dataset. Source code of the work is available at https://github.com/rutgerswiselab/AutoLossGen.
Explainable Fairness in Recommendation
Apr 24, 2022
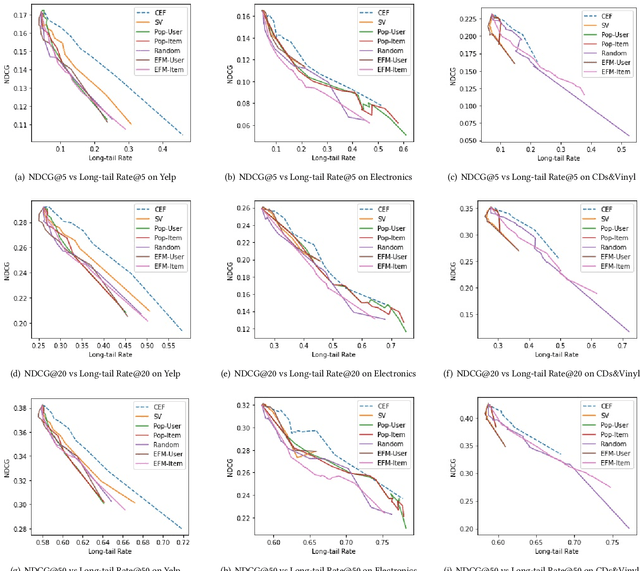
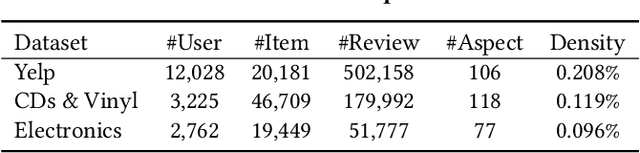
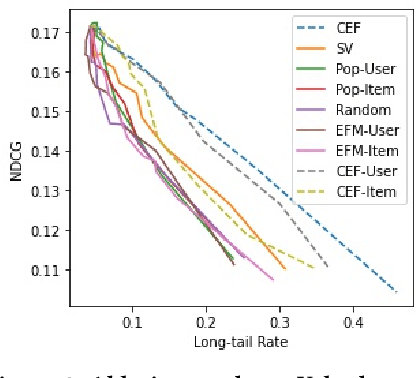
Existing research on fairness-aware recommendation has mainly focused on the quantification of fairness and the development of fair recommendation models, neither of which studies a more substantial problem--identifying the underlying reason of model disparity in recommendation. This information is critical for recommender system designers to understand the intrinsic recommendation mechanism and provides insights on how to improve model fairness to decision makers. Fortunately, with the rapid development of Explainable AI, we can use model explainability to gain insights into model (un)fairness. In this paper, we study the problem of explainable fairness, which helps to gain insights about why a system is fair or unfair, and guides the design of fair recommender systems with a more informed and unified methodology. Particularly, we focus on a common setting with feature-aware recommendation and exposure unfairness, but the proposed explainable fairness framework is general and can be applied to other recommendation settings and fairness definitions. We propose a Counterfactual Explainable Fairness framework, called CEF, which generates explanations about model fairness that can improve the fairness without significantly hurting the performance.The CEF framework formulates an optimization problem to learn the "minimal" change of the input features that changes the recommendation results to a certain level of fairness. Based on the counterfactual recommendation result of each feature, we calculate an explainability score in terms of the fairness-utility trade-off to rank all the feature-based explanations, and select the top ones as fairness explanations.