 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration-Aware Margin Loss: Pushing the Accuracy-Calibration Consistency Pareto Frontier for Deep Metric Learning
Jul 08, 2023



The ability to use the same distance threshold across different test classes / distributions is highly desired for a frictionless deployment of commercial image retrieval systems. However, state-of-the-art deep metric learning losses often result in highly varied intra-class and inter-class embedding structures, making threshold calibration a non-trivial process in practice. In this paper, we propose a novel metric named Operating-Point-Incosistency-Score (OPIS) that measures the variance in the operating characteristics across different classes in a target calibration range, and demonstrate that high accuracy of a metric learning embedding model does not guarantee calibration consistency for both seen and unseen classes. We find that, in the high-accuracy regime, there exists a Pareto frontier where accuracy improvement comes at the cost of calibration consistency. To address this, we develop a novel regularization, named Calibration-Aware Margin (CAM) loss, to encourage uniformity in the representation structures across classes during training. Extensive experiments demonstrate CAM's effectiveness in improving calibration-consistency while retaining or even enhancing accuracy, outperforming state-of-the-art deep metric learning methods.
Learning Joint Latent Space EBM Prior Model for Multi-layer Generator
Jun 10, 2023This paper studies the fundamental problem of learning multi-layer generator models. The multi-layer generator model builds multiple layers of latent variables as a prior model on top of the generator, which benefits learning complex data distribution and hierarchical representations. However, such a prior model usually focuses on modeling inter-layer relations between latent variables by assuming non-informative (conditional) Gaussian distributions, which can be limited in model expressivity. To tackle this issue and learn more expressive prior models, we propose an energy-based model (EBM) on the joint latent space over all layers of latent variables with the multi-layer generator as its backbone. Such joint latent space EBM prior model captures the intra-layer contextual relations at each layer through layer-wise energy terms, and latent variables across different layers are jointly corrected. We develop a joint training scheme via maximum likelihood estimation (MLE), which involves Markov Chain Monte Carlo (MCMC) sampling for both prior and posterior distributions of the latent variables from different layers. To ensure efficient inference and learning, we further propose a variational training scheme where an inference model is used to amortize the costly posterior MCMC sampling. Our experiments demonstrate that the learned model can be expressive in generating high-quality images and capturing hierarchical features for better outlier detection.
Molecule Design by Latent Space Energy-Based Modeling and Gradual Distribution Shifting
Jun 09, 2023Generation of molecules with desired chemical and biological properties such as high drug-likeness, high binding affinity to target proteins, is critical for drug discovery. In this paper, we propose a probabilistic generative model to capture the joint distribution of molecules and their properties. Our model assumes an energy-based model (EBM) in the latent space. Conditional on the latent vector, the molecule and its properties are modeled by a molecule generation model and a property regression model respectively. To search for molecules with desired properties, we propose a sampling with gradual distribution shifting (SGDS) algorithm, so that after learning the model initially on the training data of existing molecules and their properties, the proposed algorithm gradually shifts the model distribution towards the region supported by molecules with desired values of properties. Our experiments show that our method achieves very strong performances on various molecule design tasks.
Diverse and Faithful Knowledge-Grounded Dialogue Generation via Sequential Posterior Inference
Jun 01, 2023



The capability to generate responses with diversity and faithfulness using factual knowledge is paramount for creating a human-like, trustworthy dialogue system. Common strategies either adopt a two-step paradigm, which optimizes knowledge selection and response generation separately, and may overlook the inherent correlation between these two tasks, or leverage conditional variational method to jointly optimize knowledge selection and response generation by employing an inference network. In this paper, we present an end-to-end learning framework, termed Sequential Posterior Inference (SPI), capable of selecting knowledge and generating dialogues by approximately sampling from the posterior distribution. Unlike other methods, SPI does not require the inference network or assume a simple geometry of the posterior distribution. This straightforward and intuitive inference procedure of SPI directly queries the response generation model, allowing for accurate knowledge selection and generation of faithful responses. In addition to modeling contributions, our experimental results on two common dialogue datasets (Wizard of Wikipedia and Holl-E) demonstrate that SPI outperforms previous strong baselines according to both automatic and human evaluation metrics.
Learning for Open-World Calibration with Graph Neural Networks
May 19, 2023



We tackle the problem of threshold calibration for open-world recognition by incorporating representation compactness measures into clustering. Unlike the open-set recognition which focuses on discovering and rejecting the unknown, open-world recognition learns robust representations that are generalizable to disjoint unknown classes at test time. Our proposed method is based on two key observations: (i) representation structures among neighbouring images in high dimensional visual embedding spaces have strong self-similarity which can be leveraged to encourage transferability to the open world, (ii) intra-class embedding structures can be modeled with the marginalized von Mises-Fisher (vMF) probability, whose correlation with the true positive rate is dataset-invariant. Motivated by these, we design a unified framework centered around a graph neural network (GNN) to jointly predict the pseudo-labels and the vMF concentrations which indicate the representation compactness. These predictions can be converted into statistical estimations for recognition accuracy, allowing more robust calibration of the distance threshold to achieve target utility for the open-world classes. Results on a variety of visual recognition benchmarks demonstrate the superiority of our method over traditional posthoc calibration methods for the open world, especially under distribution shift.
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
Apr 19, 2023Large language models (LLMs) have achieved remarkable progress in various natural language processing tasks with emergent abilities. However, they face inherent limitations, such as an inability to access up-to-date information, utilize external tools, or perform precise mathematical reasoning. In this paper, we introduce Chameleon, a plug-and-play compositional reasoning framework that augments LLMs to help address these challenges. Chameleon synthesizes programs to compose various tools, including LLM models, off-the-shelf vision models, web search engines, Python functions, and rule-based modules tailored to user interests. Built on top of an LLM as a natural language planner, Chameleon infers the appropriate sequence of tools to compose and execute in order to generate a final response. We showcase the adaptability and effectiveness of Chameleon on two tasks: ScienceQA and TabMWP. Notably, Chameleon with GPT-4 achieves an 86.54% accuracy on ScienceQA, significantly improving upon the best published few-shot model by 11.37%; using GPT-4 as the underlying LLM, Chameleon achieves a 17.8% increase over the state-of-the-art model, leading to a 98.78% overall accuracy on TabMWP. Further studies suggest that using GPT-4 as a planner exhibits more consistent and rational tool selection and is able to infer potential constraints given the instructions, compared to other LLMs like ChatGPT.
On the Complexity of Bayesian Generalization
Nov 26, 2022



We consider concept generalization at a large scale in the diverse and natural visual spectrum. Established computational modes (i.e., rule-based or similarity-based) are primarily studied isolated and focus on confined and abstract problem spaces. In this work, we study these two modes when the problem space scales up, and the $complexity$ of concepts becomes diverse. Specifically, at the $representational \ level$, we seek to answer how the complexity varies when a visual concept is mapped to the representation space. Prior psychology literature has shown that two types of complexities (i.e., subjective complexity and visual complexity) (Griffiths and Tenenbaum, 2003) build an inverted-U relation (Donderi, 2006; Sun and Firestone, 2021). Leveraging Representativeness of Attribute (RoA), we computationally confirm the following observation: Models use attributes with high RoA to describe visual concepts, and the description length falls in an inverted-U relation with the increment in visual complexity. At the $computational \ level$, we aim to answer how the complexity of representation affects the shift between the rule- and similarity-based generalization. We hypothesize that category-conditioned visual modeling estimates the co-occurrence frequency between visual and categorical attributes, thus potentially serving as the prior for the natural visual world. Experimental results show that representations with relatively high subjective complexity outperform those with relatively low subjective complexity in the rule-based generalization, while the trend is the opposite in the similarity-based generalization.
SpectraNet: Multivariate Forecasting and Imputation under Distribution Shifts and Missing Data
Oct 25, 2022



In this work, we tackle two widespread challenges in real applications for time-series forecasting that have been largely understudied: distribution shifts and missing data. We propose SpectraNet, a novel multivariate time-series forecasting model that dynamically infers a latent space spectral decomposition to capture current temporal dynamics and correlations on the recent observed history. A Convolution Neural Network maps the learned representation by sequentially mixing its components and refining the output. Our proposed approach can simultaneously produce forecasts and interpolate past observations and can, therefore, greatly simplify production systems by unifying imputation and forecasting tasks into a single model. SpectraNet achieves SoTA performance simultaneously on both tasks on five benchmark datasets, compared to forecasting and imputation models, with up to 92% fewer parameters and comparable training times. On settings with up to 80% missing data, SpectraNet has average performance improvements of almost 50% over the second-best alternative. Our code is available at https://github.com/cchallu/spectranet.
Conformal Isometry of Lie Group Representation in Recurrent Network of Grid Cells
Oct 06, 2022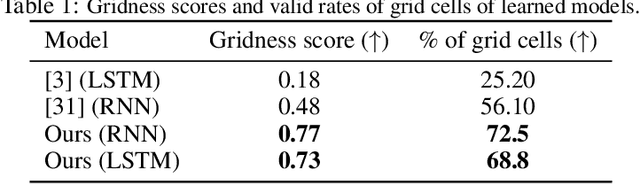

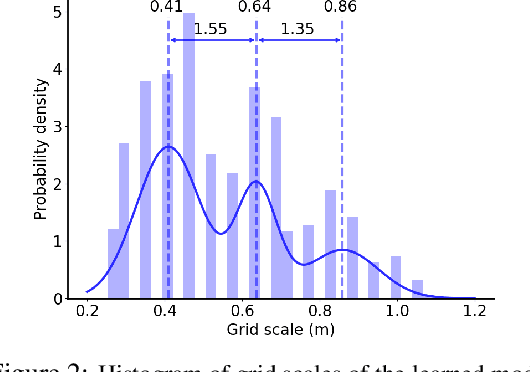
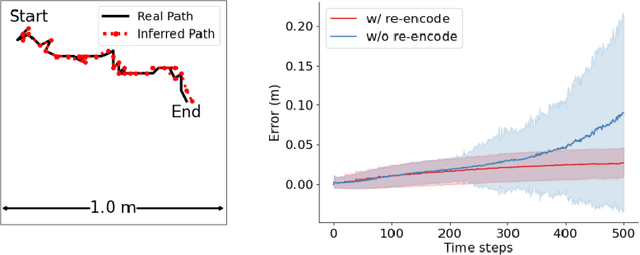
The activity of the grid cell population in the medial entorhinal cortex (MEC) of the brain forms a vector representation of the self-position of the animal. Recurrent neural networks have been developed to explain the properties of the grid cells by transforming the vector based on the input velocity, so that the grid cells can perform path integration. In this paper, we investigate the algebraic, geometric, and topological properties of grid cells using recurrent network models. Algebraically, we study the Lie group and Lie algebra of the recurrent transformation as a representation of self-motion. Geometrically, we study the conformal isometry of the Lie group representation of the recurrent network where the local displacement of the vector in the neural space is proportional to the local displacement of the agent in the 2D physical space. We then focus on a simple non-linear recurrent model that underlies the continuous attractor neural networks of grid cells. Our numerical experiments show that conformal isometry leads to hexagon periodic patterns of the response maps of grid cells and our model is capable of accurate path integration.
Neural-Symbolic Recursive Machine for Systematic Generalization
Oct 04, 2022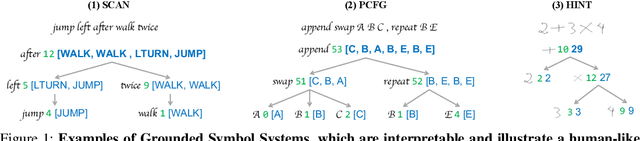
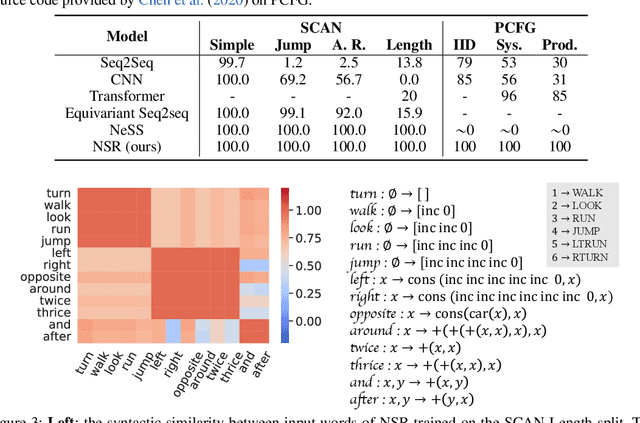
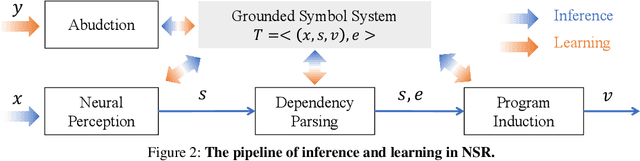
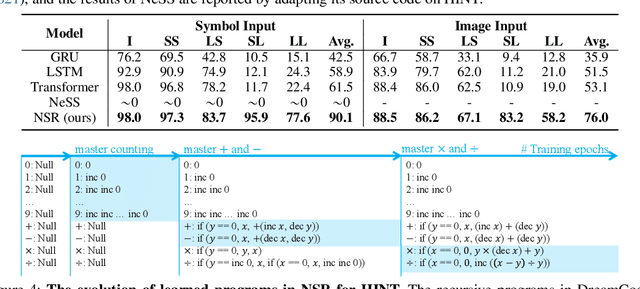
Despite the tremendous success, existing machine learning models still fall short of human-like systematic generalization -- learning compositional rules from limited data and applying them to unseen combinations in various domains. We propose Neural-Symbolic Recursive Machine (NSR) to tackle this deficiency. The core representation of NSR is a Grounded Symbol System (GSS) with combinatorial syntax and semantics, which entirely emerges from training data. Akin to the neuroscience studies suggesting separate brain systems for perceptual, syntactic, and semantic processing, NSR implements analogous separate modules of neural perception, syntactic parsing, and semantic reasoning, which are jointly learned by a deduction-abduction algorithm. We prove that NSR is expressive enough to model various sequence-to-sequence tasks. Superior systematic generalization is achieved via the inductive biases of equivariance and recursiveness embedded in NSR. In experiments, NSR achieves state-of-the-art performance in three benchmarks from different domains: SCAN for semantic parsing, PCFG for string manipulation, and HINT for arithmetic reasoning. Specifically, NSR achieves 100% generalization accuracy on SCAN and PCFG and outperforms state-of-the-art models on HINT by about 23%. Our NSR demonstrates stronger generalization than pure neural networks due to its symbolic representation and inductive biases. NSR also demonstrates better transferability than existing neural-symbolic approaches due to less domain-specific knowledge required.