 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Model-Free Reinforcement Learning Using Gaussian Process
Dec 11, 2018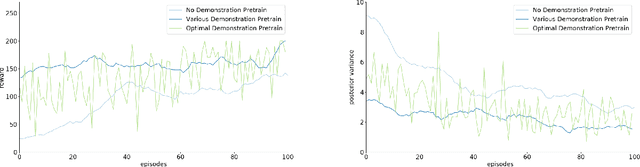
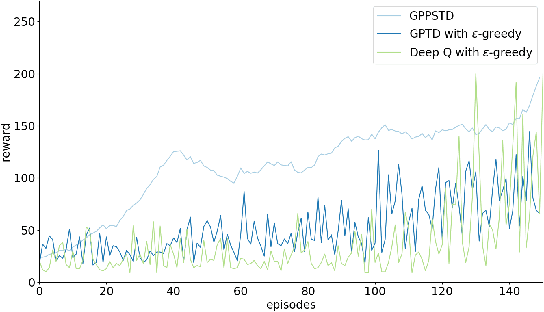
Efficient Reinforcement Learning usually takes advantage of demonstration or good exploration strategy. By applying posterior sampling in model-free RL under the hypothesis of GP, we propose Gaussian Process Posterior Sampling Reinforcement Learning(GPPSTD) algorithm in continuous state space, giving theoretical justifications and empirical results. We also provide theoretical and empirical results that various demonstration could lower expected uncertainty and benefit posterior sampling exploration. In this way, we combined the demonstration and exploration process together to achieve a more efficient reinforcement learning.
Deep Interest Evolution Network for Click-Through Rate Prediction
Nov 06, 2018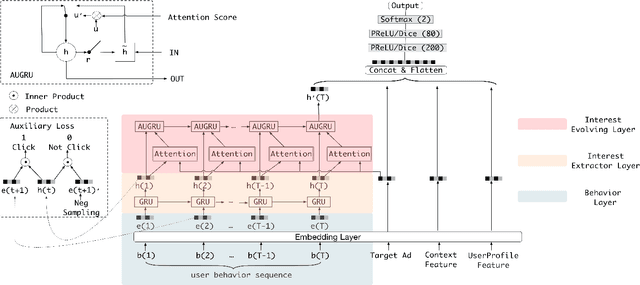

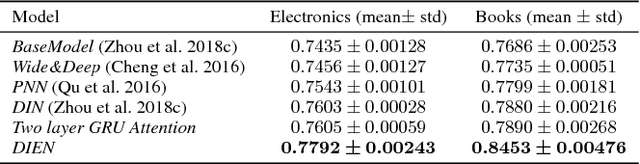
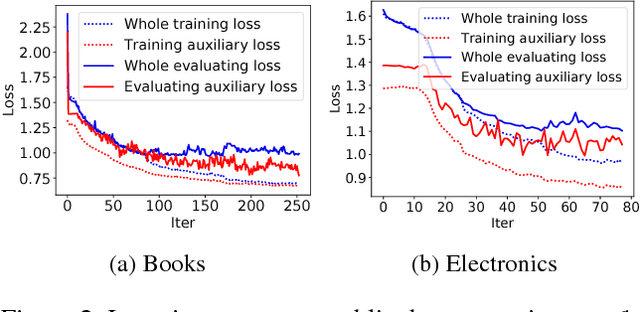
Click-through rate~(CTR) prediction, whose goal is to estimate the probability of the user clicks, has become one of the core tasks in advertising systems. For CTR prediction model, it is necessary to capture the latent user interest behind the user behavior data. Besides, considering the changing of the external environment and the internal cognition, user interest evolves over time dynamically. There are several CTR prediction methods for interest modeling, while most of them regard the representation of behavior as the interest directly, and lack specially modeling for latent interest behind the concrete behavior. Moreover, few work consider the changing trend of interest. In this paper, we propose a novel model, named Deep Interest Evolution Network~(DIEN), for CTR prediction. Specifically, we design interest extractor layer to capture temporal interests from history behavior sequence. At this layer, we introduce an auxiliary loss to supervise interest extracting at each step. As user interests are diverse, especially in the e-commerce system, we propose interest evolving layer to capture interest evolving process that is relative to the target item. At interest evolving layer, attention mechanism is embedded into the sequential structure novelly, and the effects of relative interests are strengthened during interest evolution. In the experiments on both public and industrial datasets, DIEN significantly outperforms the state-of-the-art solutions. Notably, DIEN has been deployed in the display advertisement system of Taobao, and obtained 20.7\% improvement on CTR.
Deep Interest Network for Click-Through Rate Prediction
Sep 13, 2018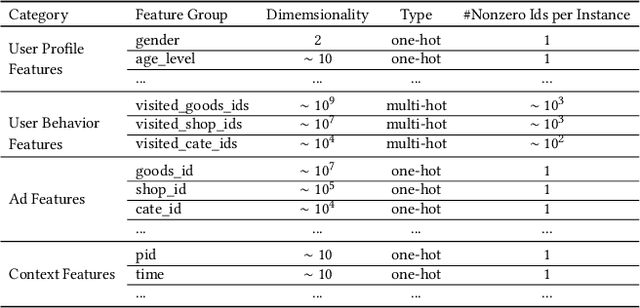
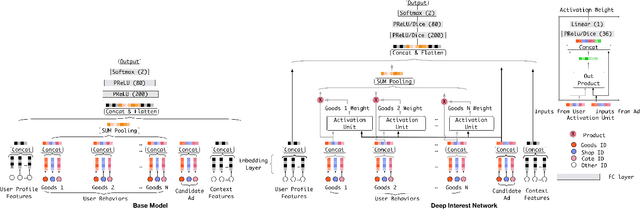
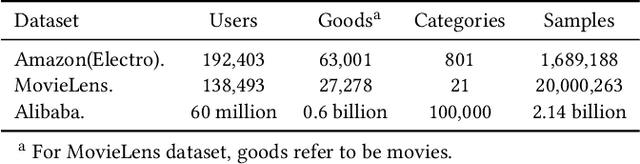
Click-through rate prediction is an essential task in industrial applications, such as online advertising. Recently deep learning based models have been proposed, which follow a similar Embedding\&MLP paradigm. In these methods large scale sparse input features are first mapped into low dimensional embedding vectors, and then transformed into fixed-length vectors in a group-wise manner, finally concatenated together to fed into a multilayer perceptron (MLP) to learn the nonlinear relations among features. In this way, user features are compressed into a fixed-length representation vector, in regardless of what candidate ads are. The use of fixed-length vector will be a bottleneck, which brings difficulty for Embedding\&MLP methods to capture user's diverse interests effectively from rich historical behaviors. In this paper, we propose a novel model: Deep Interest Network (DIN) which tackles this challenge by designing a local activation unit to adaptively learn the representation of user interests from historical behaviors with respect to a certain ad. This representation vector varies over different ads, improving the expressive ability of model greatly. Besides, we develop two techniques: mini-batch aware regularization and data adaptive activation function which can help training industrial deep networks with hundreds of millions of parameters. Experiments on two public datasets as well as an Alibaba real production dataset with over 2 billion samples demonstrate the effectiveness of proposed approaches, which achieve superior performance compared with state-of-the-art methods. DIN now has been successfully deployed in the online display advertising system in Alibaba, serving the main traffic.
Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net
Mar 15, 2018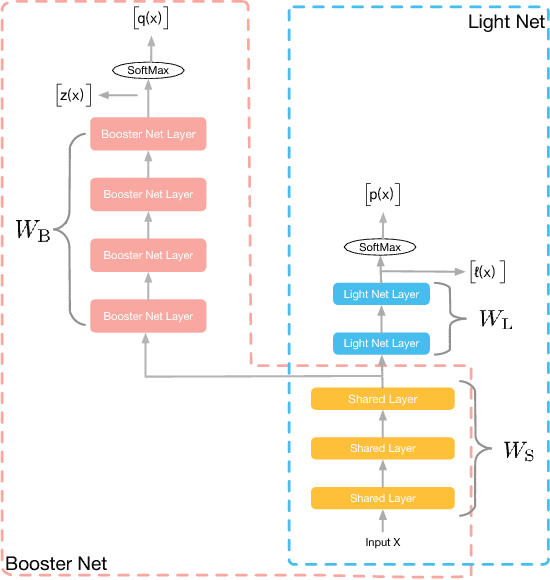
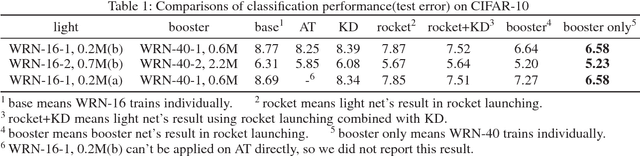
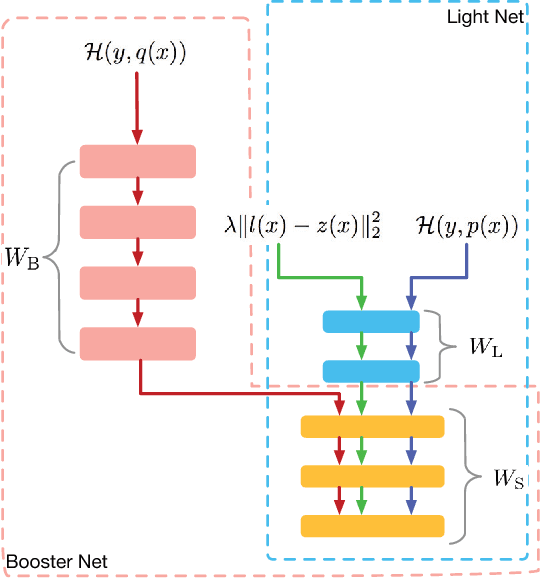

Models applied on real time response task, like click-through rate (CTR) prediction model, require high accuracy and rigorous response time. Therefore, top-performing deep models of high depth and complexity are not well suited for these applications with the limitations on the inference time. In order to further improve the neural networks' performance given the time and computational limitations, we propose an approach that exploits a cumbersome net to help train the lightweight net for prediction. We dub the whole process rocket launching, where the cumbersome booster net is used to guide the learning of the target light net throughout the whole training process. We analyze different loss functions aiming at pushing the light net to behave similarly to the booster net, and adopt the loss with best performance in our experiments. We use one technique called gradient block to improve the performance of the light net and booster net further. Experiments on benchmark datasets and real-life industrial advertisement data present that our light model can get performance only previously achievable with more complex models.
Efficient learning strategy of Chinese characters based on network approach
Mar 07, 2013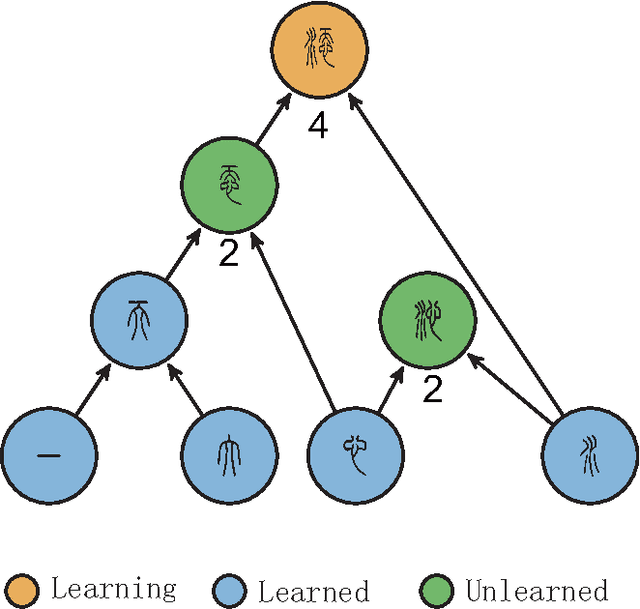
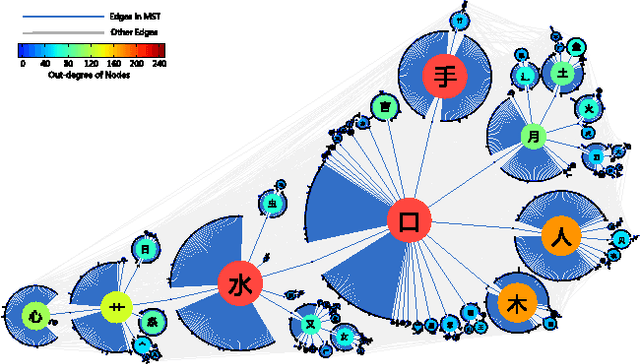
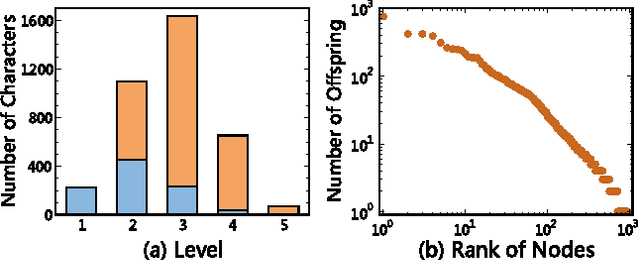
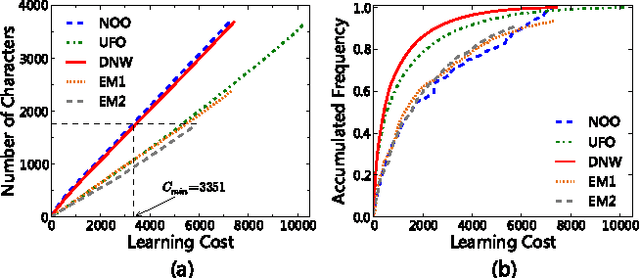
Based on network analysis of hierarchical structural relations among Chinese characters, we develop an efficient learning strategy of Chinese characters. We regard a more efficient learning method if one learns the same number of useful Chinese characters in less effort or time. We construct a node-weighted network of Chinese characters, where character usage frequencies are used as node weights. Using this hierarchical node-weighted network, we propose a new learning method, the distributed node weight (DNW) strategy, which is based on a new measure of nodes' importance that takes into account both the weight of the nodes and the hierarchical structure of the network. Chinese character learning strategies, particularly their learning order, are analyzed as dynamical processes over the network. We compare the efficiency of three theoretical learning methods and two commonly used methods from mainstream Chinese textbooks, one for Chinese elementary school students and the other for students learning Chinese as a second language. We find that the DNW method significantly outperforms the others, implying that the efficiency of current learning methods of major textbooks can be greatly improved.
* 8 pages, 6 figures