 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCorrn: Unified Correspondence Transformer Across 2D and 3D
May 05, 2026Visual correspondence across image-to-image (2D-2D), image-to-point cloud (2D-3D), and point cloud-to-point cloud (3D-3D) geometric matching forms the foundation for numerous 3D vision tasks. Despite sharing a similar problem structure, current methods use task-specific designs with separate models for each modality combination. We present UniCorrn, the first correspondence model with shared weights that unifies geometric matching across all three tasks. Our key insight is that Transformer attention naturally captures cross-modal feature similarity. We propose a dual-stream decoder that maintains separate appearance and positional feature streams. This design enables end-to-end learning through stack-able layers while supporting flexible query-based correspondence estimation across heterogeneous modalities. Our architecture employs modality-specific backbones followed by shared encoder and decoder components, trained jointly on diverse data combining pseudo point clouds from depth maps with real 3D correspondence annotations. UniCorrn achieves competitive performance on 2D-2D matching and surpasses prior state-of-the-art by 8% on 7Scenes (2D-3D) and 10% on 3DLoMatch (3D-3D) in registration recall. Project website: https://neu-vi.github.io/UniCorrn
LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction
Dec 15, 2025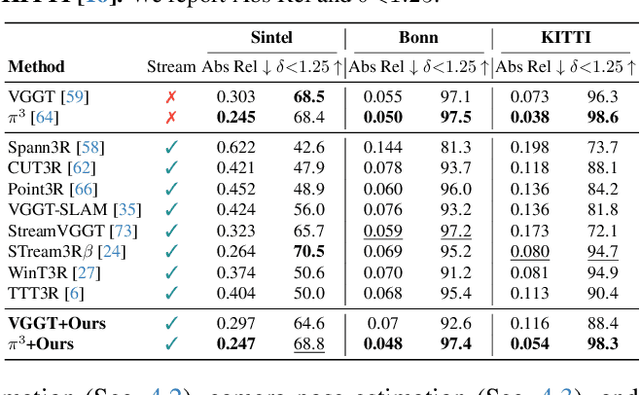
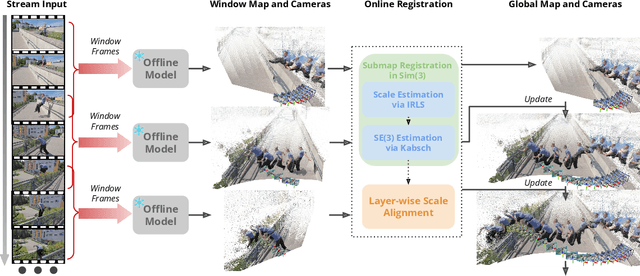
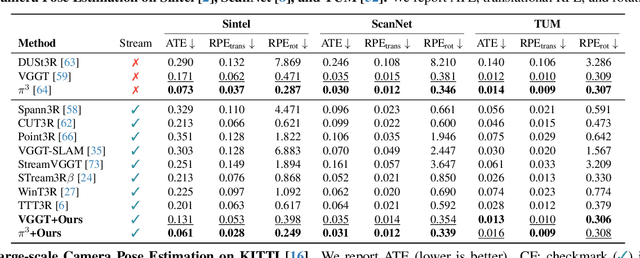
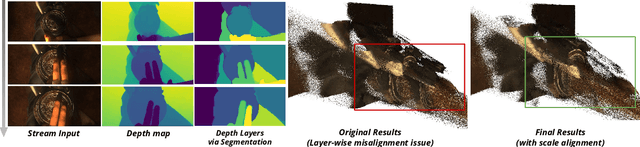
Recent feed-forward reconstruction models like VGGT and $π^3$ achieve impressive reconstruction quality but cannot process streaming videos due to quadratic memory complexity, limiting their practical deployment. While existing streaming methods address this through learned memory mechanisms or causal attention, they require extensive retraining and may not fully leverage the strong geometric priors of state-of-the-art offline models. We propose LASER, a training-free framework that converts an offline reconstruction model into a streaming system by aligning predictions across consecutive temporal windows. We observe that simple similarity transformation ($\mathrm{Sim}(3)$) alignment fails due to layer depth misalignment: monocular scale ambiguity causes relative depth scales of different scene layers to vary inconsistently between windows. To address this, we introduce layer-wise scale alignment, which segments depth predictions into discrete layers, computes per-layer scale factors, and propagates them across both adjacent windows and timestamps. Extensive experiments show that LASER achieves state-of-the-art performance on camera pose estimation and point map reconstruction %quality with offline models while operating at 14 FPS with 6 GB peak memory on a RTX A6000 GPU, enabling practical deployment for kilometer-scale streaming videos. Project website: $\href{https://neu-vi.github.io/LASER/}{\texttt{https://neu-vi.github.io/LASER/}}$
Struct2D: A Perception-Guided Framework for Spatial Reasoning in Large Multimodal Models
Jun 04, 2025Unlocking spatial reasoning in Large Multimodal Models (LMMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can LMMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird's-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source LMMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source LMM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in LMMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
ODTFormer: Efficient Obstacle Detection and Tracking with Stereo Cameras Based on Transformer
Mar 21, 2024Obstacle detection and tracking represent a critical component in robot autonomous navigation. In this paper, we propose ODTFormer, a Transformer-based model to address both obstacle detection and tracking problems. For the detection task, our approach leverages deformable attention to construct a 3D cost volume, which is decoded progressively in the form of voxel occupancy grids. We further track the obstacles by matching the voxels between consecutive frames. The entire model can be optimized in an end-to-end manner. Through extensive experiments on DrivingStereo and KITTI benchmarks, our model achieves state-of-the-art performance in the obstacle detection task. We also report comparable accuracy to state-of-the-art obstacle tracking models while requiring only a fraction of their computation cost, typically ten-fold to twenty-fold less. The code and model weights will be publicly released.