 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatch Causal Signals from Edges for Label Imbalance in Graph Classification
Jan 07, 2025



Despite significant advancements in causal research on graphs and its application to cracking label imbalance, the role of edge features in detecting the causal effects within graphs has been largely overlooked, leaving existing methods with untapped potential for further performance gains. In this paper, we enhance the causal attention mechanism through effectively leveraging edge information to disentangle the causal subgraph from the original graph, as well as further utilizing edge features to reshape graph representations. Capturing more comprehensive causal signals, our design leads to improved performance on graph classification tasks with label imbalance issues. We evaluate our approach on real-word datasets PTC, Tox21, and ogbg-molhiv, observing improvements over baselines. Overall, we highlight the importance of edge features in graph causal detection and provide a promising direction for addressing label imbalance challenges in graph-level tasks. The model implementation details and the codes are available on https://github.com/fengrui-z/ECAL
LeetDecoding: A PyTorch Library for Exponentially Decaying Causal Linear Attention with CUDA Implementations
Jan 05, 2025



The machine learning and data science community has made significant while dispersive progress in accelerating transformer-based large language models (LLMs), and one promising approach is to replace the original causal attention in a generative pre-trained transformer (GPT) with \emph{exponentially decaying causal linear attention}. In this paper, we present LeetDecoding, which is the first Python package that provides a large set of computation routines for this fundamental operator. The launch of LeetDecoding was motivated by the current lack of (1) clear understanding of the complexity regarding this operator, (2) a comprehensive collection of existing computation methods (usually spread in seemingly unrelated fields), and (3) CUDA implementations for fast inference on GPU. LeetDecoding's design is easy to integrate with existing linear-attention LLMs, and allows for researchers to benchmark and evaluate new computation methods for exponentially decaying causal linear attention. The usage of LeetDecoding does not require any knowledge of GPU programming and the underlying complexity analysis, intentionally making LeetDecoding accessible to LLM practitioners. The source code of LeetDecoding is provided at \href{https://github.com/Computational-Machine-Intelligence/LeetDecoding}{this GitHub repository}, and users can simply install LeetDecoding by the command \texttt{pip install leet-decoding}.
Optimized Gradient Clipping for Noisy Label Learning
Dec 12, 2024



Previous research has shown that constraining the gradient of loss function with respect to model-predicted probabilities can enhance the model robustness against noisy labels. These methods typically specify a fixed optimal threshold for gradient clipping through validation data to obtain the desired robustness against noise. However, this common practice overlooks the dynamic distribution of gradients from both clean and noisy-labeled samples at different stages of training, significantly limiting the model capability to adapt to the variable nature of gradients throughout the training process. To address this issue, we propose a simple yet effective approach called Optimized Gradient Clipping (OGC), which dynamically adjusts the clipping threshold based on the ratio of noise gradients to clean gradients after clipping, estimated by modeling the distributions of clean and noisy samples. This approach allows us to modify the clipping threshold at each training step, effectively controlling the influence of noise gradients. Additionally, we provide statistical analysis to certify the noise-tolerance ability of OGC. Our extensive experiments across various types of label noise, including symmetric, asymmetric, instance-dependent, and real-world noise, demonstrate the effectiveness of our approach. The code and a technical appendix for better digital viewing are included as supplementary materials and scheduled to be open-sourced upon publication.
Revisiting Energy-Based Model for Out-of-Distribution Detection
Dec 04, 2024



Out-of-distribution (OOD) detection is an essential approach to robustifying deep learning models, enabling them to identify inputs that fall outside of their trained distribution. Existing OOD detection methods usually depend on crafted data, such as specific outlier datasets or elaborate data augmentations. While this is reasonable, the frequent mismatch between crafted data and OOD data limits model robustness and generalizability. In response to this issue, we introduce Outlier Exposure by Simple Transformations (OEST), a framework that enhances OOD detection by leveraging "peripheral-distribution" (PD) data. Specifically, PD data are samples generated through simple data transformations, thus providing an efficient alternative to manually curated outliers. We adopt energy-based models (EBMs) to study PD data. We recognize the "energy barrier" in OOD detection, which characterizes the energy difference between in-distribution (ID) and OOD samples and eases detection. PD data are introduced to establish the energy barrier during training. Furthermore, this energy barrier concept motivates a theoretically grounded energy-barrier loss to replace the classical energy-bounded loss, leading to an improved paradigm, OEST*, which achieves a more effective and theoretically sound separation between ID and OOD samples. We perform empirical validation of our proposal, and extensive experiments across various benchmarks demonstrate that OEST* achieves better or similar accuracy compared with state-of-the-art methods.
Active Negative Loss: A Robust Framework for Learning with Noisy Labels
Dec 03, 2024



Deep supervised learning has achieved remarkable success across a wide range of tasks, yet it remains susceptible to overfitting when confronted with noisy labels. To address this issue, noise-robust loss functions offer an effective solution for enhancing learning in the presence of label noise. In this work, we systematically investigate the limitation of the recently proposed Active Passive Loss (APL), which employs Mean Absolute Error (MAE) as its passive loss function. Despite the robustness brought by MAE, one of its key drawbacks is that it pays equal attention to clean and noisy samples; this feature slows down convergence and potentially makes training difficult, particularly in large-scale datasets. To overcome these challenges, we introduce a novel loss function class, termed Normalized Negative Loss Functions (NNLFs), which serve as passive loss functions within the APL framework. NNLFs effectively address the limitations of MAE by concentrating more on memorized clean samples. By replacing MAE in APL with our proposed NNLFs, we enhance APL and present a new framework called Active Negative Loss (ANL). Moreover, in non-symmetric noise scenarios, we propose an entropy-based regularization technique to mitigate the vulnerability to the label imbalance. Extensive experiments demonstrate that the new loss functions adopted by our ANL framework can achieve better or comparable performance to state-of-the-art methods across various label noise types and in image segmentation tasks. The source code is available at: https://github.com/Virusdoll/Active-Negative-Loss.
When Spatial meets Temporal in Action Recognition
Nov 22, 2024



Video action recognition has made significant strides, but challenges remain in effectively using both spatial and temporal information. While existing methods often focus on either spatial features (e.g., object appearance) or temporal dynamics (e.g., motion), they rarely address the need for a comprehensive integration of both. Capturing the rich temporal evolution of video frames, while preserving their spatial details, is crucial for improving accuracy. In this paper, we introduce the Temporal Integration and Motion Enhancement (TIME) layer, a novel preprocessing technique designed to incorporate temporal information. The TIME layer generates new video frames by rearranging the original sequence, preserving temporal order while embedding $N^2$ temporally evolving frames into a single spatial grid of size $N \times N$. This transformation creates new frames that balance both spatial and temporal information, making them compatible with existing video models. When $N=1$, the layer captures rich spatial details, similar to existing methods. As $N$ increases ($N\geq2$), temporal information becomes more prominent, while the spatial information decreases to ensure compatibility with model inputs. We demonstrate the effectiveness of the TIME layer by integrating it into popular action recognition models, such as ResNet-50, Vision Transformer, and Video Masked Autoencoders, for both RGB and depth video data. Our experiments show that the TIME layer enhances recognition accuracy, offering valuable insights for video processing tasks.
A Survey of Foundation Models for Music Understanding
Sep 15, 2024
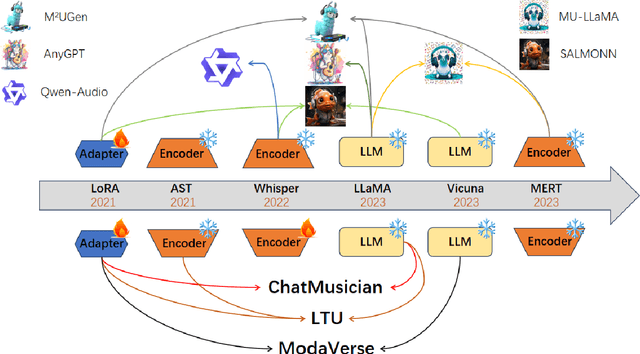
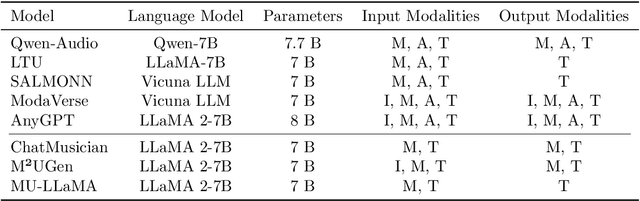
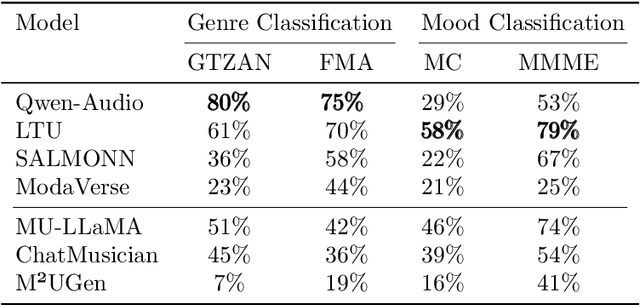
Music is essential in daily life, fulfilling emotional and entertainment needs, and connecting us personally, socially, and culturally. A better understanding of music can enhance our emotions, cognitive skills, and cultural connections. The rapid advancement of artificial intelligence (AI) has introduced new ways to analyze music, aiming to replicate human understanding of music and provide related services. While the traditional models focused on audio features and simple tasks, the recent development of large language models (LLMs) and foundation models (FMs), which excel in various fields by integrating semantic information and demonstrating strong reasoning abilities, could capture complex musical features and patterns, integrate music with language and incorporate rich musical, emotional and psychological knowledge. Therefore, they have the potential in handling complex music understanding tasks from a semantic perspective, producing outputs closer to human perception. This work, to our best knowledge, is one of the early reviews of the intersection of AI techniques and music understanding. We investigated, analyzed, and tested recent large-scale music foundation models in respect of their music comprehension abilities. We also discussed their limitations and proposed possible future directions, offering insights for researchers in this field.
Convergence of Unadjusted Langevin in High Dimensions: Delocalization of Bias
Aug 20, 2024The unadjusted Langevin algorithm is commonly used to sample probability distributions in extremely high-dimensional settings. However, existing analyses of the algorithm for strongly log-concave distributions suggest that, as the dimension $d$ of the problem increases, the number of iterations required to ensure convergence within a desired error in the $W_2$ metric scales in proportion to $d$ or $\sqrt{d}$. In this paper, we argue that, despite this poor scaling of the $W_2$ error for the full set of variables, the behavior for a small number of variables can be significantly better: a number of iterations proportional to $K$, up to logarithmic terms in $d$, often suffices for the algorithm to converge to within a desired $W_2$ error for all $K$-marginals. We refer to this effect as delocalization of bias. We show that the delocalization effect does not hold universally and prove its validity for Gaussian distributions and strongly log-concave distributions with certain sparse interactions. Our analysis relies on a novel $W_{2,\ell^\infty}$ metric to measure convergence. A key technical challenge we address is the lack of a one-step contraction property in this metric. Finally, we use asymptotic arguments to explore potential generalizations of the delocalization effect beyond the Gaussian and sparse interactions setting.
ComKD-CLIP: Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model
Aug 08, 2024Contrastive Language-Image Pre-training (CLIP) excels in integrating semantic information between images and text through contrastive learning techniques. It has achieved remarkable performance in various multimodal tasks. However, the deployment of large CLIP models is hindered in resource-limited environments, while smaller models frequently fall short of meeting performance benchmarks necessary for practical applications. In this paper, we propose a novel approach, coined as ComKD-CLIP: Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model, which aims to comprehensively distill the knowledge from a large teacher CLIP model into a smaller student model, ensuring comparable performance with significantly reduced parameters. ComKD-CLIP is composed of two key mechanisms: Image Feature Alignment (IFAlign) and Educational Attention (EduAttention). IFAlign makes the image features extracted by the student model closely match those extracted by the teacher model, enabling the student to learn teacher's knowledge of extracting image features. EduAttention explores the cross-relationships between text features extracted by the teacher model and image features extracted by the student model, enabling the student model to learn how the teacher model integrates text-image features. In addition, ComKD-CLIP can refine the knowledge distilled from IFAlign and EduAttention leveraging the results of text-image feature fusion by the teacher model, ensuring student model accurately absorbs the knowledge of teacher model. Extensive experiments conducted on 11 datasets have demonstrated the superiority of the proposed method.
SentenceVAE: Enable Next-sentence Prediction for Large Language Models with Faster Speed, Higher Accuracy and Longer Context
Aug 07, 2024Current large language models (LLMs) primarily utilize next-token prediction method for inference, which significantly impedes their processing speed. In this paper, we introduce a novel inference methodology termed next-sentence prediction, aimed at enhancing the inference efficiency of LLMs. We present Sentence Variational Autoencoder (SentenceVAE), a tiny model consisting of a Sentence Encoder and a Sentence Decoder. The Sentence Encoder can effectively condense the information within a sentence into a singular token, while the Sentence Decoder can reconstruct this compressed token back into sentence. By integrating SentenceVAE into the input and output layers of LLMs, we develop Sentence-level LLMs (SLLMs) that employ a sentence-by-sentence inference method. In addition, the SentenceVAE module of SLLMS can maintain the integrity of the original semantic content by segmenting the context into sentences, thereby improving accuracy while boosting inference speed. Moreover, compared to previous LLMs, SLLMs process fewer tokens over equivalent context length, significantly reducing memory demands for self-attention computation and facilitating the handling of longer context. Extensive experiments on Wanjuan dataset have reveal that the proposed method can accelerate inference speed by 204~365%, reduce perplexity (PPL) to 46~75% of its original metric, and decrease memory overhead by 86~91% for the equivalent context length, compared to the token-by-token method.