 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025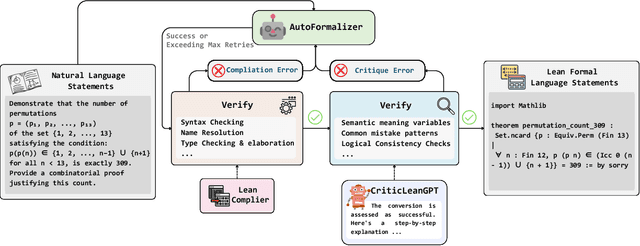

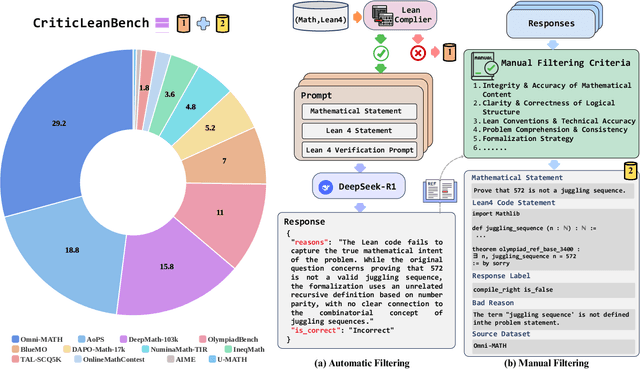
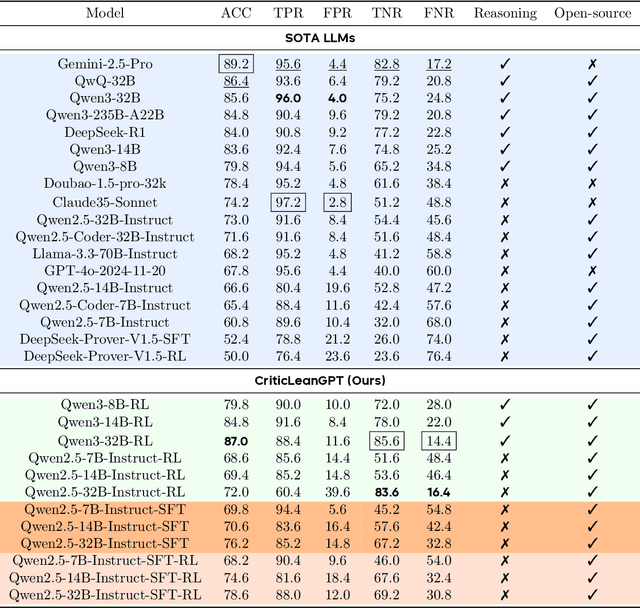
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
Evaluating LLM-corrupted Crowdsourcing Data Without Ground Truth
Jun 08, 2025The recent success of generative AI highlights the crucial role of high-quality human feedback in building trustworthy AI systems. However, the increasing use of large language models (LLMs) by crowdsourcing workers poses a significant challenge: datasets intended to reflect human input may be compromised by LLM-generated responses. Existing LLM detection approaches often rely on high-dimension training data such as text, making them unsuitable for annotation tasks like multiple-choice labeling. In this work, we investigate the potential of peer prediction -- a mechanism that evaluates the information within workers' responses without using ground truth -- to mitigate LLM-assisted cheating in crowdsourcing with a focus on annotation tasks. Our approach quantifies the correlations between worker answers while conditioning on (a subset of) LLM-generated labels available to the requester. Building on prior research, we propose a training-free scoring mechanism with theoretical guarantees under a crowdsourcing model that accounts for LLM collusion. We establish conditions under which our method is effective and empirically demonstrate its robustness in detecting low-effort cheating on real-world crowdsourcing datasets.
Proactive Assistant Dialogue Generation from Streaming Egocentric Videos
Jun 06, 2025Recent advances in conversational AI have been substantial, but developing real-time systems for perceptual task guidance remains challenging. These systems must provide interactive, proactive assistance based on streaming visual inputs, yet their development is constrained by the costly and labor-intensive process of data collection and system evaluation. To address these limitations, we present a comprehensive framework with three key contributions. First, we introduce a novel data curation pipeline that synthesizes dialogues from annotated egocentric videos, resulting in \dataset, a large-scale synthetic dialogue dataset spanning multiple domains. Second, we develop a suite of automatic evaluation metrics, validated through extensive human studies. Third, we propose an end-to-end model that processes streaming video inputs to generate contextually appropriate responses, incorporating novel techniques for handling data imbalance and long-duration videos. This work lays the foundation for developing real-time, proactive AI assistants capable of guiding users through diverse tasks. Project page: https://pro-assist.github.io/
D2AF: A Dual-Driven Annotation and Filtering Framework for Visual Grounding
May 30, 2025



Visual Grounding is a task that aims to localize a target region in an image based on a free-form natural language description. With the rise of Transformer architectures, there is an increasing need for larger datasets to boost performance. However, the high cost of manual annotation poses a challenge, hindering the scale of data and the ability of large models to enhance their effectiveness. Previous pseudo label generation methods heavily rely on human-labeled captions of the original dataset, limiting scalability and diversity. To address this, we propose D2AF, a robust annotation framework for visual grounding using only input images. This approach overcomes dataset size limitations and enriches both the quantity and diversity of referring expressions. Our approach leverages multimodal large models and object detection models. By implementing dual-driven annotation strategies, we effectively generate detailed region-text pairs using both closed-set and open-set approaches. We further conduct an in-depth analysis of data quantity and data distribution. Our findings demonstrate that increasing data volume enhances model performance. However, the degree of improvement depends on how well the pseudo labels broaden the original data distribution. Based on these insights, we propose a consistency and distribution aware filtering method to further improve data quality by effectively removing erroneous and redundant data. This approach effectively eliminates noisy data, leading to improved performance. Experiments on three visual grounding tasks demonstrate that our method significantly improves the performance of existing models and achieves state-of-the-art results.
Mitigating Overthinking in Large Reasoning Models via Manifold Steering
May 28, 2025Recent advances in Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in solving complex tasks such as mathematics and coding. However, these models frequently exhibit a phenomenon known as overthinking during inference, characterized by excessive validation loops and redundant deliberation, leading to substantial computational overheads. In this paper, we aim to mitigate overthinking by investigating the underlying mechanisms from the perspective of mechanistic interpretability. We first showcase that the tendency of overthinking can be effectively captured by a single direction in the model's activation space and the issue can be eased by intervening the activations along this direction. However, this efficacy soon reaches a plateau and even deteriorates as the intervention strength increases. We therefore systematically explore the activation space and find that the overthinking phenomenon is actually tied to a low-dimensional manifold, which indicates that the limited effect stems from the noises introduced by the high-dimensional steering direction. Based on this insight, we propose Manifold Steering, a novel approach that elegantly projects the steering direction onto the low-dimensional activation manifold given the theoretical approximation of the interference noise. Extensive experiments on DeepSeek-R1 distilled models validate that our method reduces output tokens by up to 71% while maintaining and even improving the accuracy on several mathematical benchmarks. Our method also exhibits robust cross-domain transferability, delivering consistent token reduction performance in code generation and knowledge-based QA tasks. Code is available at: https://github.com/Aries-iai/Manifold_Steering.
Breaking the Ceiling: Exploring the Potential of Jailbreak Attacks through Expanding Strategy Space
May 28, 2025Large Language Models (LLMs), despite advanced general capabilities, still suffer from numerous safety risks, especially jailbreak attacks that bypass safety protocols. Understanding these vulnerabilities through black-box jailbreak attacks, which better reflect real-world scenarios, offers critical insights into model robustness. While existing methods have shown improvements through various prompt engineering techniques, their success remains limited against safety-aligned models, overlooking a more fundamental problem: the effectiveness is inherently bounded by the predefined strategy spaces. However, expanding this space presents significant challenges in both systematically capturing essential attack patterns and efficiently navigating the increased complexity. To better explore the potential of expanding the strategy space, we address these challenges through a novel framework that decomposes jailbreak strategies into essential components based on the Elaboration Likelihood Model (ELM) theory and develops genetic-based optimization with intention evaluation mechanisms. To be striking, our experiments reveal unprecedented jailbreak capabilities by expanding the strategy space: we achieve over 90% success rate on Claude-3.5 where prior methods completely fail, while demonstrating strong cross-model transferability and surpassing specialized safeguard models in evaluation accuracy. The code is open-sourced at: https://github.com/Aries-iai/CL-GSO.
Low-Rank Adaptation of Pre-trained Vision Backbones for Energy-Efficient Image Coding for Machine
May 23, 2025Image Coding for Machines (ICM) focuses on optimizing image compression for AI-driven analysis rather than human perception. Existing ICM frameworks often rely on separate codecs for specific tasks, leading to significant storage requirements, training overhead, and computational complexity. To address these challenges, we propose an energy-efficient framework that leverages pre-trained vision backbones to extract robust and versatile latent representations suitable for multiple tasks. We introduce a task-specific low-rank adaptation mechanism, which refines the pre-trained features to be both compressible and tailored to downstream applications. This design minimizes trainable parameters and reduces energy costs for multi-task scenarios. By jointly optimizing task performance and entropy minimization, our method enables efficient adaptation to diverse tasks and datasets without full fine-tuning, achieving high coding efficiency. Extensive experiments demonstrate that our framework significantly outperforms traditional codecs and pre-processors, offering an energy-efficient and effective solution for ICM applications. The code and the supplementary materials will be available at: https://gitlab.com/viper-purdue/efficient-compression.
Accelerating Learned Image Compression Through Modeling Neural Training Dynamics
May 23, 2025As learned image compression (LIC) methods become increasingly computationally demanding, enhancing their training efficiency is crucial. This paper takes a step forward in accelerating the training of LIC methods by modeling the neural training dynamics. We first propose a Sensitivity-aware True and Dummy Embedding Training mechanism (STDET) that clusters LIC model parameters into few separate modes where parameters are expressed as affine transformations of reference parameters within the same mode. By further utilizing the stable intra-mode correlations throughout training and parameter sensitivities, we gradually embed non-reference parameters, reducing the number of trainable parameters. Additionally, we incorporate a Sampling-then-Moving Average (SMA) technique, interpolating sampled weights from stochastic gradient descent (SGD) training to obtain the moving average weights, ensuring smooth temporal behavior and minimizing training state variances. Overall, our method significantly reduces training space dimensions and the number of trainable parameters without sacrificing model performance, thus accelerating model convergence. We also provide a theoretical analysis on the Noisy quadratic model, showing that the proposed method achieves a lower training variance than standard SGD. Our approach offers valuable insights for further developing efficient training methods for LICs.
Understanding Pre-training and Fine-tuning from Loss Landscape Perspectives
May 23, 2025



Recent studies have revealed that the loss landscape of large language models resembles a basin, within which the models perform nearly identically, and outside of which they lose all their capabilities. In this work, we conduct further studies on the loss landscape of large language models. We discover that pre-training creates a "basic capability" basin, and subsequent fine-tuning creates "specific capability" basins (e.g., math, safety, coding) within the basic capability basin. We further investigate two types of loss landscapes: the most-case landscape (i.e., the landscape along most directions) and the worst-case landscape (i.e., the landscape along the worst direction). We argue that as long as benign fine-tuning remains within the most-case basin, it will not compromise previous capabilities. Similarly, any fine-tuning (including the adversarial one) that stays within the worst-case basin would not compromise previous capabilities. Finally, we theoretically demonstrate that the size of the most-case basin can bound the size of the worst-case basin and the robustness with respect to input perturbations. We also show that, due to the over-parameterization property of current large language models, one can easily enlarge the basins by five times.
Efficient Implicit Neural Compression of Point Clouds via Learnable Activation in Latent Space
Apr 20, 2025Implicit Neural Representations (INRs), also known as neural fields, have emerged as a powerful paradigm in deep learning, parameterizing continuous spatial fields using coordinate-based neural networks. In this paper, we propose \textbf{PICO}, an INR-based framework for static point cloud compression. Unlike prevailing encoder-decoder paradigms, we decompose the point cloud compression task into two separate stages: geometry compression and attribute compression, each with distinct INR optimization objectives. Inspired by Kolmogorov-Arnold Networks (KANs), we introduce a novel network architecture, \textbf{LeAFNet}, which leverages learnable activation functions in the latent space to better approximate the target signal's implicit function. By reformulating point cloud compression as neural parameter compression, we further improve compression efficiency through quantization and entropy coding. Experimental results demonstrate that \textbf{LeAFNet} outperforms conventional MLPs in INR-based point cloud compression. Furthermore, \textbf{PICO} achieves superior geometry compression performance compared to the current MPEG point cloud compression standard, yielding an average improvement of $4.92$ dB in D1 PSNR. In joint geometry and attribute compression, our approach exhibits highly competitive results, with an average PCQM gain of $2.7 \times 10^{-3}$.