 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMO-Codec: A Depth Look at Emotion Preservation Capacity of Legacy and Neural Codec Models With Subjective and Objective Evaluations
Jul 24, 2024



The neural codec model reduces speech data transmission delay and serves as the foundational tokenizer for speech language models (speech LMs). Preserving emotional information in codecs is crucial for effective communication and context understanding. However, there is a lack of studies on emotion loss in existing codecs. This paper evaluates neural and legacy codecs using subjective and objective methods on emotion datasets like IEMOCAP. Our study identifies which codecs best preserve emotional information under various bitrate scenarios. We found that training codec models with both English and Chinese data had limited success in retaining emotional information in Chinese. Additionally, resynthesizing speech through these codecs degrades the performance of speech emotion recognition (SER), particularly for emotions like sadness, depression, fear, and disgust. Human listening tests confirmed these findings. This work guides future speech technology developments to ensure new codecs maintain the integrity of emotional information in speech.
EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation
Jun 11, 2024



We release the EARS (Expressive Anechoic Recordings of Speech) dataset, a high-quality speech dataset comprising 107 speakers from diverse backgrounds, totaling in 100 hours of clean, anechoic speech data. The dataset covers a large range of different speaking styles, including emotional speech, different reading styles, non-verbal sounds, and conversational freeform speech. We benchmark various methods for speech enhancement and dereverberation on the dataset and evaluate their performance through a set of instrumental metrics. In addition, we conduct a listening test with 20 participants for the speech enhancement task, where a generative method is preferred. We introduce a blind test set that allows for automatic online evaluation of uploaded data. Dataset download links and automatic evaluation server can be found online.
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
May 20, 2024The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
ScoreDec: A Phase-preserving High-Fidelity Audio Codec with A Generalized Score-based Diffusion Post-filter
Jan 22, 2024Although recent mainstream waveform-domain end-to-end (E2E) neural audio codecs achieve impressive coded audio quality with a very low bitrate, the quality gap between the coded and natural audio is still significant. A generative adversarial network (GAN) training is usually required for these E2E neural codecs because of the difficulty of direct phase modeling. However, such adversarial learning hinders these codecs from preserving the original phase information. To achieve human-level naturalness with a reasonable bitrate, preserve the original phase, and get rid of the tricky and opaque GAN training, we develop a score-based diffusion post-filter (SPF) in the complex spectral domain and combine our previous AudioDec with the SPF to propose ScoreDec, which can be trained using only spectral and score-matching losses. Both the objective and subjective experimental results show that ScoreDec with a 24~kbps bitrate encodes and decodes full-band 48~kHz speech with human-level naturalness and well-preserved phase information.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023



Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
AudioDec: An Open-source Streaming High-fidelity Neural Audio Codec
May 26, 2023



A good audio codec for live applications such as telecommunication is characterized by three key properties: (1) compression, i.e.\ the bitrate that is required to transmit the signal should be as low as possible; (2) latency, i.e.\ encoding and decoding the signal needs to be fast enough to enable communication without or with only minimal noticeable delay; and (3) reconstruction quality of the signal. In this work, we propose an open-source, streamable, and real-time neural audio codec that achieves strong performance along all three axes: it can reconstruct highly natural sounding 48~kHz speech signals while operating at only 12~kbps and running with less than 6~ms (GPU)/10~ms (CPU) latency. An efficient training paradigm is also demonstrated for developing such neural audio codecs for real-world scenarios. Both objective and subjective evaluations using the VCTK corpus are provided. To sum up, AudioDec is a well-developed plug-and-play benchmark for audio codec applications.
Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder
Oct 31, 2022

Our previous work, the unified source-filter GAN (uSFGAN) vocoder, introduced a novel architecture based on the source-filter theory into the parallel waveform generative adversarial network to achieve high voice quality and pitch controllability. However, the high temporal resolution inputs result in high computation costs. Although the HiFi-GAN vocoder achieves fast high-fidelity voice generation thanks to the efficient upsampling-based generator architecture, the pitch controllability is severely limited. To realize a fast and pitch-controllable high-fidelity neural vocoder, we introduce the source-filter theory into HiFi-GAN by hierarchically conditioning the resonance filtering network on a well-estimated source excitation information. According to the experimental results, our proposed method outperforms HiFi-GAN and uSFGAN on a singing voice generation in voice quality and synthesis speed on a single CPU. Furthermore, unlike the uSFGAN vocoder, the proposed method can be easily adopted/integrated in real-time applications and end-to-end systems.
A Cyclical Approach to Synthetic and Natural Speech Mismatch Refinement of Neural Post-filter for Low-cost Text-to-speech System
Jul 13, 2022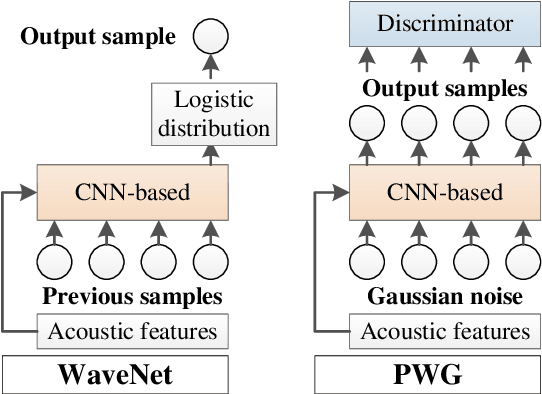
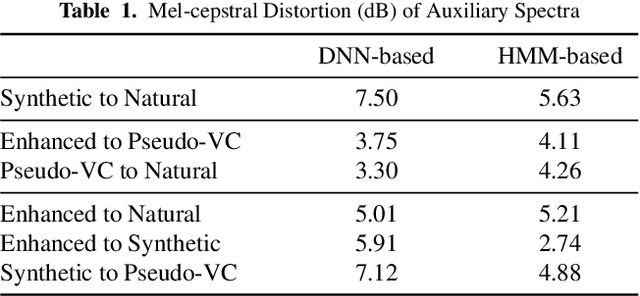
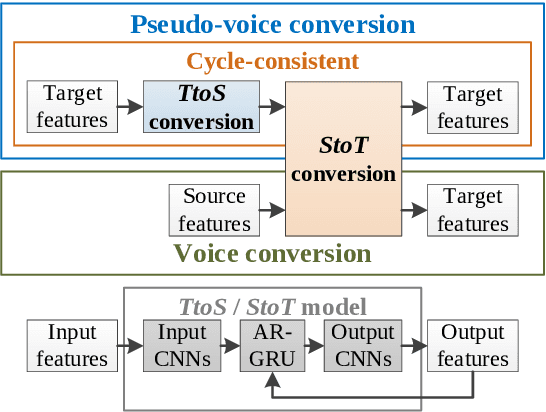
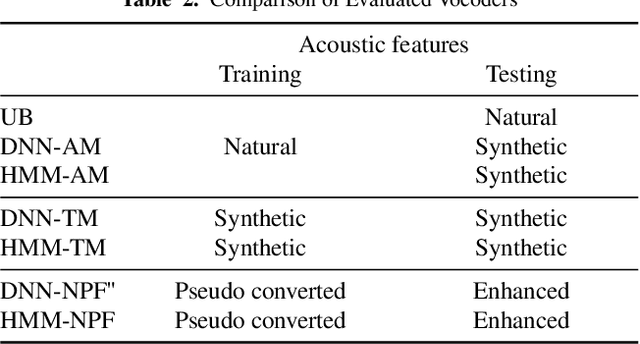
Neural-based text-to-speech (TTS) systems achieve very high-fidelity speech generation because of the rapid neural network developments. However, the huge labeled corpus and high computation cost requirements limit the possibility of developing a high-fidelity TTS system by small companies or individuals. On the other hand, a neural vocoder, which has been widely adopted for the speech generation in neural-based TTS systems, can be trained with a relatively small unlabeled corpus. Therefore, in this paper, we explore a general framework to develop a neural post-filter (NPF) for low-cost TTS systems using neural vocoders. A cyclical approach is proposed to tackle the acoustic and temporal mismatches (AM and TM) of developing an NPF. Both objective and subjective evaluations have been conducted to demonstrate the AM and TM problems and the effectiveness of the proposed framework.
Unified Source-Filter GAN with Harmonic-plus-Noise Source Excitation Generation
May 12, 2022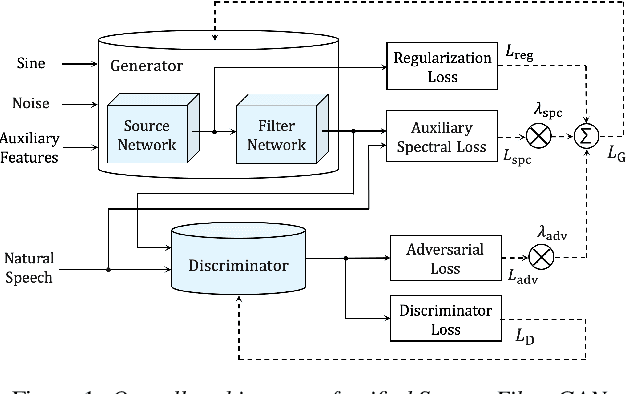
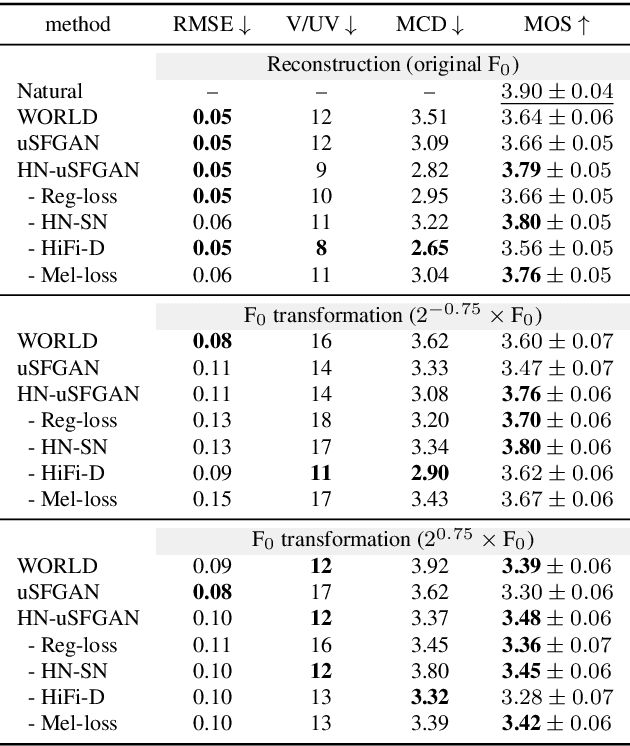
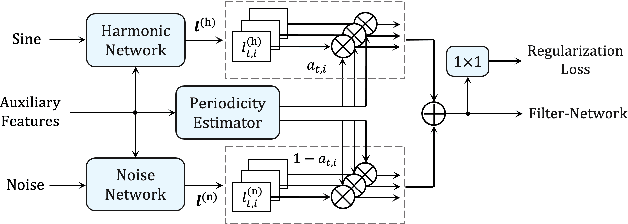
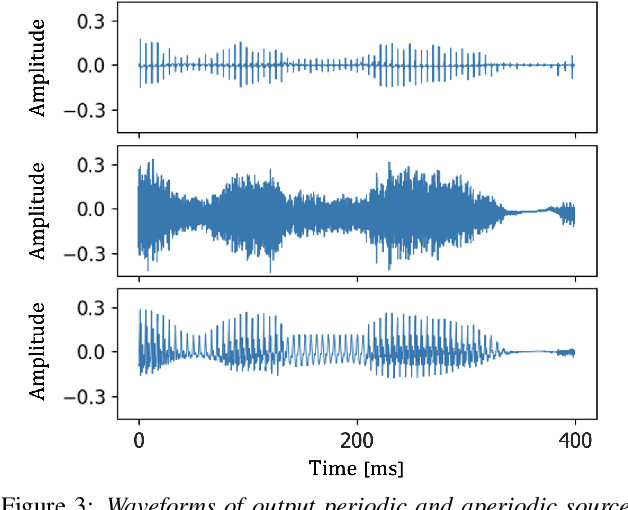
This paper introduces a unified source-filter network with a harmonic-plus-noise source excitation generation mechanism. In our previous work, we proposed unified Source-Filter GAN (uSFGAN) for developing a high-fidelity neural vocoder with flexible voice controllability using a unified source-filter neural network architecture. However, the capability of uSFGAN to model the aperiodic source excitation signal is insufficient, and there is still a gap in sound quality between the natural and generated speech. To improve the source excitation modeling and generated sound quality, a new source excitation generation network separately generating periodic and aperiodic components is proposed. The advanced adversarial training procedure of HiFiGAN is also adopted to replace that of Parallel WaveGAN used in the original uSFGAN. Both objective and subjective evaluation results show that the modified uSFGAN significantly improves the sound quality of the basic uSFGAN while maintaining the voice controllability.
Direct Noisy Speech Modeling for Noisy-to-Noisy Voice Conversion
Nov 13, 2021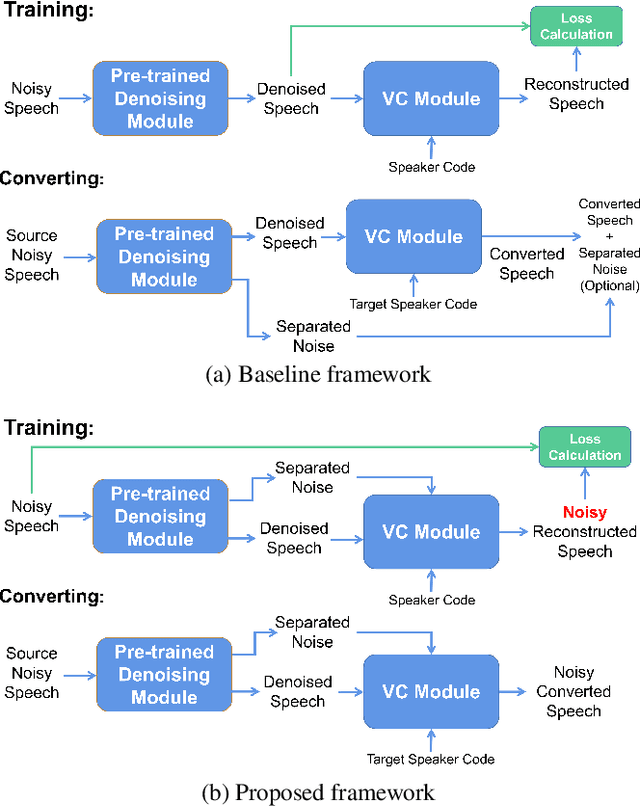
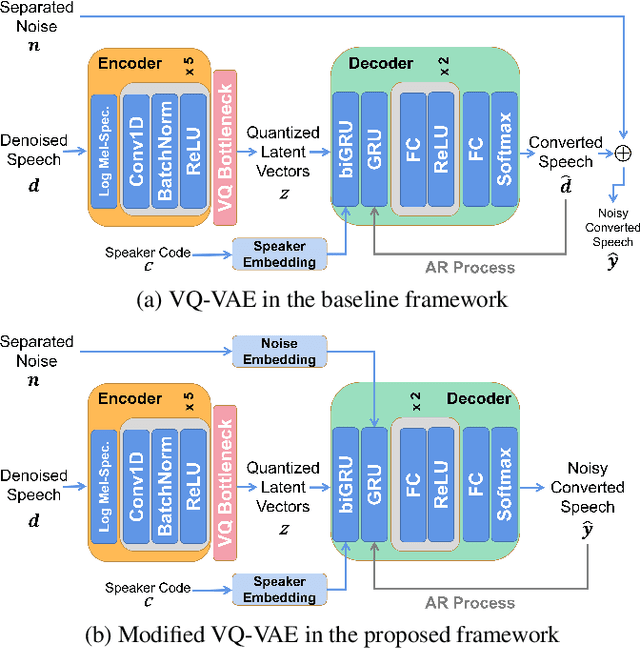
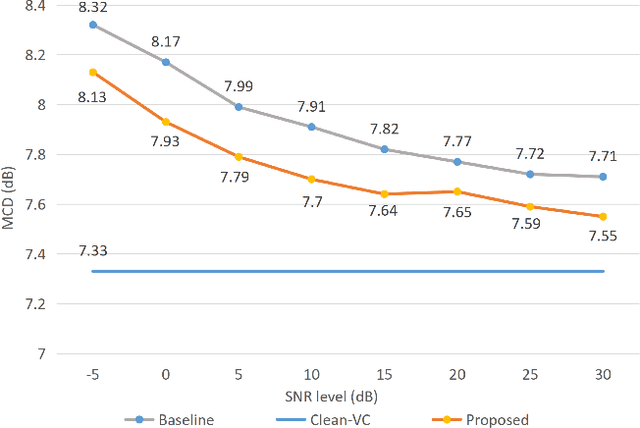
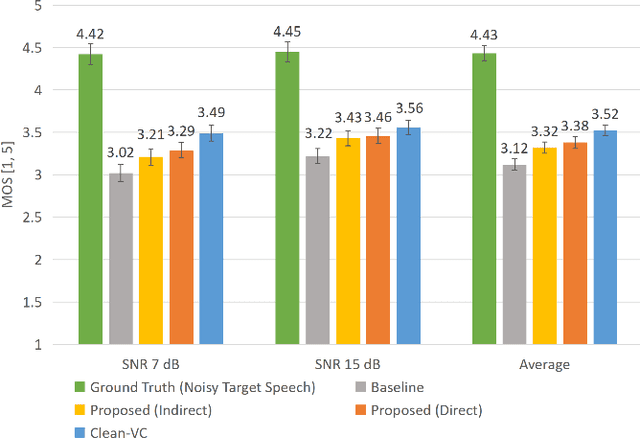
Beyond the conventional voice conversion (VC) where the speaker information is converted without altering the linguistic content, the background sounds are informative and need to be retained in some real-world scenarios, such as VC in movie/video and VC in music where the voice is entangled with background sounds. As a new VC framework, we have developed a noisy-to-noisy (N2N) VC framework to convert the speaker's identity while preserving the background sounds. Although our framework consisting of a denoising module and a VC module well handles the background sounds, the VC module is sensitive to the distortion caused by the denoising module. To address this distortion issue, in this paper we propose the improved VC module to directly model the noisy speech waveform while controlling the background sounds. The experimental results have demonstrated that our improved framework significantly outperforms the previous one and achieves an acceptable score in terms of naturalness, while reaching comparable similarity performance to the upper bound of our framework.