 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Analysis for Quality of Multilingual Synthesized Speech
Sep 05, 2025While supervised quality predictors for synthesized speech have demonstrated strong correlations with human ratings, their requirement for in-domain labeled training data hinders their generalization ability to new domains. Unsupervised approaches based on pretrained self-supervised learning (SSL) based models and automatic speech recognition (ASR) models are a promising alternative; however, little is known about how these models encode information about speech quality. Towards the goal of better understanding how different aspects of speech quality are encoded in a multilingual setting, we present a layer-wise analysis of multilingual pretrained speech models based on reference modeling. We find that features extracted from early SSL layers show correlations with human ratings of synthesized speech, and later layers of ASR models can predict quality of non-neural systems as well as intelligibility. We also demonstrate the importance of using well-matched reference data.
A Cyclical Approach to Synthetic and Natural Speech Mismatch Refinement of Neural Post-filter for Low-cost Text-to-speech System
Jul 13, 2022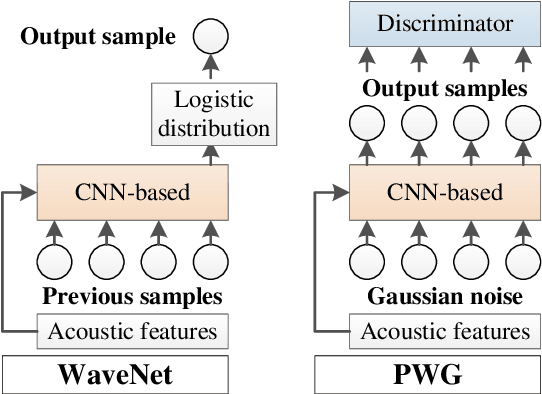
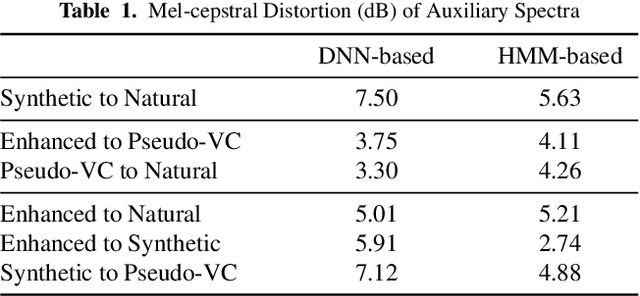
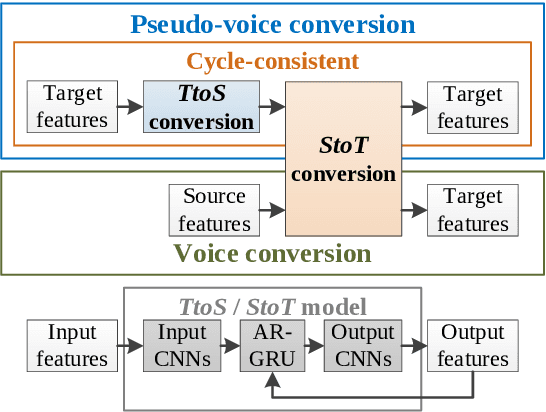
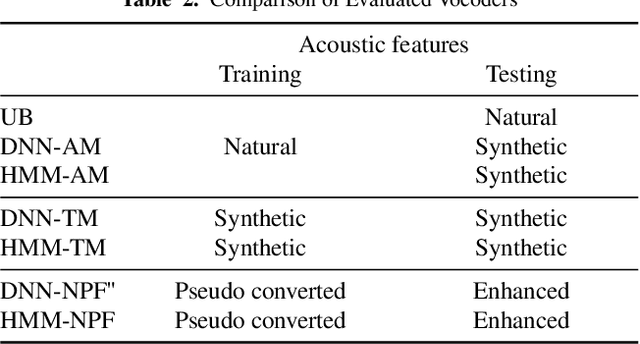
Neural-based text-to-speech (TTS) systems achieve very high-fidelity speech generation because of the rapid neural network developments. However, the huge labeled corpus and high computation cost requirements limit the possibility of developing a high-fidelity TTS system by small companies or individuals. On the other hand, a neural vocoder, which has been widely adopted for the speech generation in neural-based TTS systems, can be trained with a relatively small unlabeled corpus. Therefore, in this paper, we explore a general framework to develop a neural post-filter (NPF) for low-cost TTS systems using neural vocoders. A cyclical approach is proposed to tackle the acoustic and temporal mismatches (AM and TM) of developing an NPF. Both objective and subjective evaluations have been conducted to demonstrate the AM and TM problems and the effectiveness of the proposed framework.