 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Multimodal Fusion with Contrastive Learning for Turn-taking Prediction in Human-robot Dialogue
Apr 18, 2022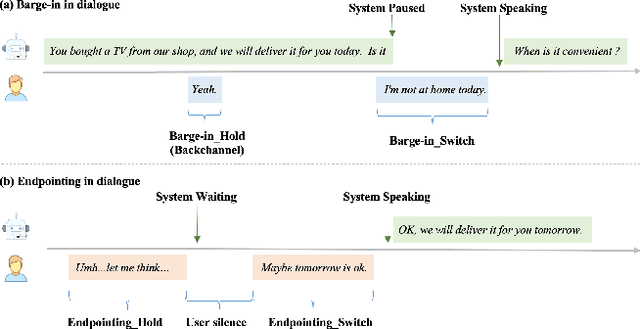
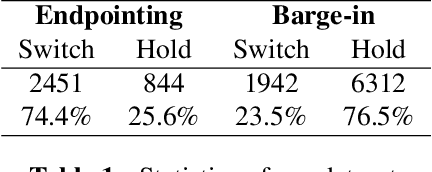
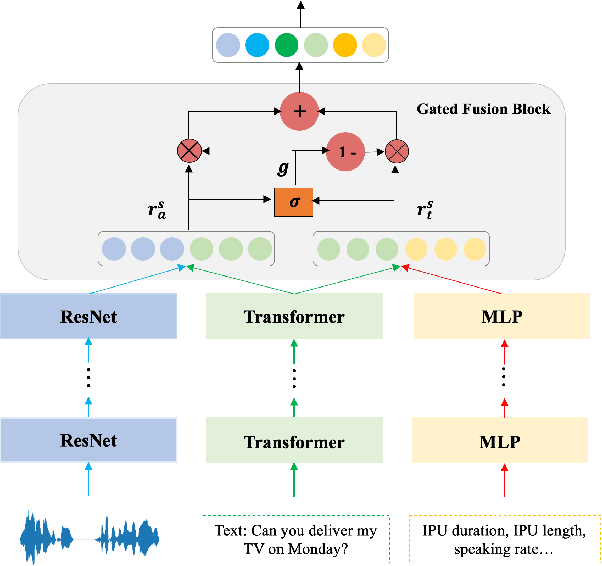
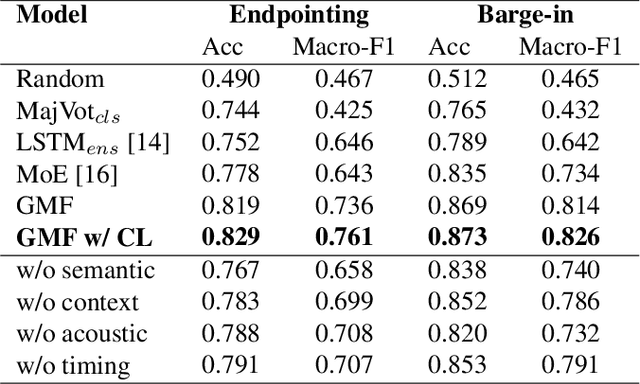
Turn-taking, aiming to decide when the next speaker can start talking, is an essential component in building human-robot spoken dialogue systems. Previous studies indicate that multimodal cues can facilitate this challenging task. However, due to the paucity of public multimodal datasets, current methods are mostly limited to either utilizing unimodal features or simplistic multimodal ensemble models. Besides, the inherent class imbalance in real scenario, e.g. sentence ending with short pause will be mostly regarded as the end of turn, also poses great challenge to the turn-taking decision. In this paper, we first collect a large-scale annotated corpus for turn-taking with over 5,000 real human-robot dialogues in speech and text modalities. Then, a novel gated multimodal fusion mechanism is devised to utilize various information seamlessly for turn-taking prediction. More importantly, to tackle the data imbalance issue, we design a simple yet effective data augmentation method to construct negative instances without supervision and apply contrastive learning to obtain better feature representations. Extensive experiments are conducted and the results demonstrate the superiority and competitiveness of our model over several state-of-the-art baselines.
Harnessing Interpretable Machine Learning for Origami Feature Design and Pattern Selection
Apr 12, 2022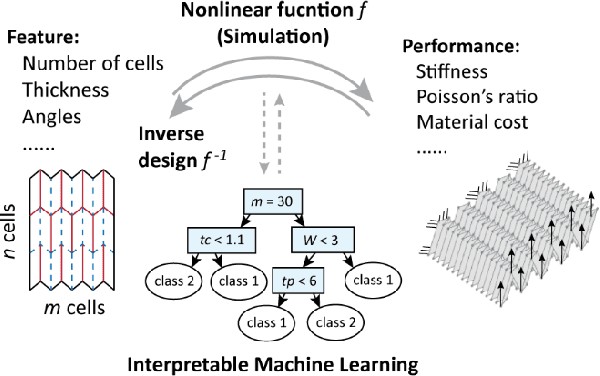
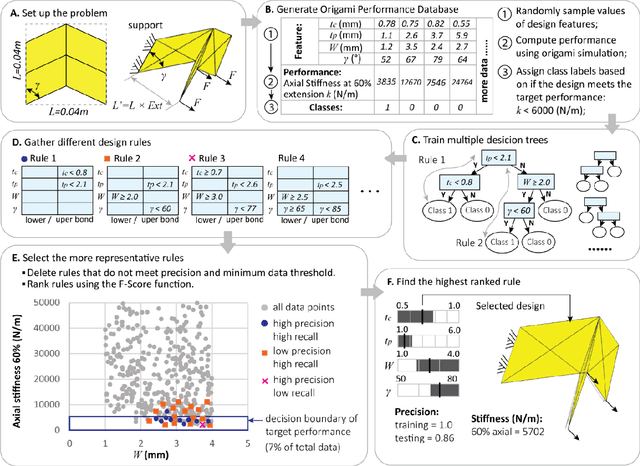
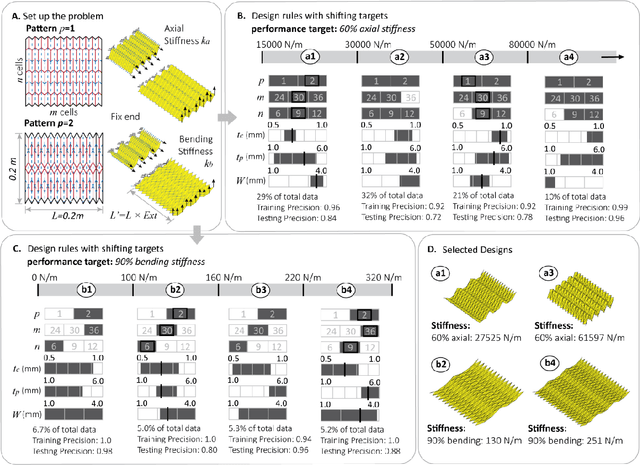
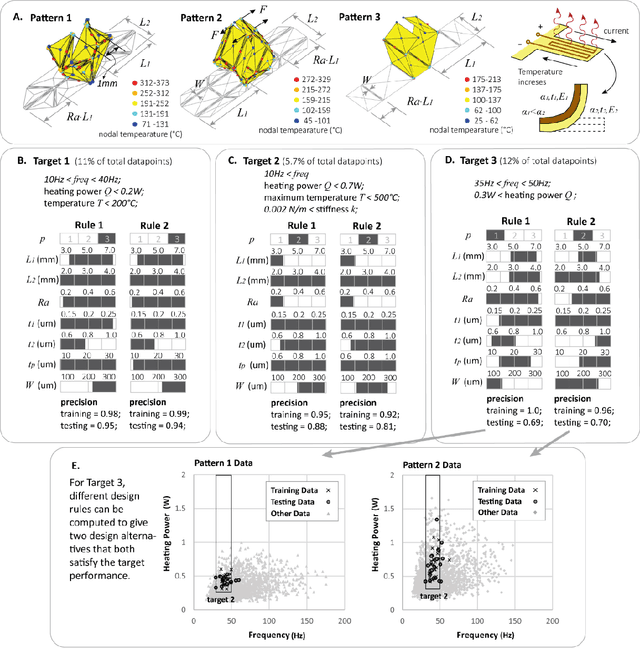
Engineering design of origami systems is challenging because comparing different origami patterns requires using categorical features and evaluating multi-physics behavior targets introduces multi-objective problems. This work shows that a decision tree machine learning method is particularly suitable for the inverse design of origami. This interpretable machine learning method can reveal complex interactions between categorical features and continuous features for comparing different origami patterns, can tackle multi-objective problems for designing active origami with multi-physics performance targets, and can extend existing origami shape fitting algorithms to further consider non-geometrical performances of origami systems. The proposed framework shows a holistic way of designing active origami systems for various applications such as metamaterials, deployable structures, soft robots, biomedical devices, and many more.
ImpDet: Exploring Implicit Fields for 3D Object Detection
Mar 31, 2022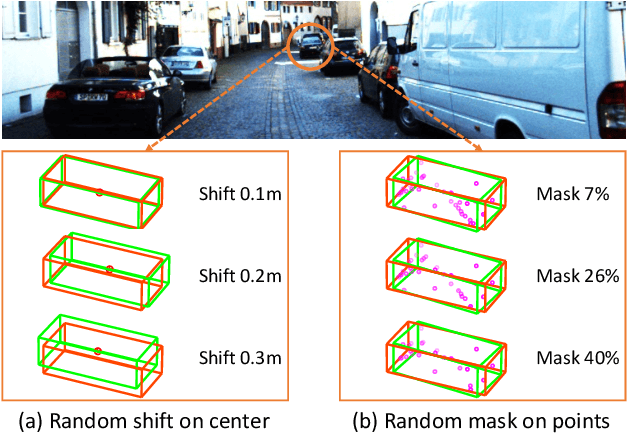
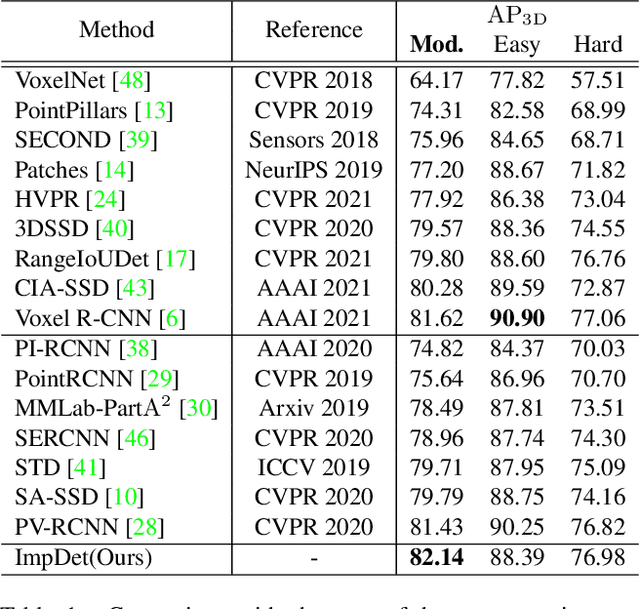
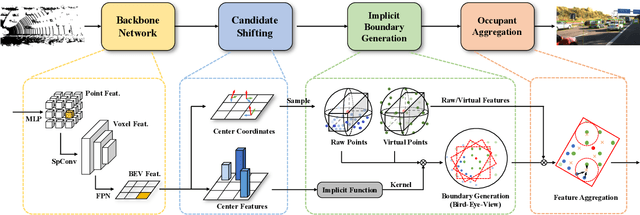
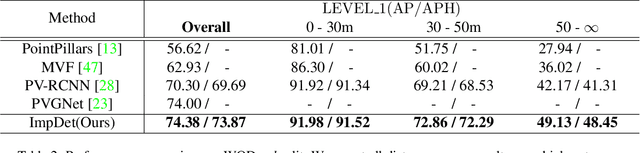
Conventional 3D object detection approaches concentrate on bounding boxes representation learning with several parameters, i.e., localization, dimension, and orientation. Despite its popularity and universality, such a straightforward paradigm is sensitive to slight numerical deviations, especially in localization. By exploiting the property that point clouds are naturally captured on the surface of objects along with accurate location and intensity information, we introduce a new perspective that views bounding box regression as an implicit function. This leads to our proposed framework, termed Implicit Detection or ImpDet, which leverages implicit field learning for 3D object detection. Our ImpDet assigns specific values to points in different local 3D spaces, thereby high-quality boundaries can be generated by classifying points inside or outside the boundary. To solve the problem of sparsity on the object surface, we further present a simple yet efficient virtual sampling strategy to not only fill the empty region, but also learn rich semantic features to help refine the boundaries. Extensive experimental results on KITTI and Waymo benchmarks demonstrate the effectiveness and robustness of unifying implicit fields into object detection.
Prompt-Learning for Short Text Classification
Mar 31, 2022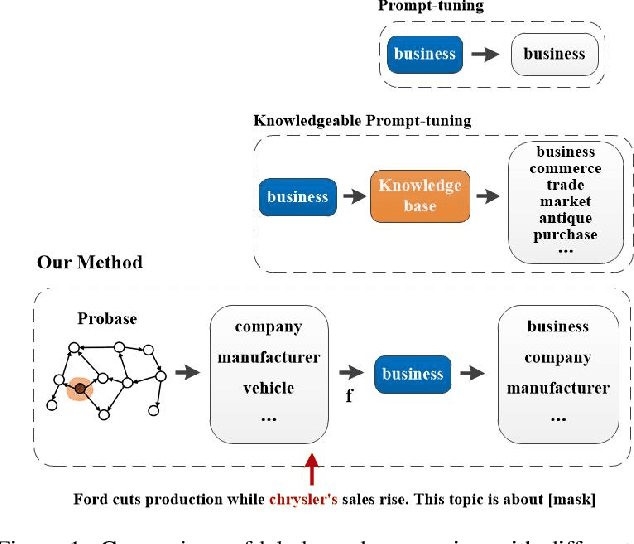

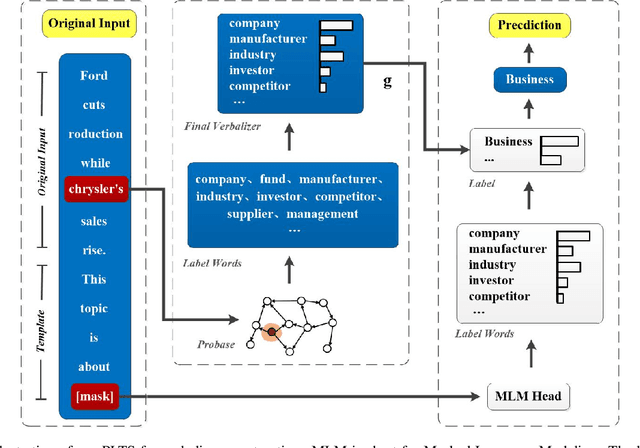
In the short text, the extremely short length, feature sparsity, and high ambiguity pose huge challenges to classification tasks. Recently, as an effective method for tuning Pre-trained Language Models for specific downstream tasks, prompt-learning has attracted a vast amount of attention and research. The main intuition behind the prompt-learning is to insert the template into the input and convert the text classification tasks into equivalent cloze-style tasks. However, most prompt-learning methods expand label words manually or only consider the class name for knowledge incorporating in cloze-style prediction, which will inevitably incur omissions and bias in short text classification tasks. In this paper, we propose a simple short text classification approach that makes use of prompt-learning based on knowledgeable expansion. Taking the special characteristics of short text into consideration, the method can consider both the short text itself and class name during expanding label words space. Specifically, the top $N$ concepts related to the entity in the short text are retrieved from the open Knowledge Graph like Probase, and we further refine the expanded label words by the distance calculation between selected concepts and class labels. Experimental results show that our approach obtains obvious improvement compared with other fine-tuning, prompt-learning, and knowledgeable prompt-tuning methods, outperforming the state-of-the-art by up to 6 Accuracy points on three well-known datasets.
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
Mar 24, 2022
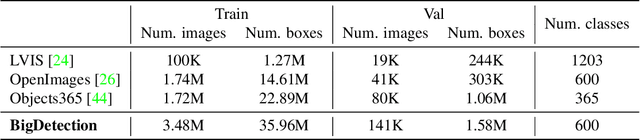
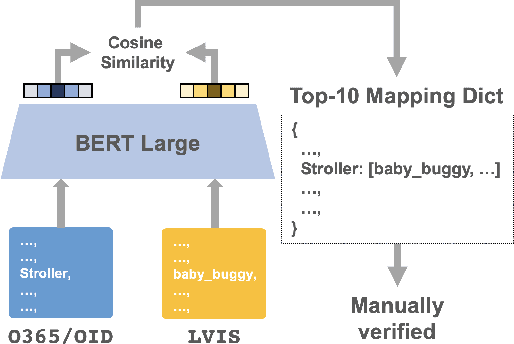
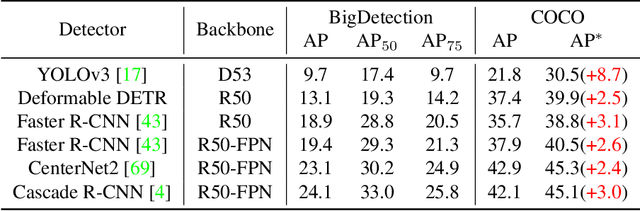
Multiple datasets and open challenges for object detection have been introduced in recent years. To build more general and powerful object detection systems, in this paper, we construct a new large-scale benchmark termed BigDetection. Our goal is to simply leverage the training data from existing datasets (LVIS, OpenImages and Object365) with carefully designed principles, and curate a larger dataset for improved detector pre-training. Specifically, we generate a new taxonomy which unifies the heterogeneous label spaces from different sources. Our BigDetection dataset has 600 object categories and contains over 3.4M training images with 36M bounding boxes. It is much larger in multiple dimensions than previous benchmarks, which offers both opportunities and challenges. Extensive experiments demonstrate its validity as a new benchmark for evaluating different object detection methods, and its effectiveness as a pre-training dataset.
Building Robust Spoken Language Understanding by Cross Attention between Phoneme Sequence and ASR Hypothesis
Mar 22, 2022
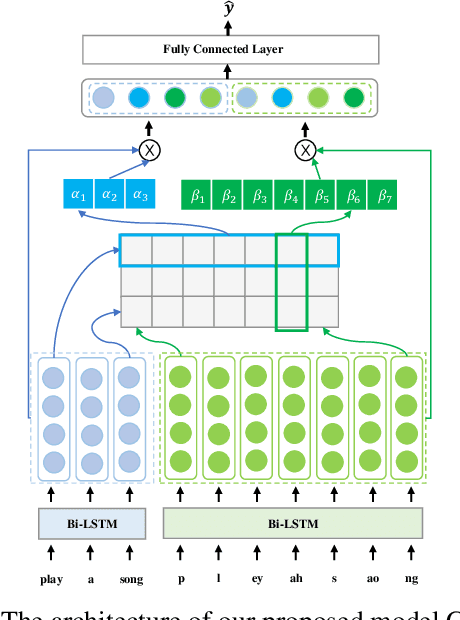
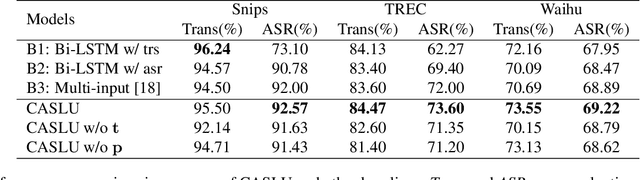
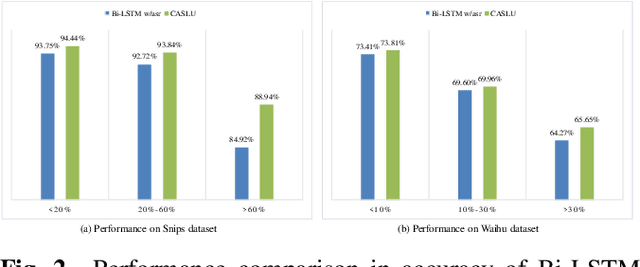
Building Spoken Language Understanding (SLU) robust to Automatic Speech Recognition (ASR) errors is an essential issue for various voice-enabled virtual assistants. Considering that most ASR errors are caused by phonetic confusion between similar-sounding expressions, intuitively, leveraging the phoneme sequence of speech can complement ASR hypothesis and enhance the robustness of SLU. This paper proposes a novel model with Cross Attention for SLU (denoted as CASLU). The cross attention block is devised to catch the fine-grained interactions between phoneme and word embeddings in order to make the joint representations catch the phonetic and semantic features of input simultaneously and for overcoming the ASR errors in downstream natural language understanding (NLU) tasks. Extensive experiments are conducted on three datasets, showing the effectiveness and competitiveness of our approach. Additionally, We also validate the universality of CASLU and prove its complementarity when combining with other robust SLU techniques.
Contrastive Instruction-Trajectory Learning for Vision-Language Navigation
Dec 09, 2021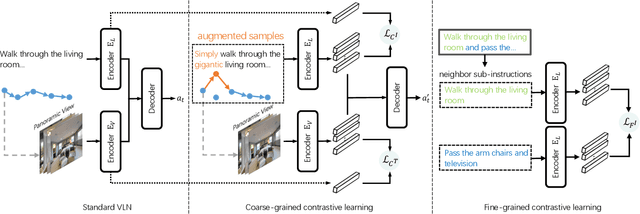
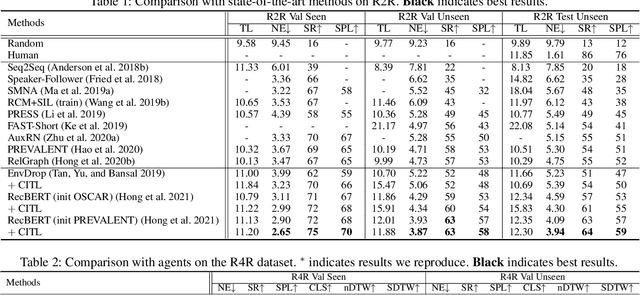
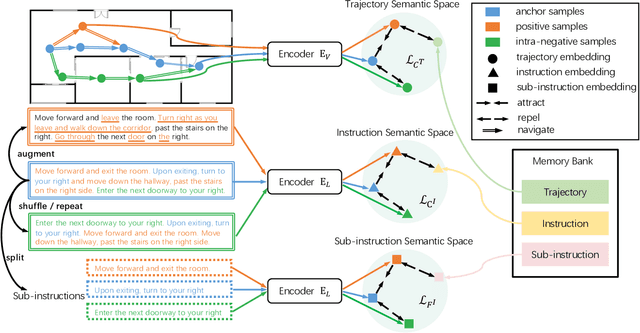
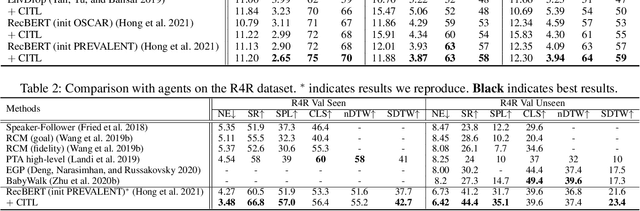
The vision-language navigation (VLN) task requires an agent to reach a target with the guidance of natural language instruction. Previous works learn to navigate step-by-step following an instruction. However, these works may fail to discriminate the similarities and discrepancies across instruction-trajectory pairs and ignore the temporal continuity of sub-instructions. These problems hinder agents from learning distinctive vision-and-language representations, harming the robustness and generalizability of the navigation policy. In this paper, we propose a Contrastive Instruction-Trajectory Learning (CITL) framework that explores invariance across similar data samples and variance across different ones to learn distinctive representations for robust navigation. Specifically, we propose: (1) a coarse-grained contrastive learning objective to enhance vision-and-language representations by contrasting semantics of full trajectory observations and instructions, respectively; (2) a fine-grained contrastive learning objective to perceive instructions by leveraging the temporal information of the sub-instructions; (3) a pairwise sample-reweighting mechanism for contrastive learning to mine hard samples and hence mitigate the influence of data sampling bias in contrastive learning. Our CITL can be easily integrated with VLN backbones to form a new learning paradigm and achieve better generalizability in unseen environments. Extensive experiments show that the model with CITL surpasses the previous state-of-the-art methods on R2R, R4R, and RxR.
Blending Anti-Aliasing into Vision Transformer
Oct 28, 2021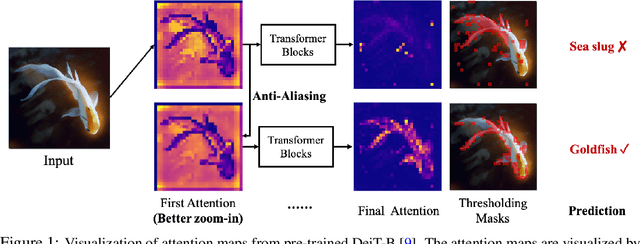
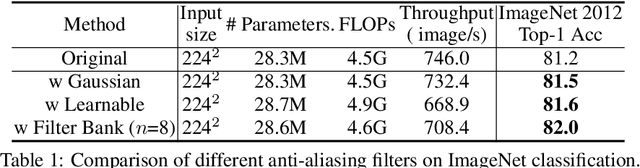

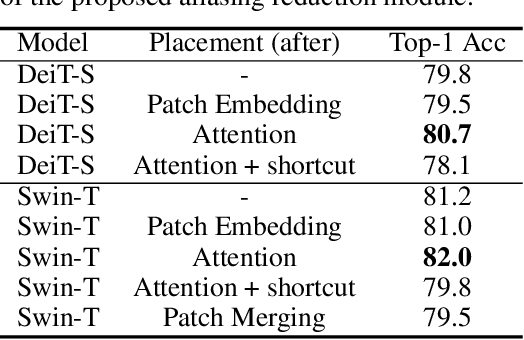
The transformer architectures, based on self-attention mechanism and convolution-free design, recently found superior performance and booming applications in computer vision. However, the discontinuous patch-wise tokenization process implicitly introduces jagged artifacts into attention maps, arising the traditional problem of aliasing for vision transformers. Aliasing effect occurs when discrete patterns are used to produce high frequency or continuous information, resulting in the indistinguishable distortions. Recent researches have found that modern convolution networks still suffer from this phenomenon. In this work, we analyze the uncharted problem of aliasing in vision transformer and explore to incorporate anti-aliasing properties. Specifically, we propose a plug-and-play Aliasing-Reduction Module(ARM) to alleviate the aforementioned issue. We investigate the effectiveness and generalization of the proposed method across multiple tasks and various vision transformer families. This lightweight design consistently attains a clear boost over several famous structures. Furthermore, our module also improves data efficiency and robustness of vision transformers.
CrossCLR: Cross-modal Contrastive Learning For Multi-modal Video Representations
Sep 30, 2021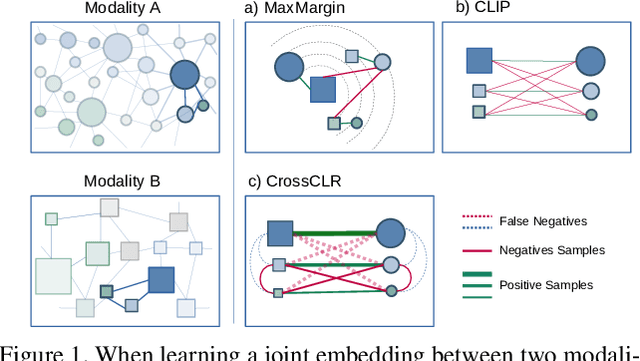

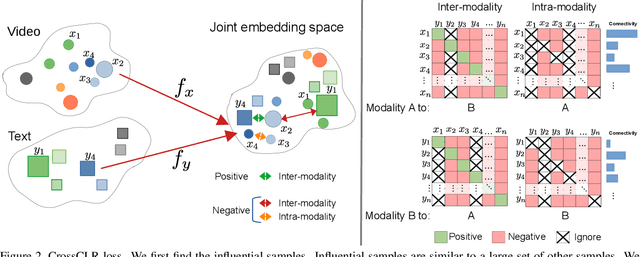

Contrastive learning allows us to flexibly define powerful losses by contrasting positive pairs from sets of negative samples. Recently, the principle has also been used to learn cross-modal embeddings for video and text, yet without exploiting its full potential. In particular, previous losses do not take the intra-modality similarities into account, which leads to inefficient embeddings, as the same content is mapped to multiple points in the embedding space. With CrossCLR, we present a contrastive loss that fixes this issue. Moreover, we define sets of highly related samples in terms of their input embeddings and exclude them from the negative samples to avoid issues with false negatives. We show that these principles consistently improve the quality of the learned embeddings. The joint embeddings learned with CrossCLR extend the state of the art in video-text retrieval on Youcook2 and LSMDC datasets and in video captioning on Youcook2 dataset by a large margin. We also demonstrate the generality of the concept by learning improved joint embeddings for other pairs of modalities.
An Unsupervised Method for Building Sentence Simplification Corpora in Multiple Languages
Sep 01, 2021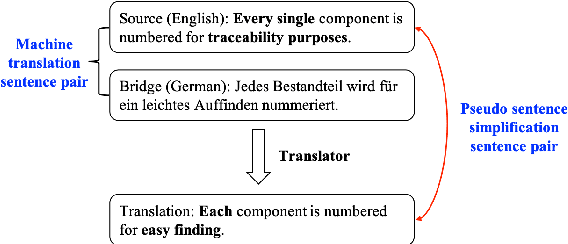

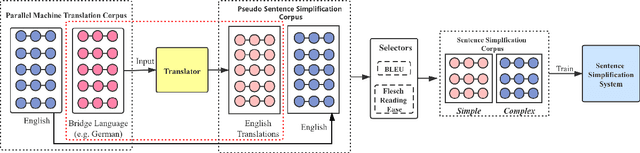
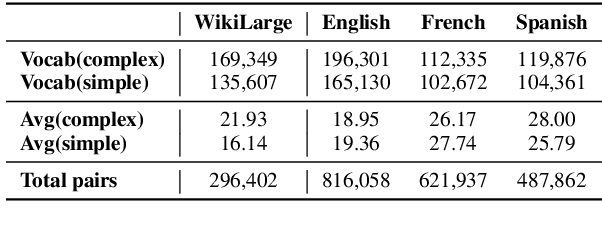
The availability of parallel sentence simplification (SS) is scarce for neural SS modelings. We propose an unsupervised method to build SS corpora from large-scale bilingual translation corpora, alleviating the need for SS supervised corpora. Our method is motivated by the following two findings: neural machine translation model usually tends to generate more high-frequency tokens and the difference of text complexity levels exists between the source and target language of a translation corpus. By taking the pair of the source sentences of translation corpus and the translations of their references in a bridge language, we can construct large-scale pseudo parallel SS data. Then, we keep these sentence pairs with a higher complexity difference as SS sentence pairs. The building SS corpora with an unsupervised approach can satisfy the expectations that the aligned sentences preserve the same meanings and have difference in text complexity levels. Experimental results show that SS methods trained by our corpora achieve the state-of-the-art results and significantly outperform the results on English benchmark WikiLarge.