 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancement of 3D Gaussian Splatting using Raw Mesh for Photorealistic Recreation of Architectures
Jul 22, 2024The photorealistic reconstruction and rendering of architectural scenes have extensive applications in industries such as film, games, and transportation. It also plays an important role in urban planning, architectural design, and the city's promotion, especially in protecting historical and cultural relics. The 3D Gaussian Splatting, due to better performance over NeRF, has become a mainstream technology in 3D reconstruction. Its only input is a set of images but it relies heavily on geometric parameters computed by the SfM process. At the same time, there is an existing abundance of raw 3D models, that could inform the structural perception of certain buildings but cannot be applied. In this paper, we propose a straightforward method to harness these raw 3D models to guide 3D Gaussians in capturing the basic shape of the building and improve the visual quality of textures and details when photos are captured non-systematically. This exploration opens up new possibilities for improving the effectiveness of 3D reconstruction techniques in the field of architectural design.
Optimizing Large Model Training through Overlapped Activation Recomputation
Jun 13, 2024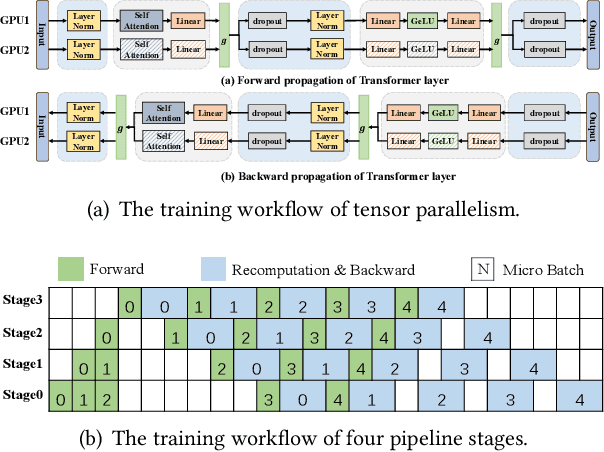
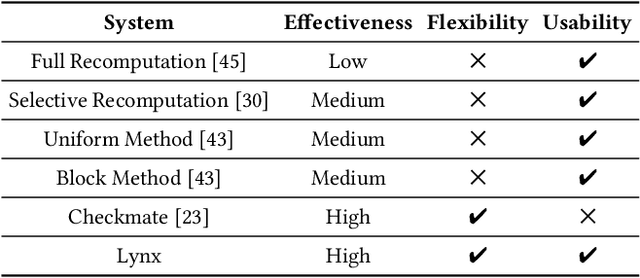
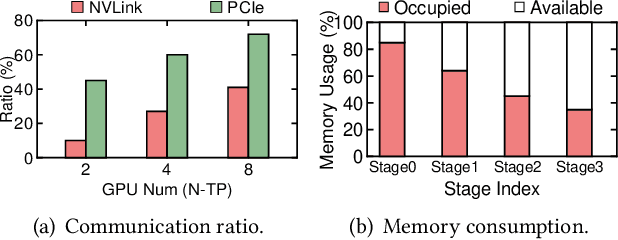
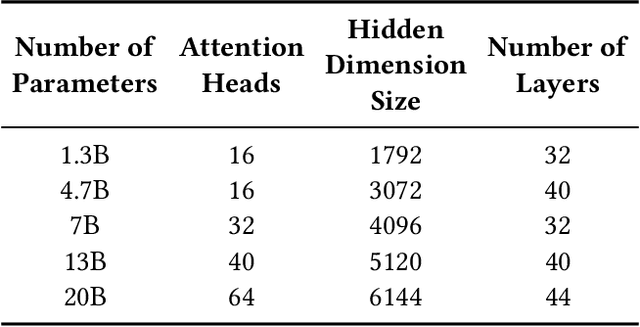
Large model training has been using recomputation to alleviate the memory pressure and pipelining to exploit the parallelism of data, tensor, and devices. The existing recomputation approaches may incur up to 40% overhead when training real-world models, e.g., the GPT model with 22B parameters. This is because they are executed on demand in the critical training path. In this paper, we design a new recomputation framework, Lynx, to reduce the overhead by overlapping the recomputation with communication occurring in training pipelines. It consists of an optimal scheduling algorithm (OPT) and a heuristic-based scheduling algorithm (HEU). OPT achieves a global optimum but suffers from a long search time. HEU was designed based on our observation that there are identical structures in large DNN models so that we can apply the same scheduling policy to all identical structures. HEU achieves a local optimum but reduces the search time by 99% compared to OPT. Our comprehensive evaluation using GPT models with 1.3B-20B parameters shows that both OPT and HEU outperform the state-of-the-art recomputation approaches (e.g., Megatron-LM and Checkmake) by 1.02-1.53x. HEU achieves a similar performance as OPT with a search time of 0.16s on average.
Caching-Augmented Lifelong Multi-Agent Path Finding
Mar 29, 2024



Multi-Agent Path Finding (MAPF), which involves finding collision-free paths for multiple robots, is crucial in various applications. Lifelong MAPF, where targets are reassigned to agents as soon as they complete their initial targets, offers a more accurate approximation of real-world warehouse planning. In this paper, we present a novel mechanism named Caching-Augmented Lifelong MAPF (CAL-MAPF), designed to improve the performance of Lifelong MAPF. We have developed a new type of map grid called cache for temporary item storage and replacement, and designed a locking mechanism for it to improve the stability of the planning solution. This cache mechanism was evaluated using various cache replacement policies and a spectrum of input task distributions. We identified three main factors significantly impacting CAL-MAPF performance through experimentation: suitable input task distribution, high cache hit rate, and smooth traffic. In general, CAL-MAPF has demonstrated potential for performance improvements in certain task distributions, maps, and agent configurations.
Adapprox: Adaptive Approximation in Adam Optimization via Randomized Low-Rank Matrices
Mar 22, 2024As deep learning models exponentially increase in size, optimizers such as Adam encounter significant memory consumption challenges due to the storage of first and second moment data. Current memory-efficient methods like Adafactor and CAME often compromise accuracy with their matrix factorization techniques. Addressing this, we introduce Adapprox, a novel approach that employs randomized low-rank matrix approximation for a more effective and accurate approximation of Adam's second moment. Adapprox features an adaptive rank selection mechanism, finely balancing accuracy and memory efficiency, and includes an optional cosine similarity guidance strategy to enhance stability and expedite convergence. In GPT-2 training and downstream tasks, Adapprox surpasses AdamW by achieving 34.5% to 49.9% and 33.8% to 49.9% memory savings for the 117M and 345M models, respectively, with the first moment enabled, and further increases these savings without the first moment. Besides, it enhances convergence speed and improves downstream task performance relative to its counterparts.
A General and Flexible Multi-concept Parsing Framework for Multilingual Semantic Matching
Mar 05, 2024



Sentence semantic matching is a research hotspot in natural language processing, which is considerably significant in various key scenarios, such as community question answering, searching, chatbot, and recommendation. Since most of the advanced models directly model the semantic relevance among words between two sentences while neglecting the \textit{keywords} and \textit{intents} concepts of them, DC-Match is proposed to disentangle keywords from intents and utilizes them to optimize the matching performance. Although DC-Match is a simple yet effective method for semantic matching, it highly depends on the external NER techniques to identify the keywords of sentences, which limits the performance of semantic matching for minor languages since satisfactory NER tools are usually hard to obtain. In this paper, we propose to generally and flexibly resolve the text into multi concepts for multilingual semantic matching to liberate the model from the reliance on NER models. To this end, we devise a \underline{M}ulti-\underline{C}oncept \underline{P}arsed \underline{S}emantic \underline{M}atching framework based on the pre-trained language models, abbreviated as \textbf{MCP-SM}, to extract various concepts and infuse them into the classification tokens. We conduct comprehensive experiments on English datasets QQP and MRPC, and Chinese dataset Medical-SM. Besides, we experiment on Arabic datasets MQ2Q and XNLI, the outstanding performance further prove MCP-SM's applicability in low-resource languages.
Deep Reinforcement Learning for Solving Management Problems: Towards A Large Management Mode
Mar 01, 2024



We introduce a deep reinforcement learning (DRL) approach for solving management problems including inventory management, dynamic pricing, and recommendation. This DRL approach has the potential to lead to a large management model based on certain transformer neural network structures, resulting in an artificial general intelligence paradigm for various management tasks. Traditional methods have limitations for solving complex real-world problems, and we demonstrate how DRL can surpass existing heuristic approaches for solving management tasks. We aim to solve the problems in a unified framework, considering the interconnections between different tasks. Central to our methodology is the development of a foundational decision model coordinating decisions across the different domains through generative decision-making. Our experimental results affirm the effectiveness of our DRL-based framework in complex and dynamic business environments. This work opens new pathways for the application of DRL in management problems, highlighting its potential to revolutionize traditional business management.
Agents meet OKR: An Object and Key Results Driven Agent System with Hierarchical Self-Collaboration and Self-Evaluation
Nov 28, 2023



In this study, we introduce the concept of OKR-Agent designed to enhance the capabilities of Large Language Models (LLMs) in task-solving. Our approach utilizes both self-collaboration and self-correction mechanism, facilitated by hierarchical agents, to address the inherent complexities in task-solving. Our key observations are two-fold: first, effective task-solving demands in-depth domain knowledge and intricate reasoning, for which deploying specialized agents for individual sub-tasks can markedly enhance LLM performance. Second, task-solving intrinsically adheres to a hierarchical execution structure, comprising both high-level strategic planning and detailed task execution. Towards this end, our OKR-Agent paradigm aligns closely with this hierarchical structure, promising enhanced efficacy and adaptability across a range of scenarios. Specifically, our framework includes two novel modules: hierarchical Objects and Key Results generation and multi-level evaluation, each contributing to more efficient and robust task-solving. In practical, hierarchical OKR generation decomposes Objects into multiple sub-Objects and assigns new agents based on key results and agent responsibilities. These agents subsequently elaborate on their designated tasks and may further decompose them as necessary. Such generation operates recursively and hierarchically, culminating in a comprehensive set of detailed solutions. The multi-level evaluation module of OKR-Agent refines solution by leveraging feedback from all associated agents, optimizing each step of the process. This ensures solution is accurate, practical, and effectively address intricate task requirements, enhancing the overall reliability and quality of the outcome. Experimental results also show our method outperforms the previous methods on several tasks. Code and demo are available at https://okr-agent.github.io/
AraMUS: Pushing the Limits of Data and Model Scale for Arabic Natural Language Processing
Jun 11, 2023



Developing monolingual large Pre-trained Language Models (PLMs) is shown to be very successful in handling different tasks in Natural Language Processing (NLP). In this work, we present AraMUS, the largest Arabic PLM with 11B parameters trained on 529GB of high-quality Arabic textual data. AraMUS achieves state-of-the-art performances on a diverse set of Arabic classification and generative tasks. Moreover, AraMUS shows impressive few-shot learning abilities compared with the best existing Arabic PLMs.
Differentiable modeling to unify machine learning and physical models and advance Geosciences
Jan 10, 2023



Process-Based Modeling (PBM) and Machine Learning (ML) are often perceived as distinct paradigms in the geosciences. Here we present differentiable geoscientific modeling as a powerful pathway toward dissolving the perceived barrier between them and ushering in a paradigm shift. For decades, PBM offered benefits in interpretability and physical consistency but struggled to efficiently leverage large datasets. ML methods, especially deep networks, presented strong predictive skills yet lacked the ability to answer specific scientific questions. While various methods have been proposed for ML-physics integration, an important underlying theme -- differentiable modeling -- is not sufficiently recognized. Here we outline the concepts, applicability, and significance of differentiable geoscientific modeling (DG). "Differentiable" refers to accurately and efficiently calculating gradients with respect to model variables, critically enabling the learning of high-dimensional unknown relationships. DG refers to a range of methods connecting varying amounts of prior knowledge to neural networks and training them together, capturing a different scope than physics-guided machine learning and emphasizing first principles. Preliminary evidence suggests DG offers better interpretability and causality than ML, improved generalizability and extrapolation capability, and strong potential for knowledge discovery, while approaching the performance of purely data-driven ML. DG models require less training data while scaling favorably in performance and efficiency with increasing amounts of data. With DG, geoscientists may be better able to frame and investigate questions, test hypotheses, and discover unrecognized linkages.
ReCo: Reliable Causal Chain Reasoning via Structural Causal Recurrent Neural Networks
Dec 16, 2022Causal chain reasoning (CCR) is an essential ability for many decision-making AI systems, which requires the model to build reliable causal chains by connecting causal pairs. However, CCR suffers from two main transitive problems: threshold effect and scene drift. In other words, the causal pairs to be spliced may have a conflicting threshold boundary or scenario. To address these issues, we propose a novel Reliable Causal chain reasoning framework~(ReCo), which introduces exogenous variables to represent the threshold and scene factors of each causal pair within the causal chain, and estimates the threshold and scene contradictions across exogenous variables via structural causal recurrent neural networks~(SRNN). Experiments show that ReCo outperforms a series of strong baselines on both Chinese and English CCR datasets. Moreover, by injecting reliable causal chain knowledge distilled by ReCo, BERT can achieve better performances on four downstream causal-related tasks than BERT models enhanced by other kinds of knowledge.