 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral and Task-Oriented Video Segmentation
Jul 09, 2024



We present GvSeg, a general video segmentation framework for addressing four different video segmentation tasks (i.e., instance, semantic, panoptic, and exemplar-guided) while maintaining an identical architectural design. Currently, there is a trend towards developing general video segmentation solutions that can be applied across multiple tasks. This streamlines research endeavors and simplifies deployment. However, such a highly homogenized framework in current design, where each element maintains uniformity, could overlook the inherent diversity among different tasks and lead to suboptimal performance. To tackle this, GvSeg: i) provides a holistic disentanglement and modeling for segment targets, thoroughly examining them from the perspective of appearance, position, and shape, and on this basis, ii) reformulates the query initialization, matching and sampling strategies in alignment with the task-specific requirement. These architecture-agnostic innovations empower GvSeg to effectively address each unique task by accommodating the specific properties that characterize them. Extensive experiments on seven gold-standard benchmark datasets demonstrate that GvSeg surpasses all existing specialized/general solutions by a significant margin on four different video segmentation tasks.
TAPVid-3D: A Benchmark for Tracking Any Point in 3D
Jul 08, 2024



We introduce a new benchmark, TAPVid-3D, for evaluating the task of long-range Tracking Any Point in 3D (TAP-3D). While point tracking in two dimensions (TAP) has many benchmarks measuring performance on real-world videos, such as TAPVid-DAVIS, three-dimensional point tracking has none. To this end, leveraging existing footage, we build a new benchmark for 3D point tracking featuring 4,000+ real-world videos, composed of three different data sources spanning a variety of object types, motion patterns, and indoor and outdoor environments. To measure performance on the TAP-3D task, we formulate a collection of metrics that extend the Jaccard-based metric used in TAP to handle the complexities of ambiguous depth scales across models, occlusions, and multi-track spatio-temporal smoothness. We manually verify a large sample of trajectories to ensure correct video annotations, and assess the current state of the TAP-3D task by constructing competitive baselines using existing tracking models. We anticipate this benchmark will serve as a guidepost to improve our ability to understand precise 3D motion and surface deformation from monocular video. Code for dataset download, generation, and model evaluation is available at https://tapvid3d.github.io
Enhancing Hallucination Detection through Perturbation-Based Synthetic Data Generation in System Responses
Jul 07, 2024



Detecting hallucinations in large language model (LLM) outputs is pivotal, yet traditional fine-tuning for this classification task is impeded by the expensive and quickly outdated annotation process, especially across numerous vertical domains and in the face of rapid LLM advancements. In this study, we introduce an approach that automatically generates both faithful and hallucinated outputs by rewriting system responses. Experimental findings demonstrate that a T5-base model, fine-tuned on our generated dataset, surpasses state-of-the-art zero-shot detectors and existing synthetic generation methods in both accuracy and latency, indicating efficacy of our approach.
MIGC++: Advanced Multi-Instance Generation Controller for Image Synthesis
Jul 02, 2024



We introduce the Multi-Instance Generation (MIG) task, which focuses on generating multiple instances within a single image, each accurately placed at predefined positions with attributes such as category, color, and shape, strictly following user specifications. MIG faces three main challenges: avoiding attribute leakage between instances, supporting diverse instance descriptions, and maintaining consistency in iterative generation. To address attribute leakage, we propose the Multi-Instance Generation Controller (MIGC). MIGC generates multiple instances through a divide-and-conquer strategy, breaking down multi-instance shading into single-instance tasks with singular attributes, later integrated. To provide more types of instance descriptions, we developed MIGC++. MIGC++ allows attribute control through text \& images and position control through boxes \& masks. Lastly, we introduced the Consistent-MIG algorithm to enhance the iterative MIG ability of MIGC and MIGC++. This algorithm ensures consistency in unmodified regions during the addition, deletion, or modification of instances, and preserves the identity of instances when their attributes are changed. We introduce the COCO-MIG and Multimodal-MIG benchmarks to evaluate these methods. Extensive experiments on these benchmarks, along with the COCO-Position benchmark and DrawBench, demonstrate that our methods substantially outperform existing techniques, maintaining precise control over aspects including position, attribute, and quantity. Project page: https://github.com/limuloo/MIGC.
EconNLI: Evaluating Large Language Models on Economics Reasoning
Jul 01, 2024



Large Language Models (LLMs) are widely used for writing economic analysis reports or providing financial advice, but their ability to understand economic knowledge and reason about potential results of specific economic events lacks systematic evaluation. To address this gap, we propose a new dataset, natural language inference on economic events (EconNLI), to evaluate LLMs' knowledge and reasoning abilities in the economic domain. We evaluate LLMs on (1) their ability to correctly classify whether a premise event will cause a hypothesis event and (2) their ability to generate reasonable events resulting from a given premise. Our experiments reveal that LLMs are not sophisticated in economic reasoning and may generate wrong or hallucinated answers. Our study raises awareness of the limitations of using LLMs for critical decision-making involving economic reasoning and analysis. The dataset and codes are available at https://github.com/Irenehere/EconNLI.
SeFlow: A Self-Supervised Scene Flow Method in Autonomous Driving
Jul 01, 2024



Scene flow estimation predicts the 3D motion at each point in successive LiDAR scans. This detailed, point-level, information can help autonomous vehicles to accurately predict and understand dynamic changes in their surroundings. Current state-of-the-art methods require annotated data to train scene flow networks and the expense of labeling inherently limits their scalability. Self-supervised approaches can overcome the above limitations, yet face two principal challenges that hinder optimal performance: point distribution imbalance and disregard for object-level motion constraints. In this paper, we propose SeFlow, a self-supervised method that integrates efficient dynamic classification into a learning-based scene flow pipeline. We demonstrate that classifying static and dynamic points helps design targeted objective functions for different motion patterns. We also emphasize the importance of internal cluster consistency and correct object point association to refine the scene flow estimation, in particular on object details. Our real-time capable method achieves state-of-the-art performance on the self-supervised scene flow task on Argoverse 2 and Waymo datasets. The code is open-sourced at https://github.com/KTH-RPL/SeFlow along with trained model weights.
Point Tree Transformer for Point Cloud Registration
Jun 25, 2024



Point cloud registration is a fundamental task in the fields of computer vision and robotics. Recent developments in transformer-based methods have demonstrated enhanced performance in this domain. However, the standard attention mechanism utilized in these methods often integrates many low-relevance points, thereby struggling to prioritize its attention weights on sparse yet meaningful points. This inefficiency leads to limited local structure modeling capabilities and quadratic computational complexity. To overcome these limitations, we propose the Point Tree Transformer (PTT), a novel transformer-based approach for point cloud registration that efficiently extracts comprehensive local and global features while maintaining linear computational complexity. The PTT constructs hierarchical feature trees from point clouds in a coarse-to-dense manner, and introduces a novel Point Tree Attention (PTA) mechanism, which follows the tree structure to facilitate the progressive convergence of attended regions towards salient points. Specifically, each tree layer selectively identifies a subset of key points with the highest attention scores. Subsequent layers focus attention on areas of significant relevance, derived from the child points of the selected point set. The feature extraction process additionally incorporates coarse point features that capture high-level semantic information, thus facilitating local structure modeling and the progressive integration of multiscale information. Consequently, PTA empowers the model to concentrate on crucial local structures and derive detailed local information while maintaining linear computational complexity. Extensive experiments conducted on the 3DMatch, ModelNet40, and KITTI datasets demonstrate that our method achieves superior performance over the state-of-the-art methods.
DeltaPhi: Learning Physical Trajectory Residual for PDE Solving
Jun 14, 2024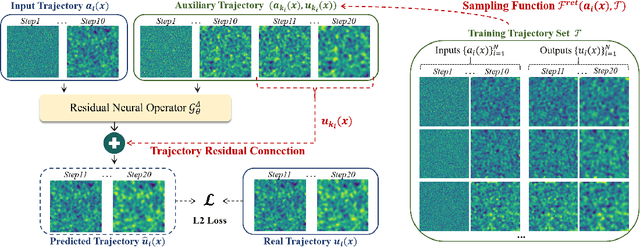
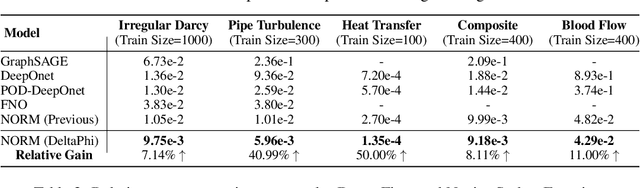
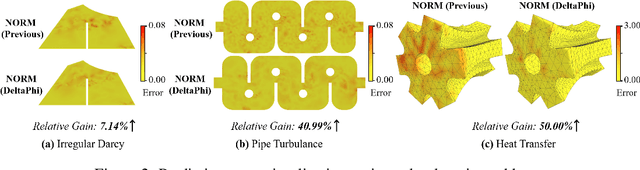
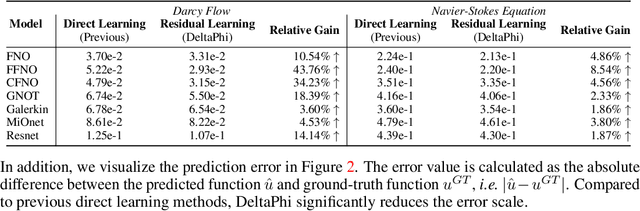
Although neural operator networks theoretically approximate any operator mapping, the limited generalization capability prevents them from learning correct physical dynamics when potential data biases exist, particularly in the practical PDE solving scenario where the available data amount is restricted or the resolution is extremely low. To address this issue, we propose and formulate the Physical Trajectory Residual Learning (DeltaPhi), which learns to predict the physical residuals between the pending solved trajectory and a known similar auxiliary trajectory. First, we transform the direct operator mapping between input-output function fields in original training data to residual operator mapping between input function pairs and output function residuals. Next, we learn the surrogate model for the residual operator mapping based on existing neural operator networks. Additionally, we design helpful customized auxiliary inputs for efficient optimization. Through extensive experiments, we conclude that, compared to direct learning, physical residual learning is preferred for PDE solving.
Know the Unknown: An Uncertainty-Sensitive Method for LLM Instruction Tuning
Jun 14, 2024Large language models (LLMs) have demonstrated remarkable capabilities across various tasks but still face challenges such as hallucinations. One potential reason for hallucinations is the lack of relevant knowledge or context. Thus, a promising solution to mitigate this issue involves instructing LLMs to respond with "I do not know" when a question falls outside their knowledge domain or the provided context. However, in this work, we observed that LLMs struggle to admit their lack of knowledge, primarily due to existing instruction datasets designed to encourage specific answers. To improve large language models' capability to recognize the boundaries of their knowledge, we propose a novel approach called uncertainty-sensitive tuning. This method involves two-stage training designed for uncertainty recognition and prompt-sensitive activation. In the first stage, we guide the LLM to reject unknown questions. In the second stage, we recover the decreased performance in QA tasks by incorporating designed causal instructions. By leveraging this method, we aim to enhance the model's ability to identify areas of uncertainty. The experimental results demonstrate that our proposed uncertainty-sensitive tuning method significantly improves the performance of the Llama2-chat-7B model. Specifically, it achieves a substantial 34.7% improvement in handling questions involving knowledge gaps compared to the original model. Moreover, our approach outperforms GPT-4, exhibiting a 9.4% increase in overall performance. We open-source the model and code on GitHub.
OpenObj: Open-Vocabulary Object-Level Neural Radiance Fields with Fine-Grained Understanding
Jun 12, 2024In recent years, there has been a surge of interest in open-vocabulary 3D scene reconstruction facilitated by visual language models (VLMs), which showcase remarkable capabilities in open-set retrieval. However, existing methods face some limitations: they either focus on learning point-wise features, resulting in blurry semantic understanding, or solely tackle object-level reconstruction, thereby overlooking the intricate details of the object's interior. To address these challenges, we introduce OpenObj, an innovative approach to build open-vocabulary object-level Neural Radiance Fields (NeRF) with fine-grained understanding. In essence, OpenObj establishes a robust framework for efficient and watertight scene modeling and comprehension at the object-level. Moreover, we incorporate part-level features into the neural fields, enabling a nuanced representation of object interiors. This approach captures object-level instances while maintaining a fine-grained understanding. The results on multiple datasets demonstrate that OpenObj achieves superior performance in zero-shot semantic segmentation and retrieval tasks. Additionally, OpenObj supports real-world robotics tasks at multiple scales, including global movement and local manipulation.