 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compositional Feature Embedding and Similarity Metric for Ultra-Fine-Grained Visual Categorization
Oct 06, 2021
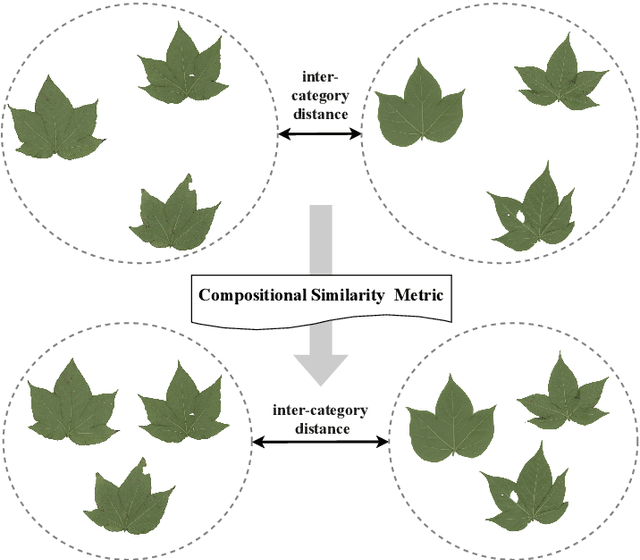
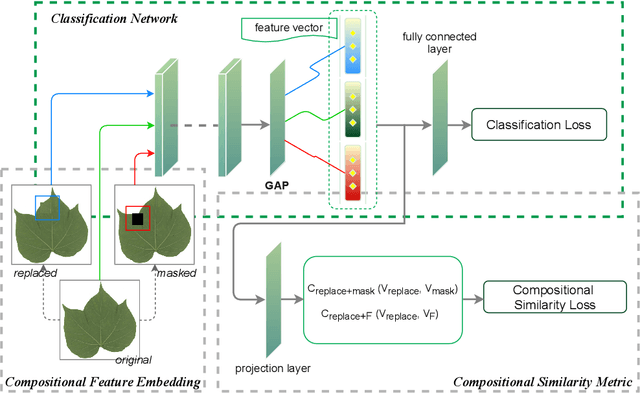
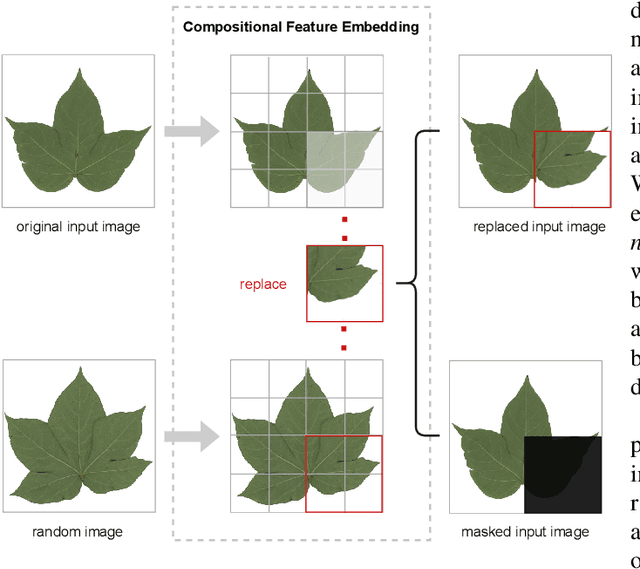
Fine-grained visual categorization (FGVC), which aims at classifying objects with small inter-class variances, has been significantly advanced in recent years. However, ultra-fine-grained visual categorization (ultra-FGVC), which targets at identifying subclasses with extremely similar patterns, has not received much attention. In ultra-FGVC datasets, the samples per category are always scarce as the granularity moves down, which will lead to overfitting problems. Moreover, the difference among different categories is too subtle to distinguish even for professional experts. Motivated by these issues, this paper proposes a novel compositional feature embedding and similarity metric (CECS). Specifically, in the compositional feature embedding module, we randomly select patches in the original input image, and these patches are then replaced by patches from the images of different categories or masked out. Then the replaced and masked images are used to augment the original input images, which can provide more diverse samples and thus largely alleviate overfitting problem resulted from limited training samples. Besides, learning with diverse samples forces the model to learn not only the most discriminative features but also other informative features in remaining regions, enhancing the generalization and robustness of the model. In the compositional similarity metric module, a new similarity metric is developed to improve the classification performance by narrowing the intra-category distance and enlarging the inter-category distance. Experimental results on two ultra-FGVC datasets and one FGVC dataset with recent benchmark methods consistently demonstrate that the proposed CECS method achieves the state of-the-art performance.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021
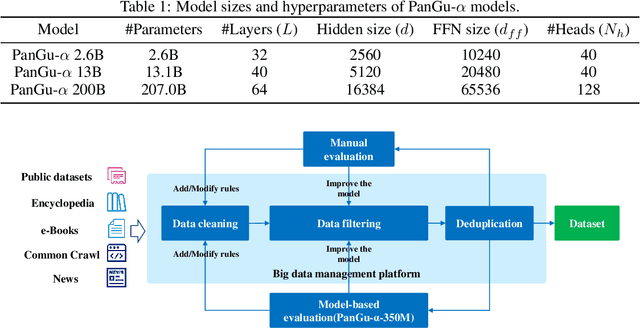
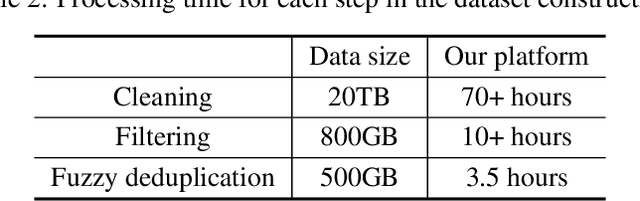
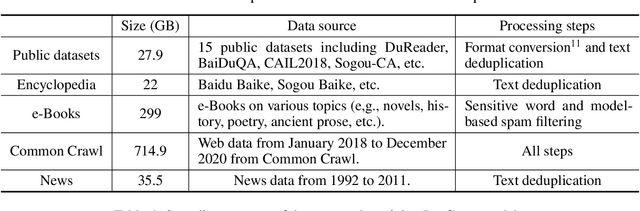
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.
Probabilistically Masked Language Model Capable of Autoregressive Generation in Arbitrary Word Order
Apr 24, 2020
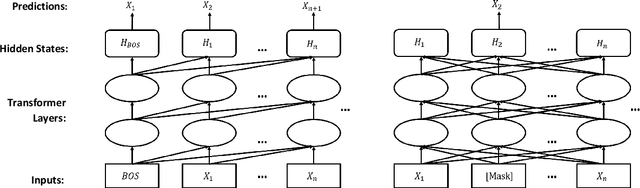
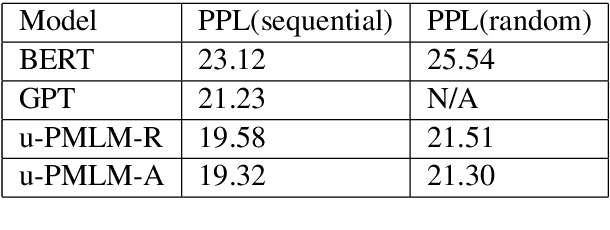
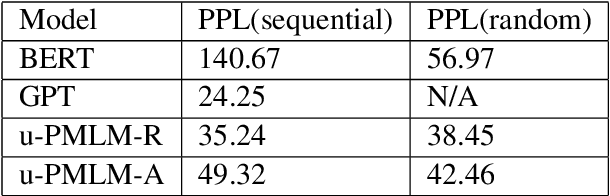
Masked language model and autoregressive language model are two types of language models. While pretrained masked language models such as BERT overwhelm the line of natural language understanding (NLU) tasks, autoregressive language models such as GPT are especially capable in natural language generation (NLG). In this paper, we propose a probabilistic masking scheme for the masked language model, which we call probabilistically masked language model (PMLM). We implement a specific PMLM with a uniform prior distribution on the masking ratio named u-PMLM. We prove that u-PMLM is equivalent to an autoregressive permutated language model. One main advantage of the model is that it supports text generation in arbitrary order with surprisingly good quality, which could potentially enable new applications over traditional unidirectional generation. Besides, the pretrained u-PMLM also outperforms BERT on a set of downstream NLU tasks.
Interpreting Predictive Process Monitoring Benchmarks
Dec 22, 2019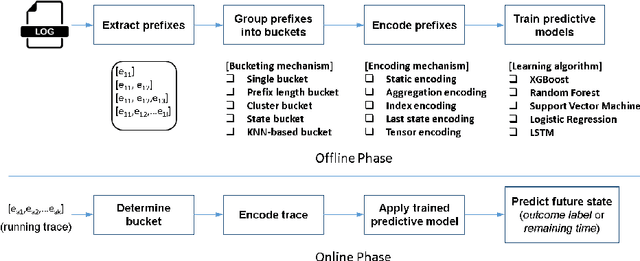

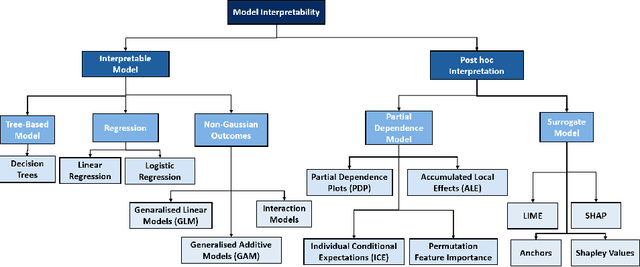
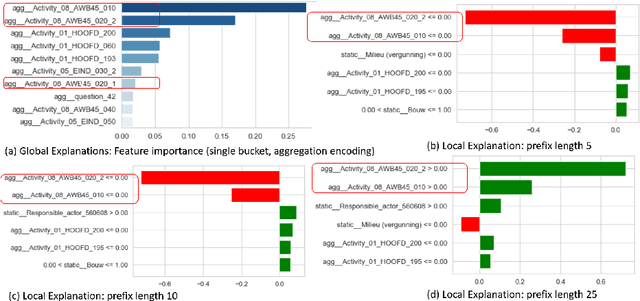
Predictive process analytics has recently gained significant attention, and yet its successful adoption in organisations relies on how well users can trust the predictions of the underlying machine learning algorithms that are often applied and recognised as a `black-box'. Without understanding the rationale of the black-box machinery, there will be a lack of trust in the predictions, a reluctance to use the predictions, and in the worse case, consequences of an incorrect decision based on the prediction. In this paper, we emphasise the importance of interpreting the predictive models in addition to the evaluation using conventional metrics, such as accuracy, in the context of predictive process monitoring. We review existing studies on business process monitoring benchmarks for predicting process outcomes and remaining time. We derive explanations that present the behaviour of the entire predictive model as well as explanations describing a particular prediction. These explanations are used to reveal data leakages, assess the interpretability of features used by the model, and the degree of the use of process knowledge in the existing benchmark models. Findings from this exploratory study motivate the need to incorporate interpretability in predictive process analytics.
Zero-Shot Paraphrase Generation with Multilingual Language Models
Nov 09, 2019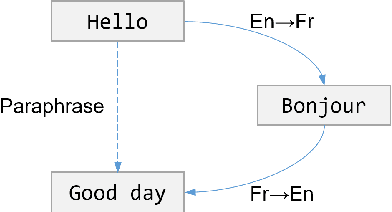
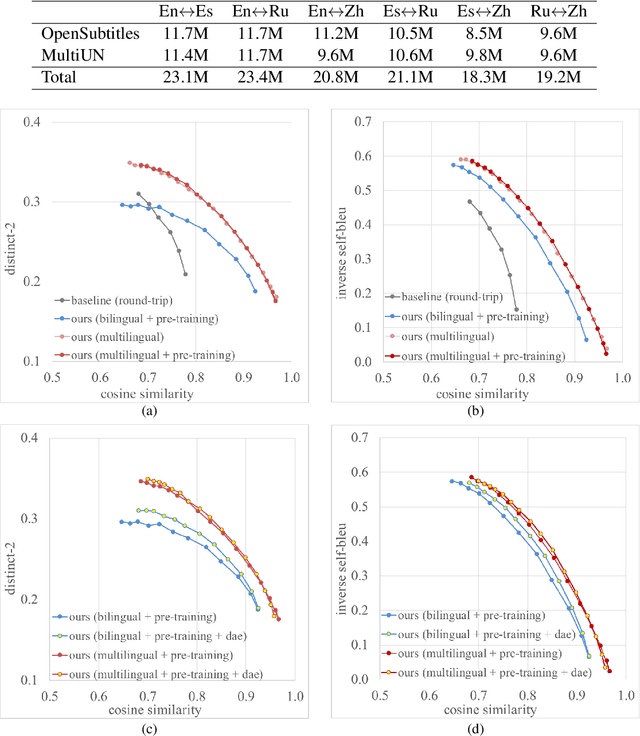
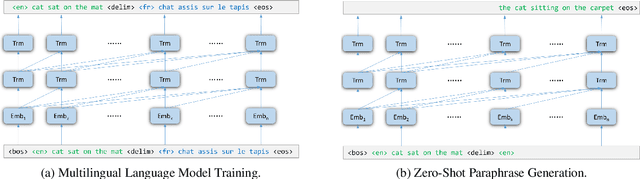
Leveraging multilingual parallel texts to automatically generate paraphrases has drawn much attention as size of high-quality paraphrase corpus is limited. Round-trip translation, also known as the pivoting method, is a typical approach to this end. However, we notice that the pivoting process involves multiple machine translation models and is likely to incur semantic drift during the two-step translations. In this paper, inspired by the Transformer-based language models, we propose a simple and unified paraphrasing model, which is purely trained on multilingual parallel data and can conduct zero-shot paraphrase generation in one step. Compared with the pivoting approach, paraphrases generated by our model is more semantically similar to the input sentence. Moreover, since our model shares the same architecture as GPT (Radford et al., 2018), we are able to pre-train the model on large-scale unparallel corpus, which further improves the fluency of the output sentences. In addition, we introduce the mechanism of denoising auto-encoder (DAE) to improve diversity and robustness of the model. Experimental results show that our model surpasses the pivoting method in terms of relevance, diversity, fluency and efficiency.
NEZHA: Neural Contextualized Representation for Chinese Language Understanding
Sep 05, 2019
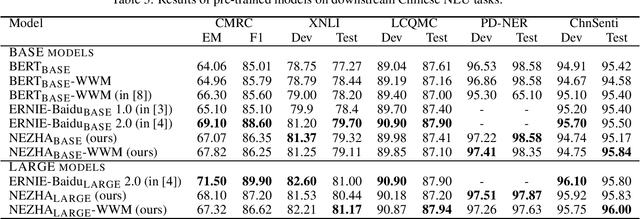
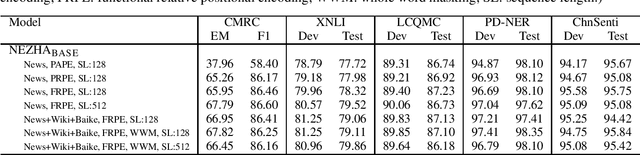
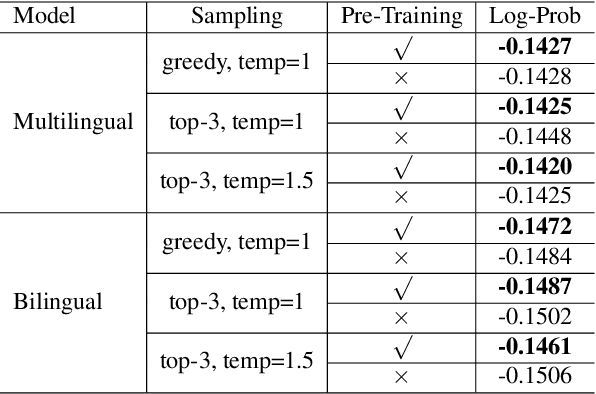
The pre-trained language models have achieved great successes in various natural language understanding (NLU) tasks due to its capacity to capture the deep contextualized information in text by pre-training on large-scale corpora. In this technical report, we present our practice of pre-training language models named NEZHA (NEural contextualiZed representation for CHinese lAnguage understanding) on Chinese corpora and finetuning for the Chinese NLU tasks. The current version of NEZHA is based on BERT with a collection of proven improvements, which include Functional Relative Positional Encoding as an effective positional encoding scheme, Whole Word Masking strategy, Mixed Precision Training and the LAMB Optimizer in training the models. The experimental results show that NEZHA achieves the state-of-the-art performances when finetuned on several representative Chinese tasks, including named entity recognition (People's Daily NER), sentence matching (LCQMC), Chinese sentiment classification (ChnSenti) and natural language inference (XNLI).
GPT-based Generation for Classical Chinese Poetry
Jul 12, 2019
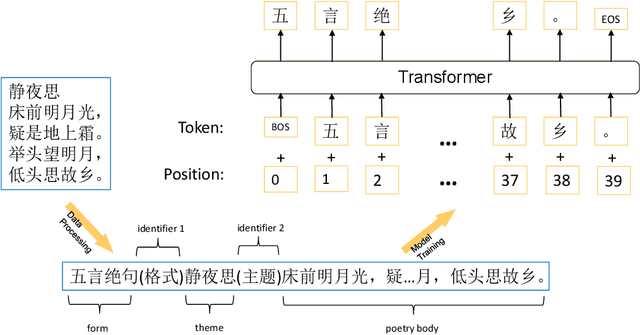

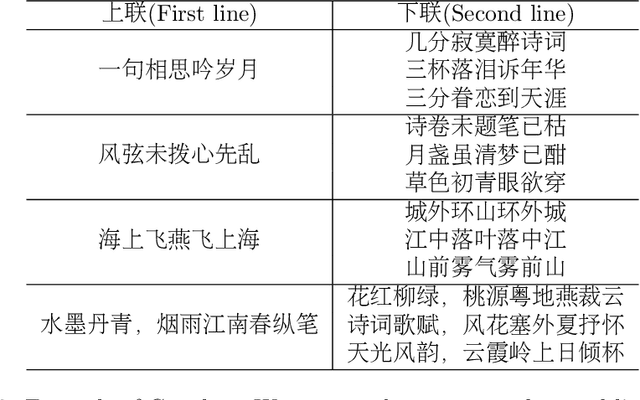
We present a simple yet effective method for generating high quality classical Chinese poetry with Generative Pre-trained Language Model (GPT). The method adopts a simple GPT model, without using any human crafted rules or features, or designing any additional neural components. While the proposed model learns to generate various forms of classical Chinese poems, including Jueju, L\"{u}shi, various Cipai and Couples, the generated poems are of very high quality. We also propose and implement a method to fine-tune the model to generate acrostic poetry. To the best of our knowledge, this is the first to employ GPT in developing a poetry generation system. We will release an online demonstration system in the near future to show the generation capability of the proposed method for classical Chinese poetry.
QuaSE: Sequence Editing under Quantifiable Guidance
Aug 31, 2018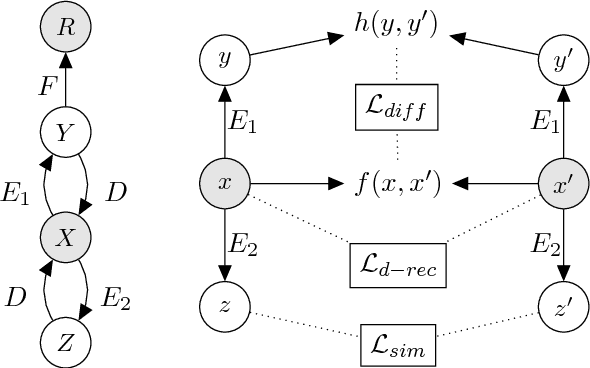
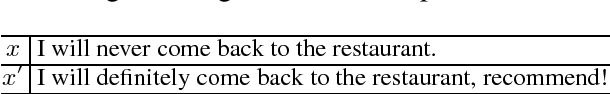


We propose the task of Quantifiable Sequence Editing (QuaSE): editing an input sequence to generate an output sequence that satisfies a given numerical outcome value measuring a certain property of the sequence, with the requirement of keeping the main content of the input sequence. For example, an input sequence could be a word sequence, such as review sentence and advertisement text. For a review sentence, the outcome could be the review rating; for an advertisement, the outcome could be the click-through rate. The major challenge in performing QuaSE is how to perceive the outcome-related wordings, and only edit them to change the outcome. In this paper, the proposed framework contains two latent factors, namely, outcome factor and content factor, disentangled from the input sentence to allow convenient editing to change the outcome and keep the content. Our framework explores the pseudo-parallel sentences by modeling their content similarity and outcome differences to enable a better disentanglement of the latent factors, which allows generating an output to better satisfy the desired outcome and keep the content. The dual reconstruction structure further enhances the capability of generating expected output by exploiting the couplings of latent factors of pseudo-parallel sentences. For evaluation, we prepared a dataset of Yelp review sentences with the ratings as outcome. Extensive experimental results are reported and discussed to elaborate the peculiarities of our framework.
Abstractive Multi-Document Summarization via Phrase Selection and Merging
Jun 05, 2015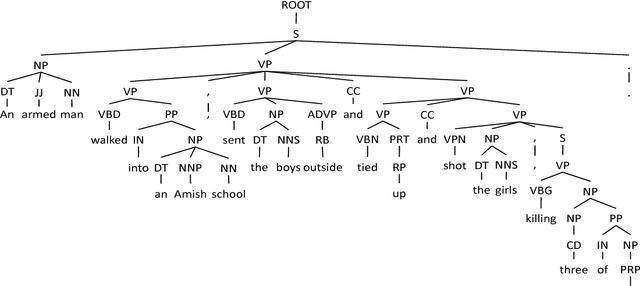

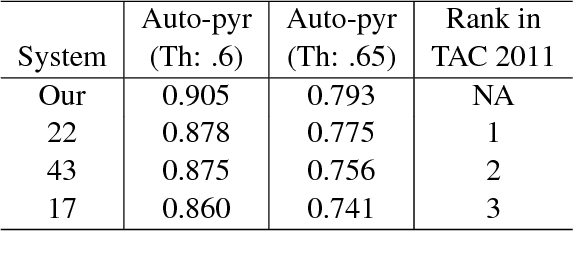
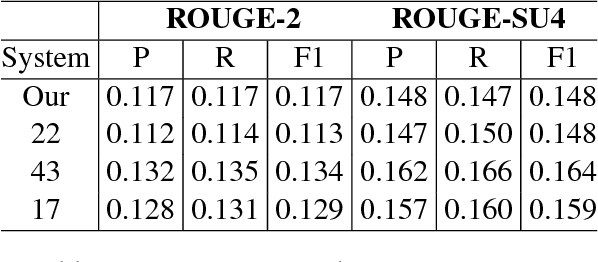
We propose an abstraction-based multi-document summarization framework that can construct new sentences by exploring more fine-grained syntactic units than sentences, namely, noun/verb phrases. Different from existing abstraction-based approaches, our method first constructs a pool of concepts and facts represented by phrases from the input documents. Then new sentences are generated by selecting and merging informative phrases to maximize the salience of phrases and meanwhile satisfy the sentence construction constraints. We employ integer linear optimization for conducting phrase selection and merging simultaneously in order to achieve the global optimal solution for a summary. Experimental results on the benchmark data set TAC 2011 show that our framework outperforms the state-of-the-art models under automated pyramid evaluation metric, and achieves reasonably well results on manual linguistic quality evaluation.
Reader-Aware Multi-Document Summarization via Sparse Coding
Apr 28, 2015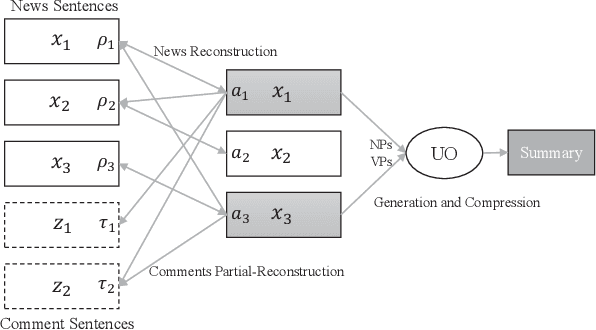
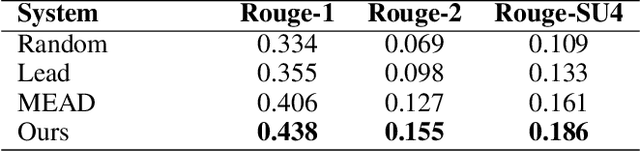
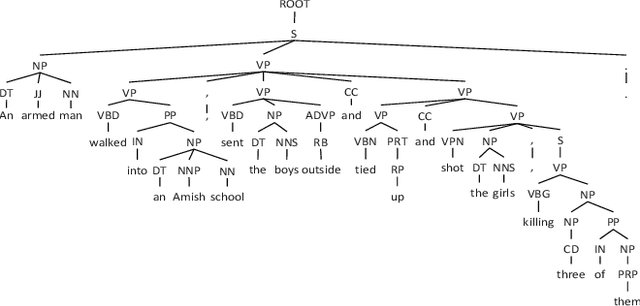
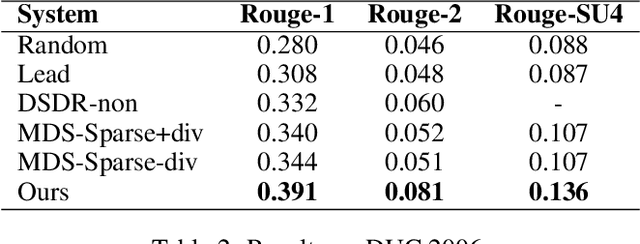
We propose a new MDS paradigm called reader-aware multi-document summarization (RA-MDS). Specifically, a set of reader comments associated with the news reports are also collected. The generated summaries from the reports for the event should be salient according to not only the reports but also the reader comments. To tackle this RA-MDS problem, we propose a sparse-coding-based method that is able to calculate the salience of the text units by jointly considering news reports and reader comments. Another reader-aware characteristic of our framework is to improve linguistic quality via entity rewriting. The rewriting consideration is jointly assessed together with other summarization requirements under a unified optimization model. To support the generation of compressive summaries via optimization, we explore a finer syntactic unit, namely, noun/verb phrase. In this work, we also generate a data set for conducting RA-MDS. Extensive experiments on this data set and some classical data sets demonstrate the effectiveness of our proposed approach.