 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Code Graphs and Large Language Models for Better Code Understanding
Dec 08, 2025



Large Language Models (LLMs) have demonstrated remarkable performance in code intelligence tasks such as code generation, summarization, and translation. However, their reliance on linearized token sequences limits their ability to understand the structural semantics of programs. While prior studies have explored graphaugmented prompting and structure-aware pretraining, they either suffer from prompt length constraints or require task-specific architectural changes that are incompatible with large-scale instructionfollowing LLMs. To address these limitations, this paper proposes CGBridge, a novel plug-and-play method that enhances LLMs with Code Graph information through an external, trainable Bridge module. CGBridge first pre-trains a code graph encoder via selfsupervised learning on a large-scale dataset of 270K code graphs to learn structural code semantics. It then trains an external module to bridge the modality gap among code, graph, and text by aligning their semantics through cross-modal attention mechanisms. Finally, the bridge module generates structure-informed prompts, which are injected into a frozen LLM, and is fine-tuned for downstream code intelligence tasks. Experiments show that CGBridge achieves notable improvements over both the original model and the graphaugmented prompting method. Specifically, it yields a 16.19% and 9.12% relative gain in LLM-as-a-Judge on code summarization, and a 9.84% and 38.87% relative gain in Execution Accuracy on code translation. Moreover, CGBridge achieves over 4x faster inference than LoRA-tuned models, demonstrating both effectiveness and efficiency in structure-aware code understanding.
Dual Clustering Co-teaching with Consistent Sample Mining for Unsupervised Person Re-Identification
Oct 07, 2022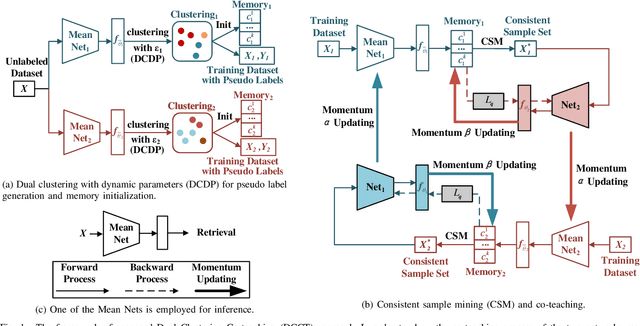
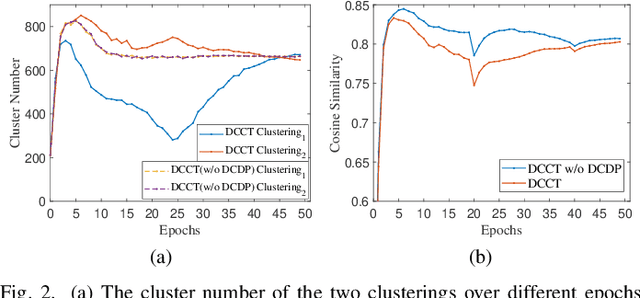
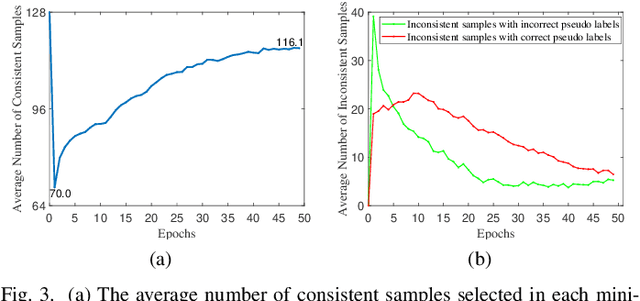

In unsupervised person Re-ID, peer-teaching strategy leveraging two networks to facilitate training has been proven to be an effective method to deal with the pseudo label noise. However, training two networks with a set of noisy pseudo labels reduces the complementarity of the two networks and results in label noise accumulation. To handle this issue, this paper proposes a novel Dual Clustering Co-teaching (DCCT) approach. DCCT mainly exploits the features extracted by two networks to generate two sets of pseudo labels separately by clustering with different parameters. Each network is trained with the pseudo labels generated by its peer network, which can increase the complementarity of the two networks to reduce the impact of noises. Furthermore, we propose dual clustering with dynamic parameters (DCDP) to make the network adaptive and robust to dynamically changing clustering parameters. Moreover, Consistent Sample Mining (CSM) is proposed to find the samples with unchanged pseudo labels during training for potential noisy sample removal. Extensive experiments demonstrate the effectiveness of the proposed method, which outperforms the state-of-the-art unsupervised person Re-ID methods by a considerable margin and surpasses most methods utilizing camera information.