 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Visual-linguistic Model via Knowledge Distillation
Apr 05, 2021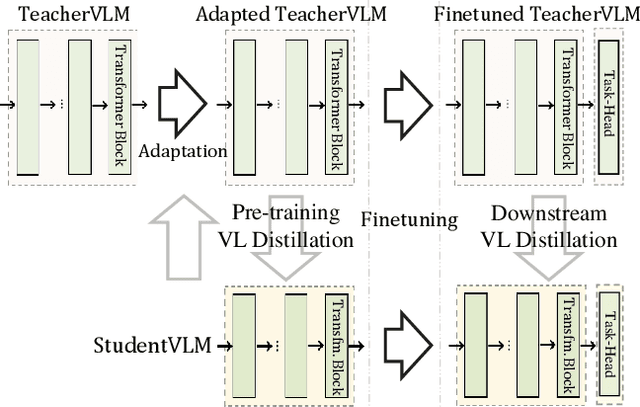
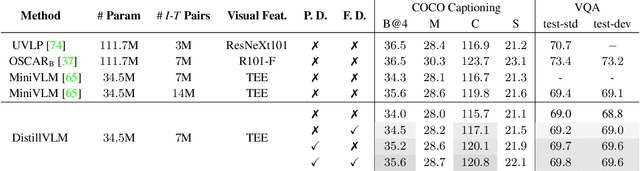
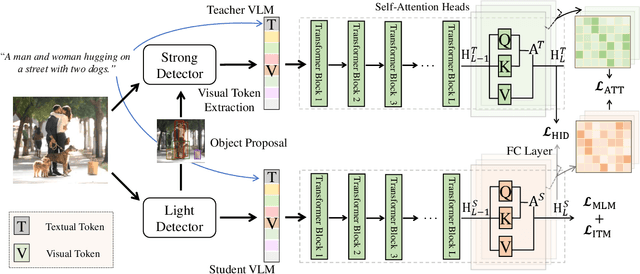
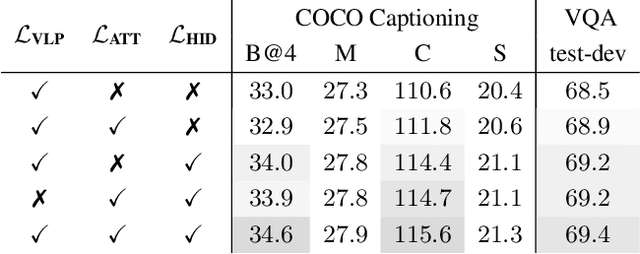
Despite exciting progress in pre-training for visual-linguistic (VL) representations, very few aspire to a small VL model. In this paper, we study knowledge distillation (KD) to effectively compress a transformer-based large VL model into a small VL model. The major challenge arises from the inconsistent regional visual tokens extracted from different detectors of Teacher and Student, resulting in the misalignment of hidden representations and attention distributions. To address the problem, we retrain and adapt the Teacher by using the same region proposals from Student's detector while the features are from Teacher's own object detector. With aligned network inputs, the adapted Teacher is capable of transferring the knowledge through the intermediate representations. Specifically, we use the mean square error loss to mimic the attention distribution inside the transformer block and present a token-wise noise contrastive loss to align the hidden state by contrasting with negative representations stored in a sample queue. To this end, we show that our proposed distillation significantly improves the performance of small VL models on image captioning and visual question answering tasks. It reaches 120.8 in CIDEr score on COCO captioning, an improvement of 5.1 over its non-distilled counterpart; and an accuracy of 69.8 on VQA 2.0, a 0.8 gain from the baseline. Our extensive experiments and ablations confirm the effectiveness of VL distillation in both pre-training and fine-tuning stages.
CAROM -- Vehicle Localization and Traffic Scene Reconstruction from Monocular Cameras on Road Infrastructures
Apr 02, 2021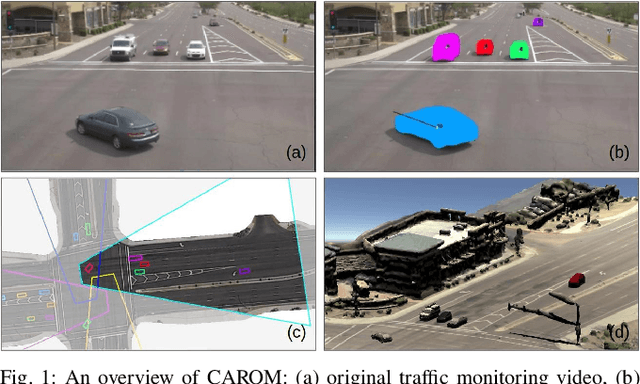
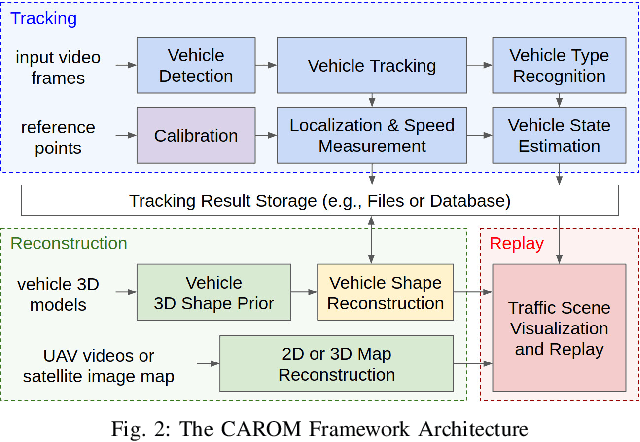
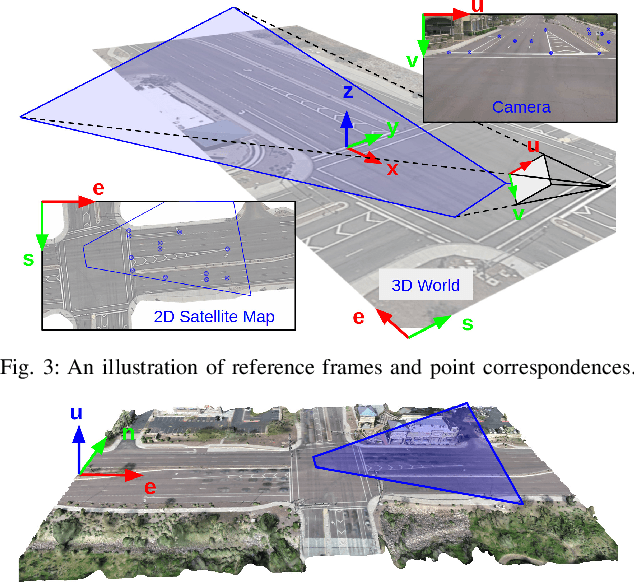
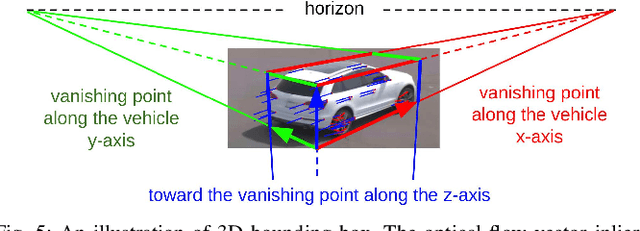
Traffic monitoring cameras are powerful tools for traffic management and essential components of intelligent road infrastructure systems. In this paper, we present a vehicle localization and traffic scene reconstruction framework using these cameras, dubbed as CAROM, i.e., "CARs On the Map". CAROM processes traffic monitoring videos and converts them to anonymous data structures of vehicle type, 3D shape, position, and velocity for traffic scene reconstruction and replay. Through collaborating with a local department of transportation in the United States, we constructed a benchmarking dataset containing GPS data, roadside camera videos, and drone videos to validate the vehicle tracking results. On average, the localization error is approximately 0.8 m and 1.7 m within the range of 50 m and 120 m from the cameras, respectively.
Hierarchical and Partially Observable Goal-driven Policy Learning with Goals Relational Graph
Mar 30, 2021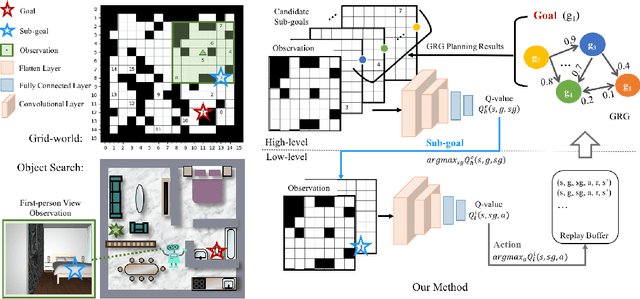
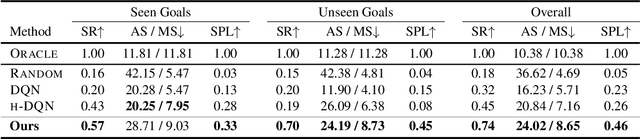
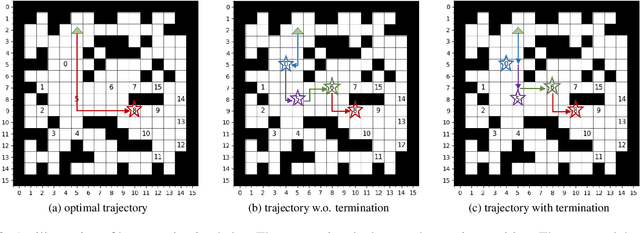

We present a novel two-layer hierarchical reinforcement learning approach equipped with a Goals Relational Graph (GRG) for tackling the partially observable goal-driven task, such as goal-driven visual navigation. Our GRG captures the underlying relations of all goals in the goal space through a Dirichlet-categorical process that facilitates: 1) the high-level network raising a sub-goal towards achieving a designated final goal; 2) the low-level network towards an optimal policy; and 3) the overall system generalizing unseen environments and goals. We evaluate our approach with two settings of partially observable goal-driven tasks -- a grid-world domain and a robotic object search task. Our experimental results show that our approach exhibits superior generalization performance on both unseen environments and new goals.
SEED: Self-supervised Distillation For Visual Representation
Jan 12, 2021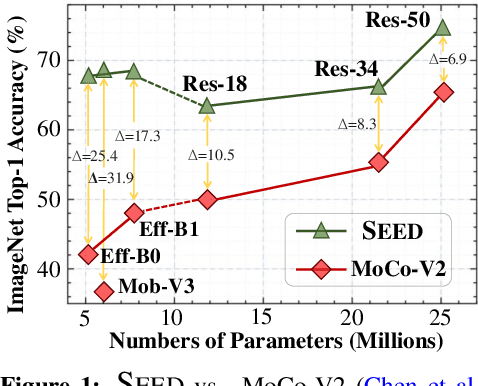
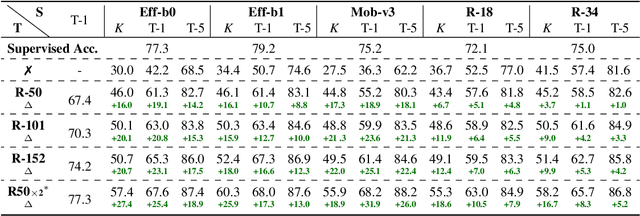
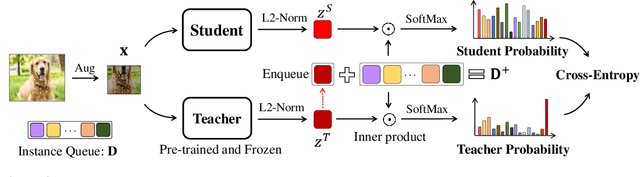

This paper is concerned with self-supervised learning for small models. The problem is motivated by our empirical studies that while the widely used contrastive self-supervised learning method has shown great progress on large model training, it does not work well for small models. To address this problem, we propose a new learning paradigm, named SElf-SupErvised Distillation (SEED), where we leverage a larger network (as Teacher) to transfer its representational knowledge into a smaller architecture (as Student) in a self-supervised fashion. Instead of directly learning from unlabeled data, we train a student encoder to mimic the similarity score distribution inferred by a teacher over a set of instances. We show that SEED dramatically boosts the performance of small networks on downstream tasks. Compared with self-supervised baselines, SEED improves the top-1 accuracy from 42.2% to 67.6% on EfficientNet-B0 and from 36.3% to 68.2% on MobileNet-v3-Large on the ImageNet-1k dataset.
Self-Supervised VQA: Answering Visual Questions using Images and Captions
Dec 04, 2020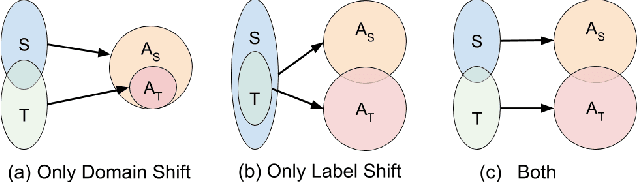
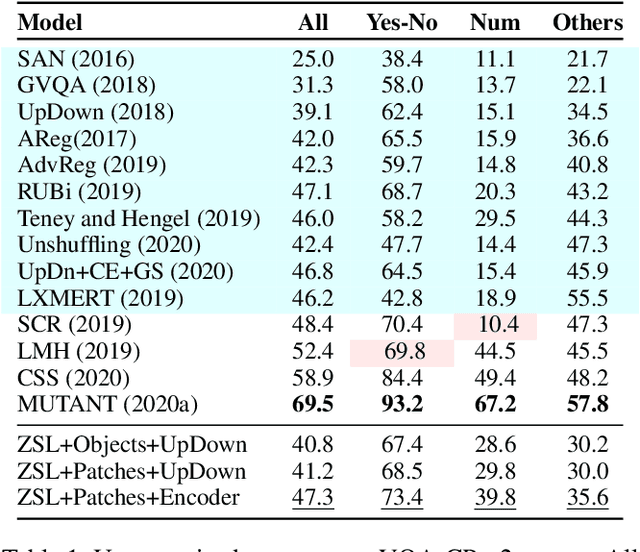


Methodologies for training VQA models assume the availability of datasets with human-annotated Image-Question-Answer(I-Q-A) triplets for training. This has led to a heavy reliance and overfitting on datasets and a lack of generalization to new types of questions and scenes. Moreover, these datasets exhibit annotator subjectivity, biases, and errors, along with linguistic priors, which percolate into VQA models trained on such samples. We study whether models can be trained without any human-annotated Q-A pairs, but only with images and associated text captions which are descriptive and less subjective. We present a method to train models with procedurally generated Q-A pairs from captions using techniques, such as templates and annotation frameworks like QASRL. As most VQA models rely on dense and costly object annotations extracted from object detectors, we propose spatial-pyramid image patches as a simple but effective alternative to object bounding boxes, and demonstrate that our method uses fewer human annotations. We benchmark on VQA-v2, GQA, and on VQA-CP which contains a softer version of label shift. Our methods surpass prior supervised methods on VQA-CP and are competitive with methods without object features in fully supervised setting.
Attribute-Guided Adversarial Training for Robustness to Natural Perturbations
Dec 03, 2020
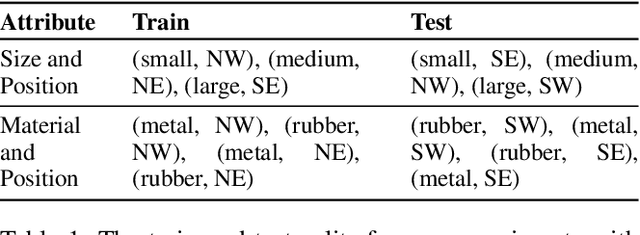

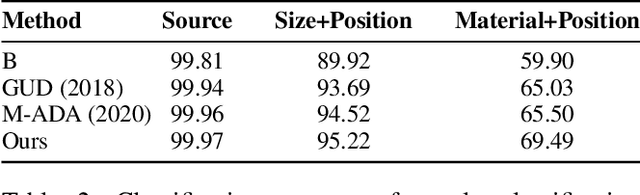
While existing work in robust deep learning has focused on small pixel-level $\ell_p$ norm-based perturbations, this may not account for perturbations encountered in several real world settings. In many such cases although test data might not be available, broad specifications about the types of perturbations (such as an unknown degree of rotation) may be known. We consider a setup where robustness is expected over an unseen test domain that is not i.i.d. but deviates from the training domain. While this deviation may not be exactly known, its broad characterization is specified a priori, in terms of attributes. We propose an adversarial training approach which learns to generate new samples so as to maximize exposure of the classifier to the attributes-space, without having access to the data from the test domain. Our adversarial training solves a min-max optimization problem, with the inner maximization generating adversarial perturbations, and the outer minimization finding model parameters by optimizing the loss on adversarial perturbations generated from the inner maximization. We demonstrate the applicability of our approach on three types of naturally occurring perturbations -- object-related shifts, geometric transformations, and common image corruptions. Our approach enables deep neural networks to be robust against a wide range of naturally occurring perturbations. We demonstrate the usefulness of the proposed approach by showing the robustness gains of deep neural networks trained using our adversarial training on MNIST, CIFAR-10, and a new variant of the CLEVR dataset.
Decentralized Attribution of Generative Models
Oct 27, 2020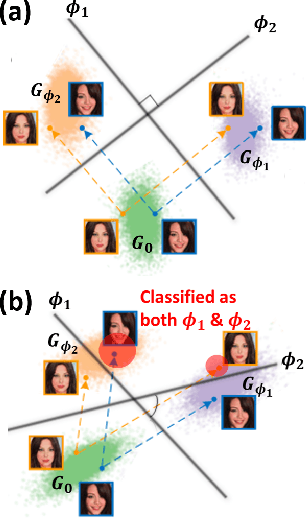
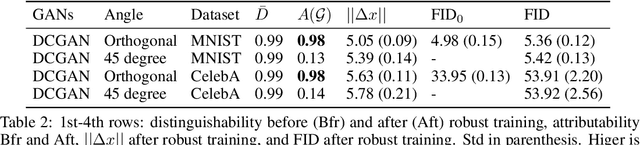
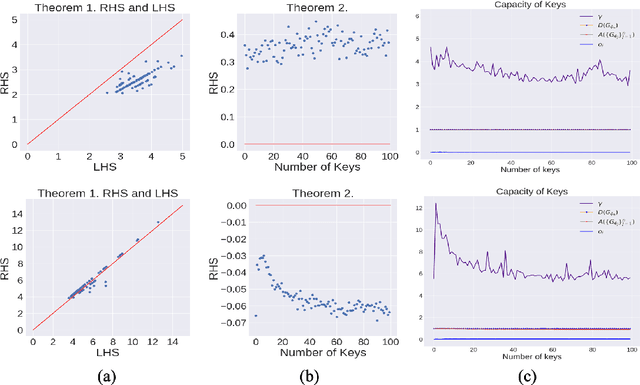
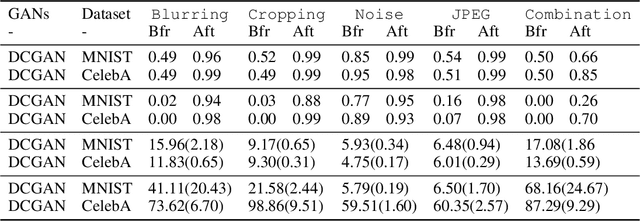
There have been growing concerns regarding the fabrication of contents through generative models. This paper investigates the feasibility of decentralized attribution of such models. Given a set of generative models learned from the same dataset, attributability is achieved when a public verification service exists to correctly identify the source models for generated content. Attribution allows tracing of machine-generated content back to its source model, thus facilitating IP-protection and content regulation. Existing attribution methods are non-scalable with respect to the number of models and lack theoretical bounds on attributability. This paper studies decentralized attribution, where provable attributability can be achieved by only requiring each model to be distinguishable from the authentic data. Our major contributions are the derivation of the sufficient conditions for decentralized attribution and the design of keys following these conditions. Specifically, we show that decentralized attribution can be achieved when keys are (1) orthogonal to each other, and (2) belonging to a subspace determined by the data distribution. This result is validated on MNIST and CelebA. Lastly, we use these datasets to examine the trade-off between generation quality and robust attributability against adversarial post-processes.
Efficient Robotic Object Search via HIEM: Hierarchical Policy Learning with Intrinsic-Extrinsic Modeling
Oct 16, 2020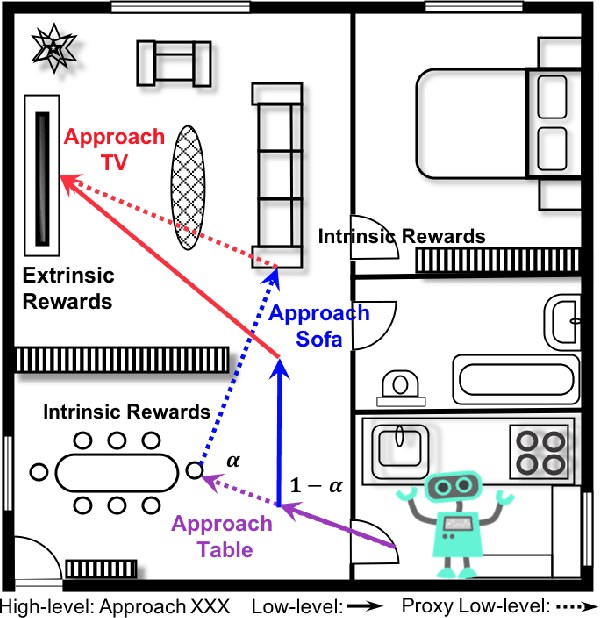
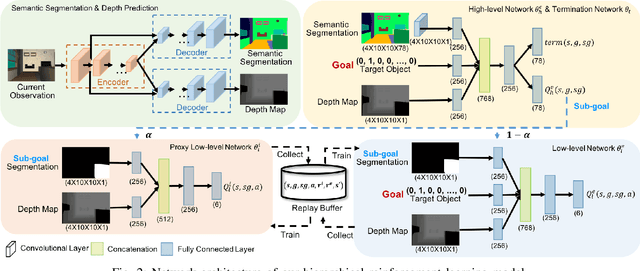
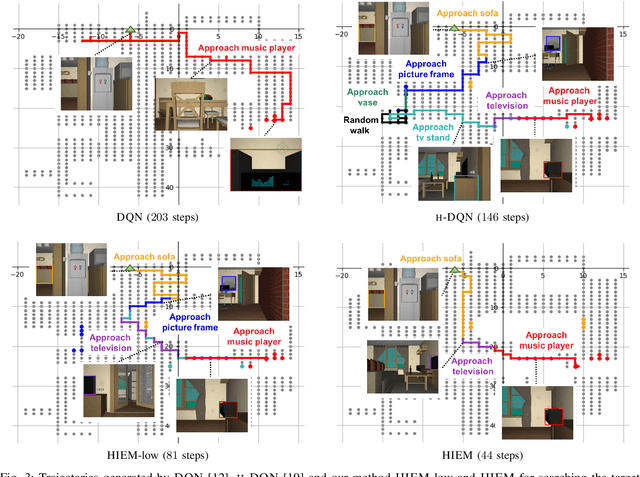
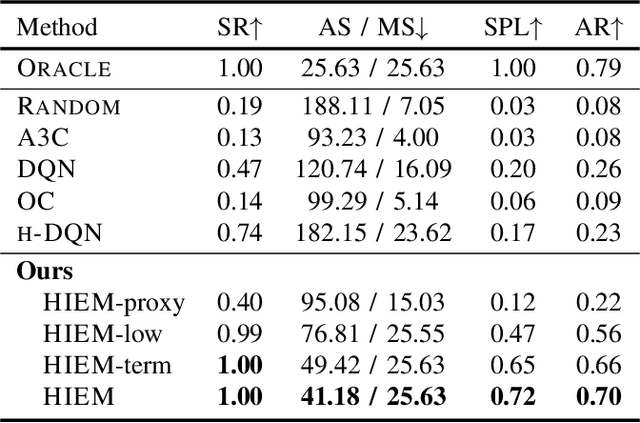
Despite the significant success at enabling robots with autonomous behaviors makes deep reinforcement learning a promising approach for robotic object search task, the deep reinforcement learning approach severely suffers from the nature sparse reward setting of the task. To tackle this challenge, we present a novel policy learning paradigm for the object search task, based on hierarchical and interpretable modeling with an intrinsic-extrinsic reward setting. More specifically, we explore the environment efficiently through a proxy low-level policy which is driven by the intrinsic rewarding sub-goals. We further learn our hierarchical policy from the efficient exploration experience where we optimize both of our high-level and low-level policies towards the extrinsic rewarding goal to perform the object search task well. Experiments conducted on the House3D environment validate and show that the robot, trained with our model, can perform the object search task in a more optimal and interpretable way.
MUTANT: A Training Paradigm for Out-of-Distribution Generalization in Visual Question Answering
Sep 18, 2020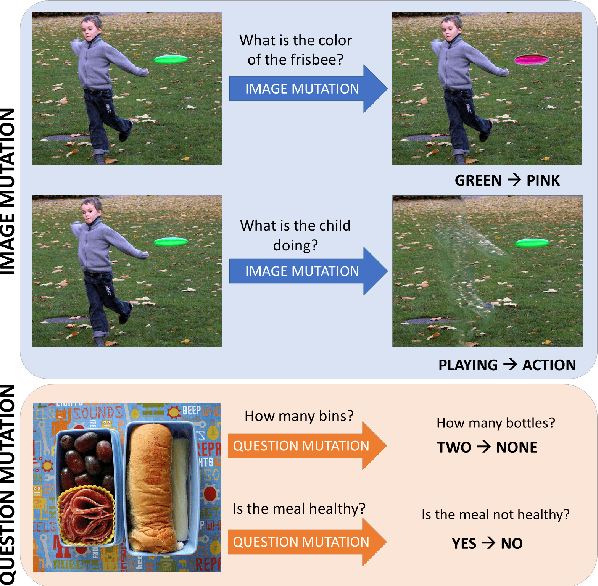
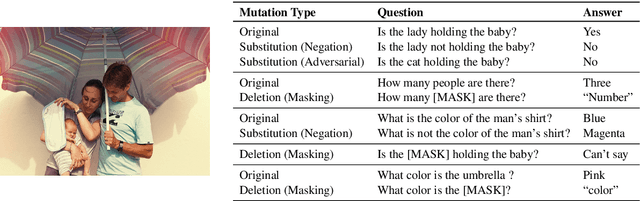
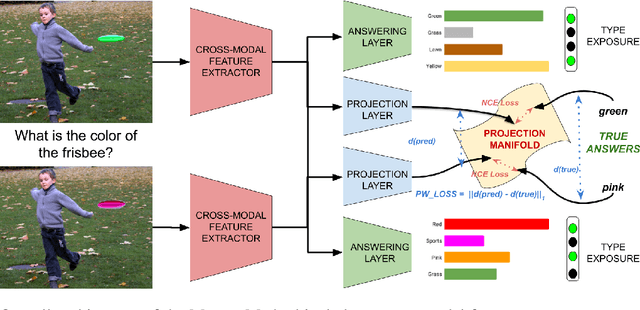

While progress has been made on the visual question answering leaderboards, models often utilize spurious correlations and priors in datasets under the i.i.d. setting. As such, evaluation on out-of-distribution (OOD) test samples has emerged as a proxy for generalization. In this paper, we present \textit{MUTANT}, a training paradigm that exposes the model to perceptually similar, yet semantically distinct \textit{mutations} of the input, to improve OOD generalization, such as the VQA-CP challenge. Under this paradigm, models utilize a consistency-constrained training objective to understand the effect of semantic changes in input (question-image pair) on the output (answer). Unlike existing methods on VQA-CP, \textit{MUTANT} does not rely on the knowledge about the nature of train and test answer distributions. \textit{MUTANT} establishes a new state-of-the-art accuracy on VQA-CP with a $10.57\%$ improvement. Our work opens up avenues for the use of semantic input mutations for OOD generalization in question answering.
Low to High Dimensional Modality Hallucination using Aggregated Fields of View
Jul 13, 2020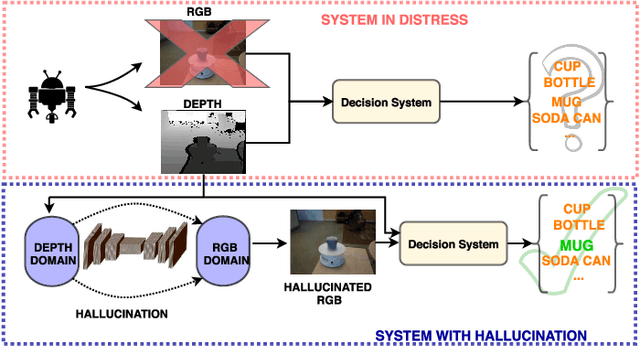



Real-world robotics systems deal with data from a multitude of modalities, especially for tasks such as navigation and recognition. The performance of those systems can drastically degrade when one or more modalities become inaccessible, due to factors such as sensors' malfunctions or adverse environments. Here, we argue modality hallucination as one effective way to ensure consistent modality availability and thereby reduce unfavorable consequences. While hallucinating data from a modality with richer information, e.g., RGB to depth, has been researched extensively, we investigate the more challenging low-to-high modality hallucination with interesting use cases in robotics and autonomous systems. We present a novel hallucination architecture that aggregates information from multiple fields of view of the local neighborhood to recover the lost information from the extant modality. The process is implemented by capturing a non-linear mapping between the data modalities and the learned mapping is used to aid the extant modality to mitigate the risk posed to the system in the adverse scenarios which involve modality loss. We also conduct extensive classification and segmentation experiments on UWRGBD and NYUD datasets and demonstrate that hallucination allays the negative effects of the modality loss. Implementation and models: https://github.com/kausic94/Hallucination