 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Adapters Matter: Selective Adapter Freezing for Memory-Efficient Fine-Tuning of Language Models
Nov 26, 2024



Transformer-based large-scale pre-trained models achieve great success, and fine-tuning, which tunes a pre-trained model on a task-specific dataset, is the standard practice to utilize these models for downstream tasks. Recent work has developed adapter-tuning, but these approaches either still require a relatively high resource usage. Through our investigation, we show that each adapter in adapter-tuning does not have the same impact on task performance and resource usage. Based on our findings, we propose SAFE, which gradually freezes less-important adapters that do not contribute to adaptation during the early training steps. In our experiments, SAFE reduces memory usage, computation amount, and training time by 42.85\%, 34.59\%, and 11.82\%, respectively, while achieving comparable or better performance compared to the baseline. We also demonstrate that SAFE induces regularization effect, thereby smoothing the loss landscape.
TripletCLIP: Improving Compositional Reasoning of CLIP via Synthetic Vision-Language Negatives
Nov 04, 2024



Contrastive Language-Image Pretraining (CLIP) models maximize the mutual information between text and visual modalities to learn representations. This makes the nature of the training data a significant factor in the efficacy of CLIP for downstream tasks. However, the lack of compositional diversity in contemporary image-text datasets limits the compositional reasoning ability of CLIP. We show that generating ``hard'' negative captions via in-context learning and synthesizing corresponding negative images with text-to-image generators offers a solution. We introduce a novel contrastive pre-training strategy that leverages these hard negative captions and images in an alternating fashion to train CLIP. We demonstrate that our method, named TripletCLIP, when applied to existing datasets such as CC3M and CC12M, enhances the compositional capabilities of CLIP, resulting in an absolute improvement of over 9% on the SugarCrepe benchmark on an equal computational budget, as well as improvements in zero-shot image classification and image retrieval. Our code, models, and data are available at: https://tripletclip.github.io
Deep Geometric Moments Promote Shape Consistency in Text-to-3D Generation
Aug 12, 2024



To address the data scarcity associated with 3D assets, 2D-lifting techniques such as Score Distillation Sampling (SDS) have become a widely adopted practice in text-to-3D generation pipelines. However, the diffusion models used in these techniques are prone to viewpoint bias and thus lead to geometric inconsistencies such as the Janus problem. To counter this, we introduce MT3D, a text-to-3D generative model that leverages a high-fidelity 3D object to overcome viewpoint bias and explicitly infuse geometric understanding into the generation pipeline. Firstly, we employ depth maps derived from a high-quality 3D model as control signals to guarantee that the generated 2D images preserve the fundamental shape and structure, thereby reducing the inherent viewpoint bias. Next, we utilize deep geometric moments to ensure geometric consistency in the 3D representation explicitly. By incorporating geometric details from a 3D asset, MT3D enables the creation of diverse and geometrically consistent objects, thereby improving the quality and usability of our 3D representations.
R.A.C.E.: Robust Adversarial Concept Erasure for Secure Text-to-Image Diffusion Model
May 25, 2024



In the evolving landscape of text-to-image (T2I) diffusion models, the remarkable capability to generate high-quality images from textual descriptions faces challenges with the potential misuse of reproducing sensitive content. To address this critical issue, we introduce Robust Adversarial Concept Erase (RACE), a novel approach designed to mitigate these risks by enhancing the robustness of concept erasure method for T2I models. RACE utilizes a sophisticated adversarial training framework to identify and mitigate adversarial text embeddings, significantly reducing the Attack Success Rate (ASR). Impressively, RACE achieves a 30 percentage point reduction in ASR for the ``nudity'' concept against the leading white-box attack method. Our extensive evaluations demonstrate RACE's effectiveness in defending against both white-box and black-box attacks, marking a significant advancement in protecting T2I diffusion models from generating inappropriate or misleading imagery. This work underlines the essential need for proactive defense measures in adapting to the rapidly advancing field of adversarial challenges.
Learning Decomposable and Debiased Representations via Attribute-Centric Information Bottlenecks
Mar 21, 2024



Biased attributes, spuriously correlated with target labels in a dataset, can problematically lead to neural networks that learn improper shortcuts for classifications and limit their capabilities for out-of-distribution (OOD) generalization. Although many debiasing approaches have been proposed to ensure correct predictions from biased datasets, few studies have considered learning latent embedding consisting of intrinsic and biased attributes that contribute to improved performance and explain how the model pays attention to attributes. In this paper, we propose a novel debiasing framework, Debiasing Global Workspace, introducing attention-based information bottlenecks for learning compositional representations of attributes without defining specific bias types. Based on our observation that learning shape-centric representation helps robust performance on OOD datasets, we adopt those abilities to learn robust and generalizable representations of decomposable latent embeddings corresponding to intrinsic and biasing attributes. We conduct comprehensive evaluations on biased datasets, along with both quantitative and qualitative analyses, to showcase our approach's efficacy in attribute-centric representation learning and its ability to differentiate between intrinsic and bias-related features.
ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image Generations
Dec 07, 2023



Text-to-image (T2I) diffusion models, notably the unCLIP models (e.g., DALL-E-2), achieve state-of-the-art (SOTA) performance on various compositional T2I benchmarks, at the cost of significant computational resources. The unCLIP stack comprises T2I prior and diffusion image decoder. The T2I prior model alone adds a billion parameters compared to the Latent Diffusion Models, which increases the computational and high-quality data requirements. We introduce ECLIPSE, a novel contrastive learning method that is both parameter and data-efficient. ECLIPSE leverages pre-trained vision-language models (e.g., CLIP) to distill the knowledge into the prior model. We demonstrate that the ECLIPSE trained prior, with only 3.3% of the parameters and trained on a mere 2.8% of the data, surpasses the baseline T2I priors with an average of 71.6% preference score under resource-limited setting. It also attains performance on par with SOTA big models, achieving an average of 63.36% preference score in terms of the ability to follow the text compositions. Extensive experiments on two unCLIP diffusion image decoders, Karlo and Kandinsky, affirm that ECLIPSE priors consistently deliver high performance while significantly reducing resource dependency.
WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models
Jun 07, 2023



The rapid advancement of generative models, facilitating the creation of hyper-realistic images from textual descriptions, has concurrently escalated critical societal concerns such as misinformation. Traditional fake detection mechanisms, although providing some mitigation, fall short in attributing responsibility for the malicious use of synthetic images. This paper introduces a novel approach to model fingerprinting that assigns responsibility for the generated images, thereby serving as a potential countermeasure to model misuse. Our method modifies generative models based on each user's unique digital fingerprint, imprinting a unique identifier onto the resultant content that can be traced back to the user. This approach, incorporating fine-tuning into Text-to-Image (T2I) tasks using the Stable Diffusion Model, demonstrates near-perfect attribution accuracy with a minimal impact on output quality. We rigorously scrutinize our method's secrecy under two distinct scenarios: one where a malicious user attempts to detect the fingerprint, and another where a user possesses a comprehensive understanding of our method. We also evaluate the robustness of our approach against various image post-processing manipulations typically executed by end-users. Through extensive evaluation of the Stable Diffusion models, our method presents a promising and novel avenue for accountable model distribution and responsible use.
Attributing Image Generative Models using Latent Fingerprints
Apr 17, 2023



Generative models have enabled the creation of contents that are indistinguishable from those taken from the nature. Open-source development of such models raised concerns about the risks in their misuse for malicious purposes. One potential risk mitigation strategy is to attribute generative models via fingerprinting. Current fingerprinting methods exhibit significant tradeoff between robust attribution accuracy and generation quality, and also lack designing principles to improve this tradeoff. This paper investigates the use of latent semantic dimensions as fingerprints, from where we can analyze the effects of design variables, including the choice of fingerprinting dimensions, strength, and capacity, on the accuracy-quality tradeoff. Compared with previous SOTA, our method requires minimum computation and is more applicable to large-scale models. We use StyleGAN2 and the latent diffusion model to demonstrate the efficacy of our method.
Attributable Watermarking of Speech Generative Models
Feb 17, 2022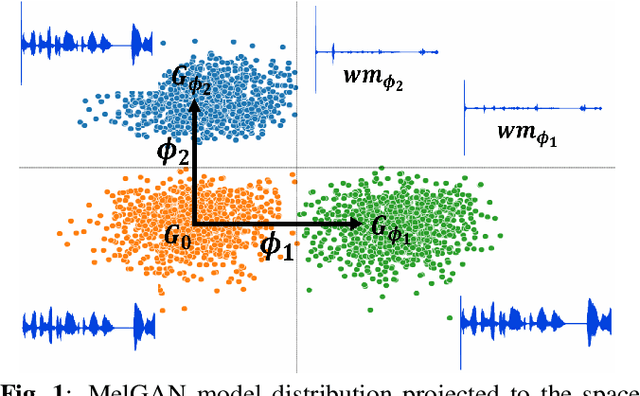
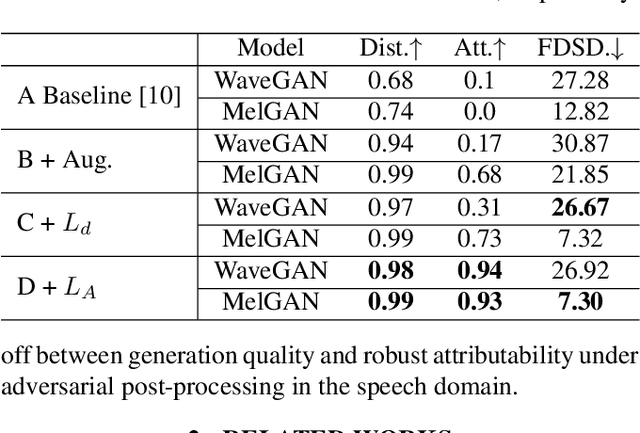
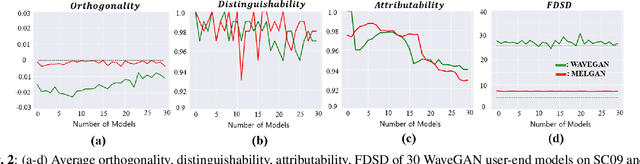
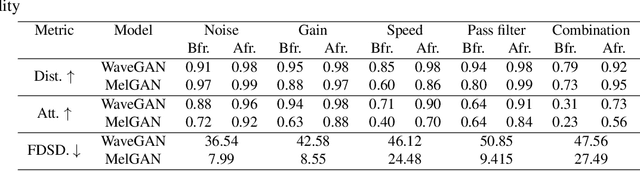
Generative models are now capable of synthesizing images, speeches, and videos that are hardly distinguishable from authentic contents. Such capabilities cause concerns such as malicious impersonation and IP theft. This paper investigates a solution for model attribution, i.e., the classification of synthetic contents by their source models via watermarks embedded in the contents. Building on past success of model attribution in the image domain, we discuss algorithmic improvements for generating user-end speech models that empirically achieve high attribution accuracy, while maintaining high generation quality. We show the trade off between attributability and generation quality under a variety of attacks on generated speech signals attempting to remove the watermarks, and the feasibility of learning robust watermarks against these attacks.
Decentralized Attribution of Generative Models
Oct 27, 2020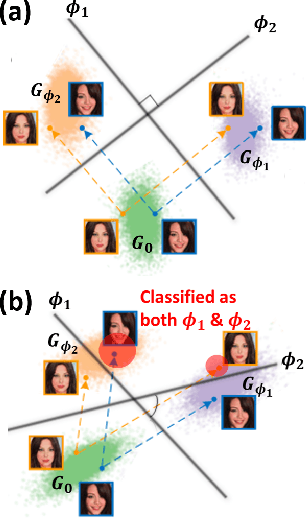
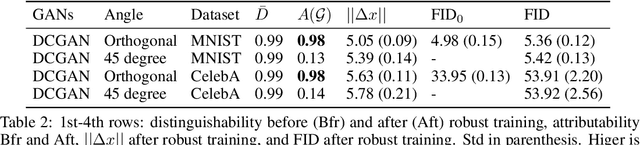
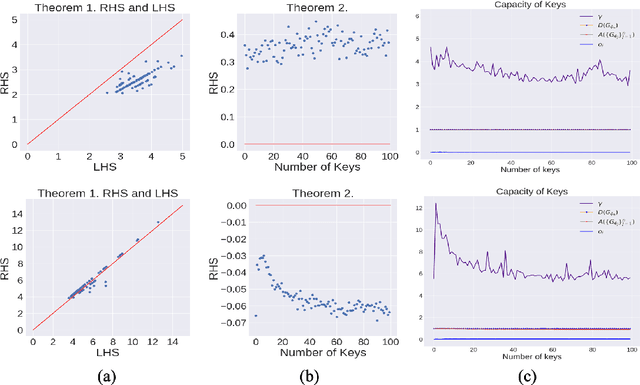
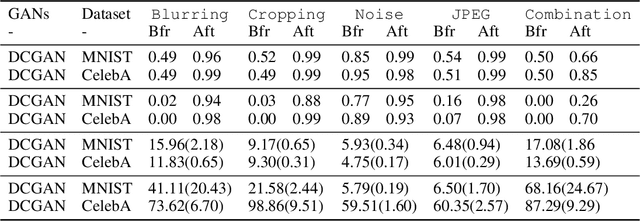
There have been growing concerns regarding the fabrication of contents through generative models. This paper investigates the feasibility of decentralized attribution of such models. Given a set of generative models learned from the same dataset, attributability is achieved when a public verification service exists to correctly identify the source models for generated content. Attribution allows tracing of machine-generated content back to its source model, thus facilitating IP-protection and content regulation. Existing attribution methods are non-scalable with respect to the number of models and lack theoretical bounds on attributability. This paper studies decentralized attribution, where provable attributability can be achieved by only requiring each model to be distinguishable from the authentic data. Our major contributions are the derivation of the sufficient conditions for decentralized attribution and the design of keys following these conditions. Specifically, we show that decentralized attribution can be achieved when keys are (1) orthogonal to each other, and (2) belonging to a subspace determined by the data distribution. This result is validated on MNIST and CelebA. Lastly, we use these datasets to examine the trade-off between generation quality and robust attributability against adversarial post-processes.