 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiBench: Benchmarking LLMs Capability on Hierarchical Structure Reasoning
Mar 02, 2025



Structure reasoning is a fundamental capability of large language models (LLMs), enabling them to reason about structured commonsense and answer multi-hop questions. However, existing benchmarks for structure reasoning mainly focus on horizontal and coordinate structures (\emph{e.g.} graphs), overlooking the hierarchical relationships within them. Hierarchical structure reasoning is crucial for human cognition, particularly in memory organization and problem-solving. It also plays a key role in various real-world tasks, such as information extraction and decision-making. To address this gap, we propose HiBench, the first framework spanning from initial structure generation to final proficiency assessment, designed to benchmark the hierarchical reasoning capabilities of LLMs systematically. HiBench encompasses six representative scenarios, covering both fundamental and practical aspects, and consists of 30 tasks with varying hierarchical complexity, totaling 39,519 queries. To evaluate LLMs comprehensively, we develop five capability dimensions that depict different facets of hierarchical structure understanding. Through extensive evaluation of 20 LLMs from 10 model families, we reveal key insights into their capabilities and limitations: 1) existing LLMs show proficiency in basic hierarchical reasoning tasks; 2) they still struggle with more complex structures and implicit hierarchical representations, especially in structural modification and textual reasoning. Based on these findings, we create a small yet well-designed instruction dataset, which enhances LLMs' performance on HiBench by an average of 88.84\% (Llama-3.1-8B) and 31.38\% (Qwen2.5-7B) across all tasks. The HiBench dataset and toolkit are available here, https://github.com/jzzzzh/HiBench, to encourage evaluation.
Can You Move These Over There? An LLM-based VR Mover for Supporting Object Manipulation
Feb 04, 2025



In our daily lives, we can naturally convey instructions for the spatial manipulation of objects using words and gestures. Transposing this form of interaction into virtual reality (VR) object manipulation can be beneficial. We propose VR Mover, an LLM-empowered solution that can understand and interpret the user's vocal instruction to support object manipulation. By simply pointing and speaking, the LLM can manipulate objects without structured input. Our user study demonstrates that VR Mover enhances user usability, overall experience and performance on multi-object manipulation, while also reducing workload and arm fatigue. Users prefer the proposed natural interface for broad movements and may complementarily switch to gizmos or virtual hands for finer adjustments. These findings are believed to contribute to design implications for future LLM-based object manipulation interfaces, highlighting the potential for more intuitive and efficient user interactions in VR environments.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
SimulTron: On-Device Simultaneous Speech to Speech Translation
Jun 04, 2024



Simultaneous speech-to-speech translation (S2ST) holds the promise of breaking down communication barriers and enabling fluid conversations across languages. However, achieving accurate, real-time translation through mobile devices remains a major challenge. We introduce SimulTron, a novel S2ST architecture designed to tackle this task. SimulTron is a lightweight direct S2ST model that uses the strengths of the Translatotron framework while incorporating key modifications for streaming operation, and an adjustable fixed delay. Our experiments show that SimulTron surpasses Translatotron 2 in offline evaluations. Furthermore, real-time evaluations reveal that SimulTron improves upon the performance achieved by Translatotron 1. Additionally, SimulTron achieves superior BLEU scores and latency compared to previous real-time S2ST method on the MuST-C dataset. Significantly, we have successfully deployed SimulTron on a Pixel 7 Pro device, show its potential for simultaneous S2ST on-device.
Large Scale Foundation Models for Intelligent Manufacturing Applications: A Survey
Dec 22, 2023Although the applications of artificial intelligence especially deep learning had greatly improved various aspects of intelligent manufacturing, they still face challenges for wide employment due to the poor generalization ability, difficulties to establish high-quality training datasets, and unsatisfactory performance of deep learning methods. The emergence of large scale foundational models(LSFMs) had triggered a wave in the field of artificial intelligence, shifting deep learning models from single-task, single-modal, limited data patterns to a paradigm encompassing diverse tasks, multimodal, and pre-training on massive datasets. Although LSFMs had demonstrated powerful generalization capabilities, automatic high-quality training dataset generation and superior performance across various domains, applications of LSFMs on intelligent manufacturing were still in their nascent stage. A systematic overview of this topic was lacking, especially regarding which challenges of deep learning can be addressed by LSFMs and how these challenges can be systematically tackled. To fill this gap, this paper systematically expounded current statue of LSFMs and their advantages in the context of intelligent manufacturing. and compared comprehensively with the challenges faced by current deep learning models in various intelligent manufacturing applications. We also outlined the roadmaps for utilizing LSFMs to address these challenges. Finally, case studies of applications of LSFMs in real-world intelligent manufacturing scenarios were presented to illustrate how LSFMs could help industries, improve their efficiency.
Speech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022



Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.
Textless Direct Speech-to-Speech Translation with Discrete Speech Representation
Oct 31, 2022



Research on speech-to-speech translation (S2ST) has progressed rapidly in recent years. Many end-to-end systems have been proposed and show advantages over conventional cascade systems, which are often composed of recognition, translation and synthesis sub-systems. However, most of the end-to-end systems still rely on intermediate textual supervision during training, which makes it infeasible to work for languages without written forms. In this work, we propose a novel model, Textless Translatotron, which is based on Translatotron 2, for training an end-to-end direct S2ST model without any textual supervision. Instead of jointly training with an auxiliary task predicting target phonemes as in Translatotron 2, the proposed model uses an auxiliary task predicting discrete speech representations which are obtained from learned or random speech quantizers. When a speech encoder pre-trained with unsupervised speech data is used for both models, the proposed model obtains translation quality nearly on-par with Translatotron 2 on the multilingual CVSS-C corpus as well as the bilingual Fisher Spanish-English corpus. On the latter, it outperforms the prior state-of-the-art textless model by +18.5 BLEU.
Training Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Aug 28, 2022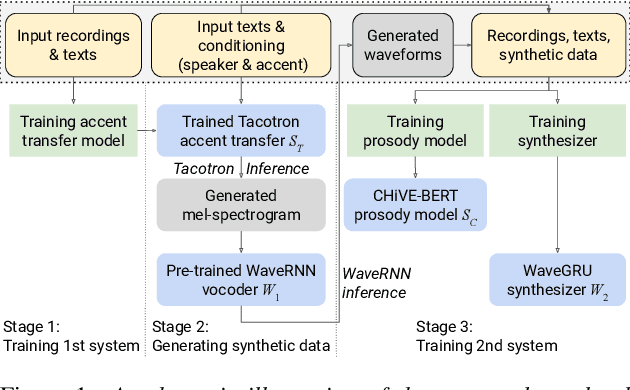
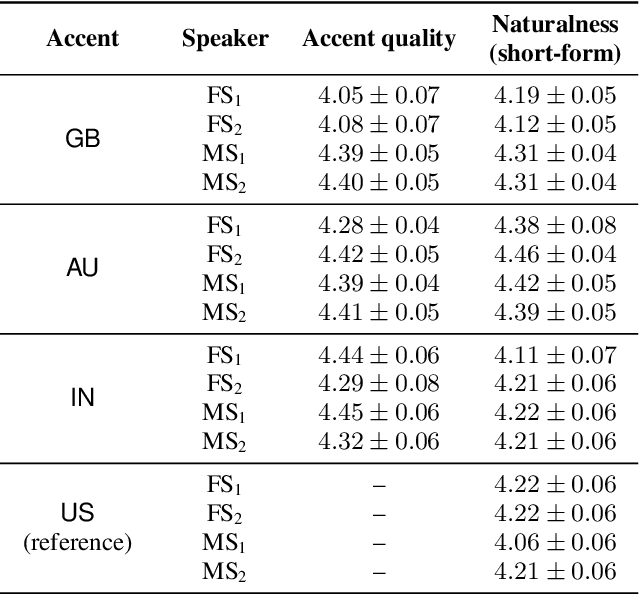
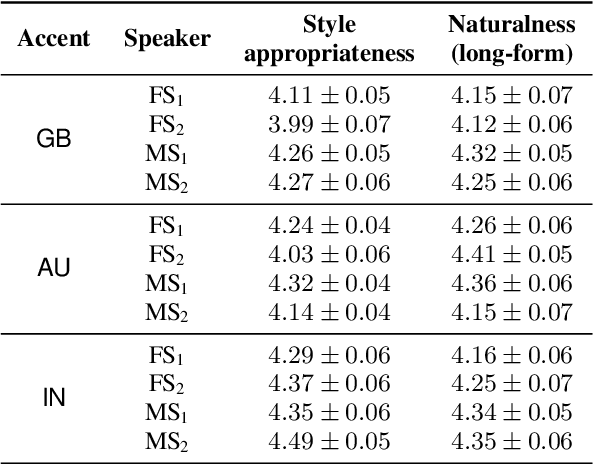
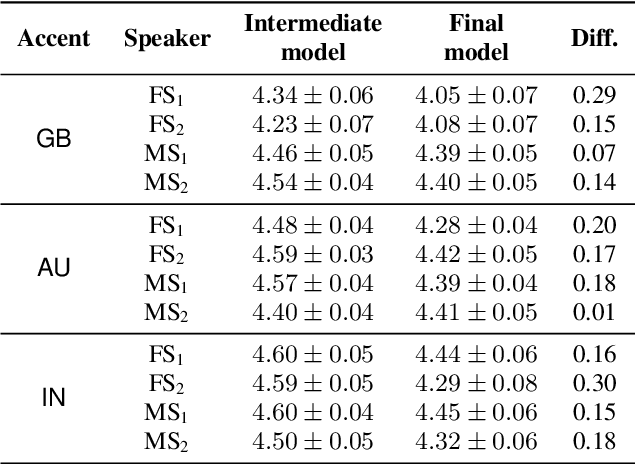
Transfer tasks in text-to-speech (TTS) synthesis - where one or more aspects of the speech of one set of speakers is transferred to another set of speakers that do not feature these aspects originally - remains a challenging task. One of the challenges is that models that have high-quality transfer capabilities can have issues in stability, making them impractical for user-facing critical tasks. This paper demonstrates that transfer can be obtained by training a robust TTS system on data generated by a less robust TTS system designed for a high-quality transfer task; in particular, a CHiVE-BERT monolingual TTS system is trained on the output of a Tacotron model designed for accent transfer. While some quality loss is inevitable with this approach, experimental results show that the models trained on synthetic data this way can produce high quality audio displaying accent transfer, while preserving speaker characteristics such as speaking style.
XTREME-S: Evaluating Cross-lingual Speech Representations
Apr 13, 2022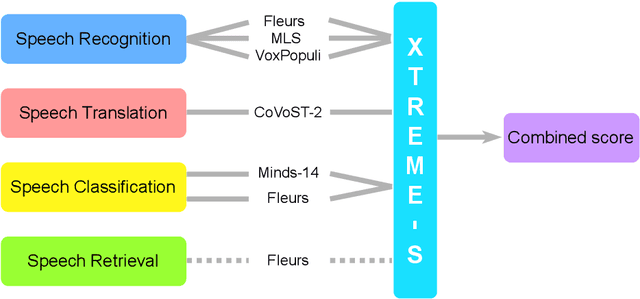
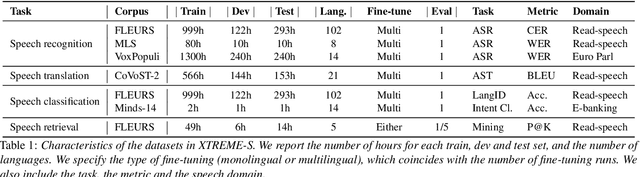
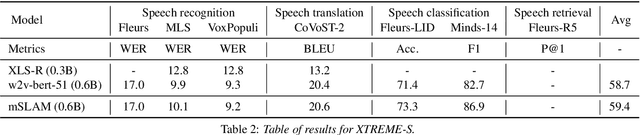
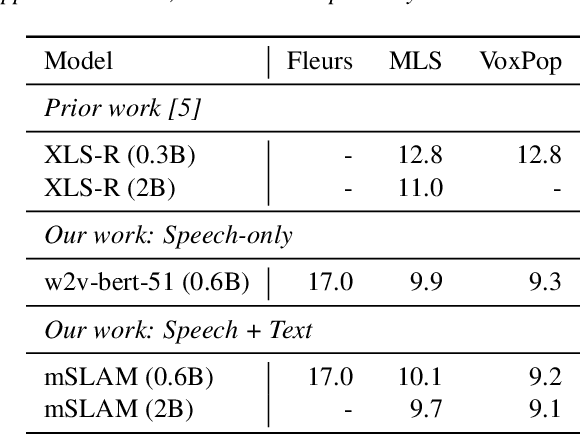
We introduce XTREME-S, a new benchmark to evaluate universal cross-lingual speech representations in many languages. XTREME-S covers four task families: speech recognition, classification, speech-to-text translation and retrieval. Covering 102 languages from 10+ language families, 3 different domains and 4 task families, XTREME-S aims to simplify multilingual speech representation evaluation, as well as catalyze research in "universal" speech representation learning. This paper describes the new benchmark and establishes the first speech-only and speech-text baselines using XLS-R and mSLAM on all downstream tasks. We motivate the design choices and detail how to use the benchmark. Datasets and fine-tuning scripts are made easily accessible at https://hf.co/datasets/google/xtreme_s.
Leveraging unsupervised and weakly-supervised data to improve direct speech-to-speech translation
Mar 24, 2022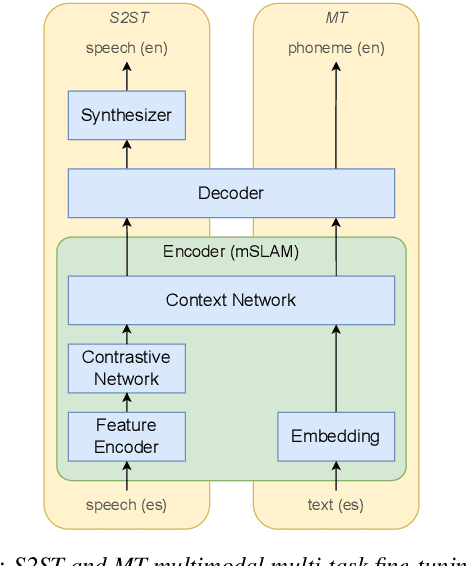
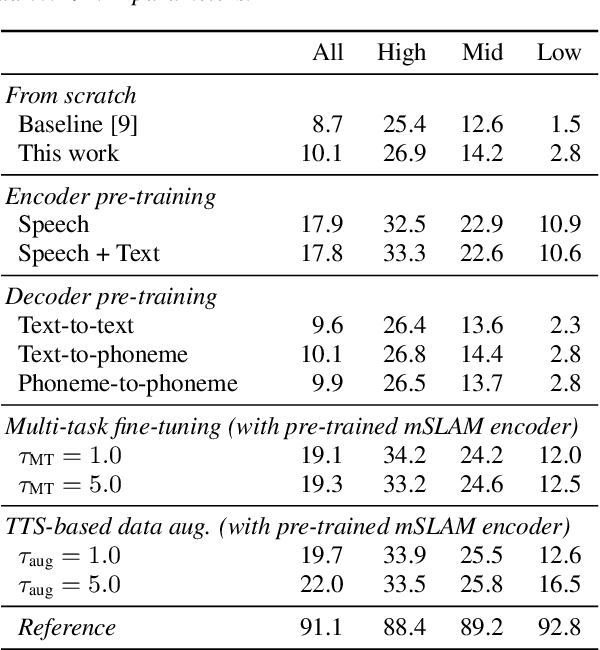
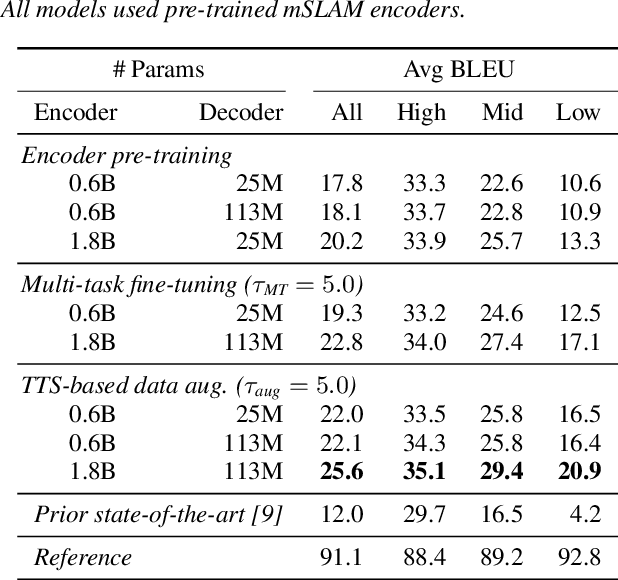
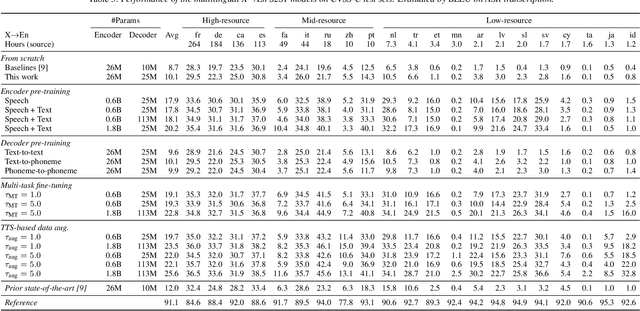
End-to-end speech-to-speech translation (S2ST) without relying on intermediate text representations is a rapidly emerging frontier of research. Recent works have demonstrated that the performance of such direct S2ST systems is approaching that of conventional cascade S2ST when trained on comparable datasets. However, in practice, the performance of direct S2ST is bounded by the availability of paired S2ST training data. In this work, we explore multiple approaches for leveraging much more widely available unsupervised and weakly-supervised speech and text data to improve the performance of direct S2ST based on Translatotron 2. With our most effective approaches, the average translation quality of direct S2ST on 21 language pairs on the CVSS-C corpus is improved by +13.6 BLEU (or +113% relatively), as compared to the previous state-of-the-art trained without additional data. The improvements on low-resource language are even more significant (+398% relatively on average). Our comparative studies suggest future research directions for S2ST and speech representation learning.