 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
SurfelSoup: Learned Point Cloud Geometry Compression With a Probablistic SurfelTree Representation
Jan 30, 2026This paper presents SurfelSoup, an end-to-end learned surface-based framework for point cloud geometry compression, with surface-structured primitives for representation. It proposes a probabilistic surface representation, pSurfel, which models local point occupancies using a bounded generalized Gaussian distribution. In addition, the pSurfels are organized into an octree-like hierarchy, pSurfelTree, with a Tree Decision module that adaptively terminates the tree subdivision for rate-distortion optimal Surfel granularity selection. This formulation avoids redundant point-wise compression in smooth regions and produces compact yet smooth surface reconstructions. Experimental results under the MPEG common test condition show consistent gain on geometry compression over voxel-based baselines and MPEG standard G-PCC-GesTM-TriSoup, while providing visually superior reconstructions with smooth and coherent surface structures.
Efficient Low-Tubal-Rank Tensor Estimation via Alternating Preconditioned Gradient Descent
Dec 23, 2025



The problem of low-tubal-rank tensor estimation is a fundamental task with wide applications across high-dimensional signal processing, machine learning, and image science. Traditional approaches tackle such a problem by performing tensor singular value decomposition, which is computationally expensive and becomes infeasible for large-scale tensors. Recent approaches address this issue by factorizing the tensor into two smaller factor tensors and solving the resulting problem using gradient descent. However, this kind of approach requires an accurate estimate of the tensor rank, and when the rank is overestimated, the convergence of gradient descent and its variants slows down significantly or even diverges. To address this problem, we propose an Alternating Preconditioned Gradient Descent (APGD) algorithm, which accelerates convergence in the over-parameterized setting by adding a preconditioning term to the original gradient and updating these two factors alternately. Based on certain geometric assumptions on the objective function, we establish linear convergence guarantees for more general low-tubal-rank tensor estimation problems. Then we further analyze the specific cases of low-tubal-rank tensor factorization and low-tubal-rank tensor recovery. Our theoretical results show that APGD achieves linear convergence even under over-parameterization, and the convergence rate is independent of the tensor condition number. Extensive simulations on synthetic data are carried out to validate our theoretical assertions.
Noisy MRI Reconstruction via MAP Estimation with an Implicit Deep-Denoiser Prior
Nov 15, 2025Accelerating magnetic resonance imaging (MRI) remains challenging, particularly under realistic acquisition noise. While diffusion models have recently shown promise for reconstructing undersampled MRI data, many approaches lack an explicit link to the underlying MRI physics, and their parameters are sensitive to measurement noise, limiting their reliability in practice. We introduce Implicit-MAP (ImMAP), a diffusion-based reconstruction framework that integrates the acquisition noise model directly into a maximum a posteriori (MAP) formulation. Specifically, we build on the stochastic ascent method of Kadkhodaie et al. and generalize it to handle MRI encoding operators and realistic measurement noise. Across both simulated and real noisy datasets, ImMAP consistently outperforms state-of-the-art deep learning (LPDSNet) and diffusion-based (DDS) methods. By clarifying the practical behavior and limitations of diffusion models under realistic noise conditions, ImMAP establishes a more reliable and interpretable
Non-Rival Data as Rival Products: An Encapsulation-Forging Approach for Data Synthesis
Nov 10, 2025



The non-rival nature of data creates a dilemma for firms: sharing data unlocks value but risks eroding competitive advantage. Existing data synthesis methods often exacerbate this problem by creating data with symmetric utility, allowing any party to extract its value. This paper introduces the Encapsulation-Forging (EnFo) framework, a novel approach to generate rival synthetic data with asymmetric utility. EnFo operates in two stages: it first encapsulates predictive knowledge from the original data into a designated ``key'' model, and then forges a synthetic dataset by optimizing the data to intentionally overfit this key model. This process transforms non-rival data into a rival product, ensuring its value is accessible only to the intended model, thereby preventing unauthorized use and preserving the data owner's competitive edge. Our framework demonstrates remarkable sample efficiency, matching the original data's performance with a fraction of its size, while providing robust privacy protection and resistance to misuse. EnFo offers a practical solution for firms to collaborate strategically without compromising their core analytical advantage.
VoxelFormer: Parameter-Efficient Multi-Subject Visual Decoding from fMRI
Sep 10, 2025Recent advances in fMRI-based visual decoding have enabled compelling reconstructions of perceived images. However, most approaches rely on subject-specific training, limiting scalability and practical deployment. We introduce \textbf{VoxelFormer}, a lightweight transformer architecture that enables multi-subject training for visual decoding from fMRI. VoxelFormer integrates a Token Merging Transformer (ToMer) for efficient voxel compression and a query-driven Q-Former that produces fixed-size neural representations aligned with the CLIP image embedding space. Evaluated on the 7T Natural Scenes Dataset, VoxelFormer achieves competitive retrieval performance on subjects included during training with significantly fewer parameters than existing methods. These results highlight token merging and query-based transformers as promising strategies for parameter-efficient neural decoding.
Machine Learning-Based Prediction of Speech Arrest During Direct Cortical Stimulation Mapping
Sep 10, 2025Identifying cortical regions critical for speech is essential for safe brain surgery in or near language areas. While Electrical Stimulation Mapping (ESM) remains the clinical gold standard, it is invasive and time-consuming. To address this, we analyzed intracranial electrocorticographic (ECoG) data from 16 participants performing speech tasks and developed machine learning models to directly predict if the brain region underneath each ECoG electrode is critical. Ground truth labels indicating speech arrest were derived independently from Electrical Stimulation Mapping (ESM) and used to train classification models. Our framework integrates neural activity signals, anatomical region labels, and functional connectivity features to capture both local activity and network-level dynamics. We found that models combining region and connectivity features matched the performance of the full feature set, and outperformed models using either type alone. To classify each electrode, trial-level predictions were aggregated using an MLP applied to histogram-encoded scores. Our best-performing model, a trial-level RBF-kernel Support Vector Machine together with MLP-based aggregation, achieved strong accuracy on held-out participants (ROC-AUC: 0.87, PR-AUC: 0.57). These findings highlight the value of combining spatial and network information with non-linear modeling to improve functional mapping in presurgical evaluation.
Not All Parameters Are Created Equal: Smart Isolation Boosts Fine-Tuning Performance
Aug 29, 2025



Supervised fine-tuning (SFT) is a pivotal approach to adapting large language models (LLMs) for downstream tasks; however, performance often suffers from the ``seesaw phenomenon'', where indiscriminate parameter updates yield progress on certain tasks at the expense of others. To address this challenge, we propose a novel \emph{Core Parameter Isolation Fine-Tuning} (CPI-FT) framework. Specifically, we first independently fine-tune the LLM on each task to identify its core parameter regions by quantifying parameter update magnitudes. Tasks with similar core regions are then grouped based on region overlap, forming clusters for joint modeling. We further introduce a parameter fusion technique: for each task, core parameters from its individually fine-tuned model are directly transplanted into a unified backbone, while non-core parameters from different tasks are smoothly integrated via Spherical Linear Interpolation (SLERP), mitigating destructive interference. A lightweight, pipelined SFT training phase using mixed-task data is subsequently employed, while freezing core regions from prior tasks to prevent catastrophic forgetting. Extensive experiments on multiple public benchmarks demonstrate that our approach significantly alleviates task interference and forgetting, consistently outperforming vanilla multi-task and multi-stage fine-tuning baselines.
TeSO: Representing and Compressing 3D Point Cloud Scenes with Textured Surfel Octree
Aug 09, 20253D visual content streaming is a key technology for emerging 3D telepresence and AR/VR applications. One fundamental element underlying the technology is a versatile 3D representation that is capable of producing high-quality renders and can be efficiently compressed at the same time. Existing 3D representations like point clouds, meshes and 3D Gaussians each have limitations in terms of rendering quality, surface definition, and compressibility. In this paper, we present the Textured Surfel Octree (TeSO), a novel 3D representation that is built from point clouds but addresses the aforementioned limitations. It represents a 3D scene as cube-bounded surfels organized on an octree, where each surfel is further associated with a texture patch. By approximating a smooth surface with a large surfel at a coarser level of the octree, it reduces the number of primitives required to represent the 3D scene, and yet retains the high-frequency texture details through the texture map attached to each surfel. We further propose a compression scheme to encode the geometry and texture efficiently, leveraging the octree structure. The proposed textured surfel octree combined with the compression scheme achieves higher rendering quality at lower bit-rates compared to multiple point cloud and 3D Gaussian-based baselines.
DualSG: A Dual-Stream Explicit Semantic-Guided Multivariate Time Series Forecasting Framework
Jul 30, 2025
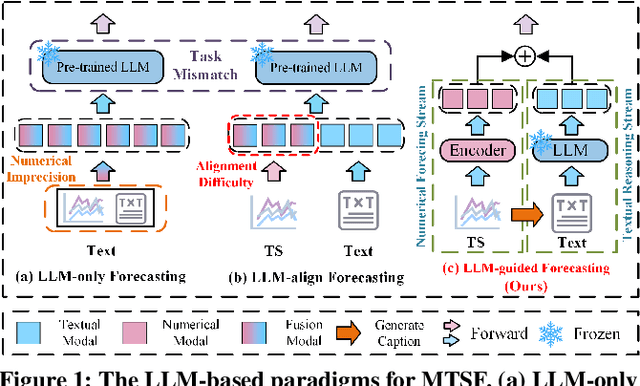
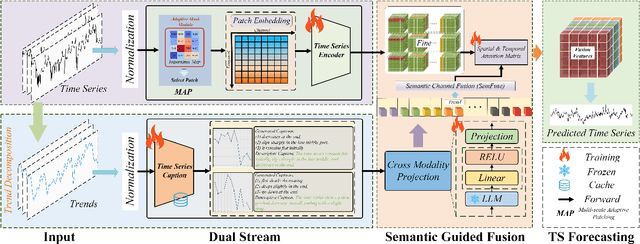

Multivariate Time Series Forecasting plays a key role in many applications. Recent works have explored using Large Language Models for MTSF to take advantage of their reasoning abilities. However, many methods treat LLMs as end-to-end forecasters, which often leads to a loss of numerical precision and forces LLMs to handle patterns beyond their intended design. Alternatively, methods that attempt to align textual and time series modalities within latent space frequently encounter alignment difficulty. In this paper, we propose to treat LLMs not as standalone forecasters, but as semantic guidance modules within a dual-stream framework. We propose DualSG, a dual-stream framework that provides explicit semantic guidance, where LLMs act as Semantic Guides to refine rather than replace traditional predictions. As part of DualSG, we introduce Time Series Caption, an explicit prompt format that summarizes trend patterns in natural language and provides interpretable context for LLMs, rather than relying on implicit alignment between text and time series in the latent space. We also design a caption-guided fusion module that explicitly models inter-variable relationships while reducing noise and computation. Experiments on real-world datasets from diverse domains show that DualSG consistently outperforms 15 state-of-the-art baselines, demonstrating the value of explicitly combining numerical forecasting with semantic guidance.