 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Rival Data as Rival Products: An Encapsulation-Forging Approach for Data Synthesis
Nov 10, 2025



The non-rival nature of data creates a dilemma for firms: sharing data unlocks value but risks eroding competitive advantage. Existing data synthesis methods often exacerbate this problem by creating data with symmetric utility, allowing any party to extract its value. This paper introduces the Encapsulation-Forging (EnFo) framework, a novel approach to generate rival synthetic data with asymmetric utility. EnFo operates in two stages: it first encapsulates predictive knowledge from the original data into a designated ``key'' model, and then forges a synthetic dataset by optimizing the data to intentionally overfit this key model. This process transforms non-rival data into a rival product, ensuring its value is accessible only to the intended model, thereby preventing unauthorized use and preserving the data owner's competitive edge. Our framework demonstrates remarkable sample efficiency, matching the original data's performance with a fraction of its size, while providing robust privacy protection and resistance to misuse. EnFo offers a practical solution for firms to collaborate strategically without compromising their core analytical advantage.
Matrix Completion with Graph Information: A Provable Nonconvex Optimization Approach
Feb 12, 2025



We consider the problem of matrix completion with graphs as side information depicting the interrelations between variables. The key challenge lies in leveraging the similarity structure of the graph to enhance matrix recovery. Existing approaches, primarily based on graph Laplacian regularization, suffer from several limitations: (1) they focus only on the similarity between neighboring variables, while overlooking long-range correlations; (2) they are highly sensitive to false edges in the graphs and (3) they lack theoretical guarantees regarding statistical and computational complexities. To address these issues, we propose in this paper a novel graph regularized matrix completion algorithm called GSGD, based on preconditioned projected gradient descent approach. We demonstrate that GSGD effectively captures the higher-order correlation information behind the graphs, and achieves superior robustness and stability against the false edges. Theoretically, we prove that GSGD achieves linear convergence to the global optimum with near-optimal sample complexity, providing the first theoretical guarantees for both recovery accuracy and efficacy in the perspective of nonconvex optimization. Our numerical experiments on both synthetic and real-world data further validate that GSGD achieves superior recovery accuracy and scalability compared with several popular alternatives.
Electrically functionalized body surface for deep-tissue bioelectrical recording
Dec 04, 2024



Directly probing deep tissue activities from body surfaces offers a noninvasive approach to monitoring essential physiological processes1-3. However, this method is technically challenged by rapid signal attenuation toward the body surface and confounding motion artifacts4-6 primarily due to excessive contact impedance and mechanical mismatch with conventional electrodes. Herein, by formulating and directly spray coating biocompatible two-dimensional nanosheet ink onto the human body under ambient conditions, we create microscopically conformal and adaptive van der Waals thin films (VDWTFs) that seamlessly merge with non-Euclidean, hairy, and dynamically evolving body surfaces. Unlike traditional deposition methods, which often struggle with conformality and adaptability while retaining high electronic performance, this gentle process enables the formation of high-performance VDWTFs directly on the body surface under bio-friendly conditions, making it ideal for biological applications. This results in low-impedance electrically functionalized body surfaces (EFBS), enabling highly robust monitoring of biopotential and bioimpedance modulations associated with deep-tissue activities, such as blood circulation, muscle movements, and brain activities. Compared to commercial solutions, our VDWTF-EFBS exhibits nearly two-orders of magnitude lower contact impedance and substantially reduces the extrinsic motion artifacts, enabling reliable extraction of bioelectrical signals from irregular surfaces, such as unshaved human scalps. This advancement defines a technology for continuous, noninvasive monitoring of deep-tissue activities during routine body movements.
LoCI-DiffCom: Longitudinal Consistency-Informed Diffusion Model for 3D Infant Brain Image Completion
May 17, 2024



The infant brain undergoes rapid development in the first few years after birth.Compared to cross-sectional studies, longitudinal studies can depict the trajectories of infants brain development with higher accuracy, statistical power and flexibility.However, the collection of infant longitudinal magnetic resonance (MR) data suffers a notorious dropout problem, resulting in incomplete datasets with missing time points. This limitation significantly impedes subsequent neuroscience and clinical modeling. Yet, existing deep generative models are facing difficulties in missing brain image completion, due to sparse data and the nonlinear, dramatic contrast/geometric variations in the developing brain. We propose LoCI-DiffCom, a novel Longitudinal Consistency-Informed Diffusion model for infant brain image Completion,which integrates the images from preceding and subsequent time points to guide a diffusion model for generating high-fidelity missing data. Our designed LoCI module can work on highly sparse sequences, relying solely on data from two temporal points. Despite wide separation and diversity between age time points, our approach can extract individualized developmental features while ensuring context-aware consistency. Our experiments on a large infant brain MR dataset demonstrate its effectiveness with consistent performance on missing infant brain MR completion even in big gap scenarios, aiding in better delineation of early developmental trajectories.
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Mar 08, 2024



Multiple cameras can provide multi-view video coverage of a person. It is necessary to fuse multi-view data, e.g., for subsequent behavioral analysis, while such fusion often relies on calibration of cameras in traditional solutions. However, it is non-trivial to calibrate multiple cameras. In this work, we propose a method to reconstruct 3D human body from multiple uncalibrated camera views. First, we adopt a pre-trained human body encoder to process each individual camera view, such that human body models and parameters can be reconstructed for each view. Next, instead of simply averaging models across views, we train a network to determine the weights of individual views for their fusion, based on the parameters estimated for joints and hands of human body as well as camera positions. Further, we turn to the mesh surface of human body for dynamic fusion, such that facial expression can be seamlessly integrated into the model of human body. Our method has demonstrated superior performance in reconstructing human body upon two public datasets. More importantly, our method can flexibly support ad-hoc deployment of an arbitrary number of cameras, which has significant potential in related applications. We will release source code upon acceptance of the paper.
Provable Tensor Completion with Graph Information
Oct 04, 2023



Graphs, depicting the interrelations between variables, has been widely used as effective side information for accurate data recovery in various matrix/tensor recovery related applications. In this paper, we study the tensor completion problem with graph information. Current research on graph-regularized tensor completion tends to be task-specific, lacking generality and systematic approaches. Furthermore, a recovery theory to ensure performance remains absent. Moreover, these approaches overlook the dynamic aspects of graphs, treating them as static akin to matrices, even though graphs could exhibit dynamism in tensor-related scenarios. To confront these challenges, we introduce a pioneering framework in this paper that systematically formulates a novel model, theory, and algorithm for solving the dynamic graph regularized tensor completion problem. For the model, we establish a rigorous mathematical representation of the dynamic graph, based on which we derive a new tensor-oriented graph smoothness regularization. By integrating this regularization into a tensor decomposition model based on transformed t-SVD, we develop a comprehensive model simultaneously capturing the low-rank and similarity structure of the tensor. In terms of theory, we showcase the alignment between the proposed graph smoothness regularization and a weighted tensor nuclear norm. Subsequently, we establish assurances of statistical consistency for our model, effectively bridging a gap in the theoretical examination of the problem involving tensor recovery with graph information. In terms of the algorithm, we develop a solution of high effectiveness, accompanied by a guaranteed convergence, to address the resulting model. To showcase the prowess of our proposed model in contrast to established ones, we provide in-depth numerical experiments encompassing synthetic data as well as real-world datasets.
Efficient Fraud Detection using Deep Boosting Decision Trees
Feb 12, 2023Fraud detection is to identify, monitor, and prevent potentially fraudulent activities from complex data. The recent development and success in AI, especially machine learning, provides a new data-driven way to deal with fraud. From a methodological point of view, machine learning based fraud detection can be divided into two categories, i.e., conventional methods (decision tree, boosting...) and deep learning, both of which have significant limitations in terms of the lack of representation learning ability for the former and interpretability for the latter. Furthermore, due to the rarity of detected fraud cases, the associated data is usually imbalanced, which seriously degrades the performance of classification algorithms. In this paper, we propose deep boosting decision trees (DBDT), a novel approach for fraud detection based on gradient boosting and neural networks. In order to combine the advantages of both conventional methods and deep learning, we first construct soft decision tree (SDT), a decision tree structured model with neural networks as its nodes, and then ensemble SDTs using the idea of gradient boosting. In this way we embed neural networks into gradient boosting to improve its representation learning capability and meanwhile maintain the interpretability. Furthermore, aiming at the rarity of detected fraud cases, in the model training phase we propose a compositional AUC maximization approach to deal with data imbalances at algorithm level. Extensive experiments on several real-life fraud detection datasets show that DBDT can significantly improve the performance and meanwhile maintain good interpretability. Our code is available at https://github.com/freshmanXB/DBDT.
Effective Streaming Low-tubal-rank Tensor Approximation via Frequent Directions
Aug 23, 2021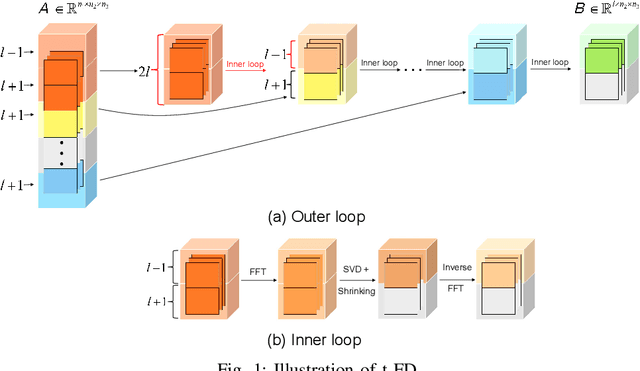
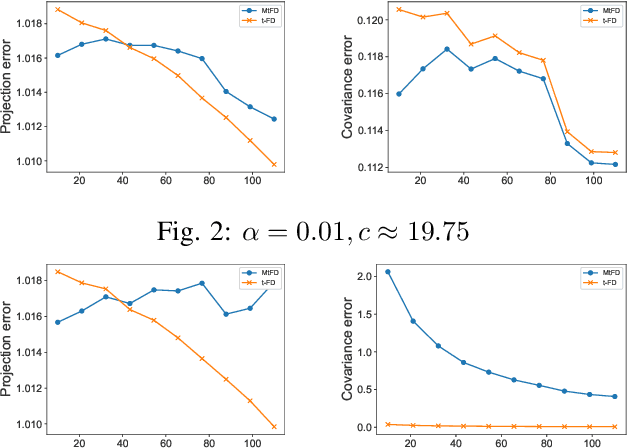
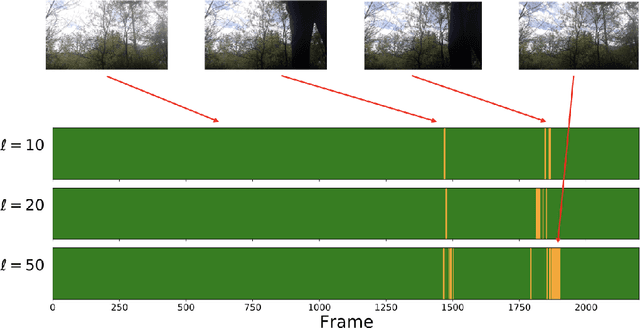
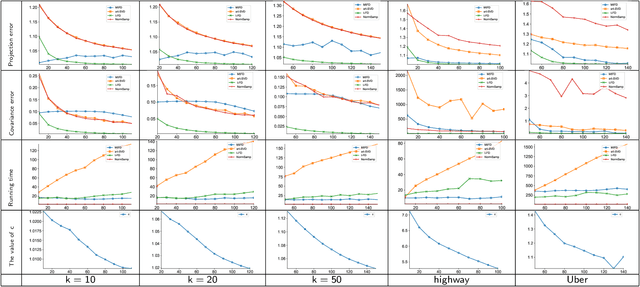
Low-tubal-rank tensor approximation has been proposed to analyze large-scale and multi-dimensional data. However, finding such an accurate approximation is challenging in the streaming setting, due to the limited computational resources. To alleviate this issue, this paper extends a popular matrix sketching technique, namely Frequent Directions, for constructing an efficient and accurate low-tubal-rank tensor approximation from streaming data based on the tensor Singular Value Decomposition (t-SVD). Specifically, the new algorithm allows the tensor data to be observed slice by slice, but only needs to maintain and incrementally update a much smaller sketch which could capture the principal information of the original tensor. The rigorous theoretical analysis shows that the approximation error of the new algorithm can be arbitrarily small when the sketch size grows linearly. Extensive experimental results on both synthetic and real multi-dimensional data further reveal the superiority of the proposed algorithm compared with other sketching algorithms for getting low-tubal-rank approximation, in terms of both efficiency and accuracy.
Universal Consistency of Deep Convolutional Neural Networks
Jun 23, 2021
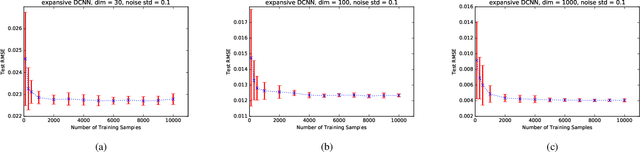
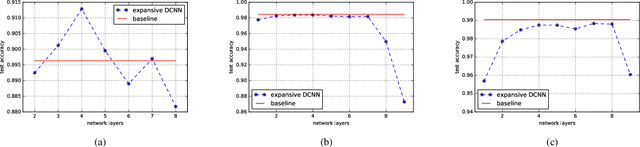
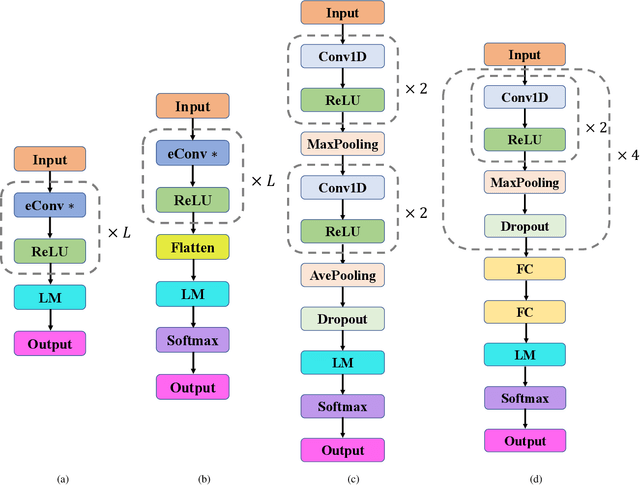
Compared with avid research activities of deep convolutional neural networks (DCNNs) in practice, the study of theoretical behaviors of DCNNs lags heavily behind. In particular, the universal consistency of DCNNs remains open. In this paper, we prove that implementing empirical risk minimization on DCNNs with expansive convolution (with zero-padding) is strongly universally consistent. Motivated by the universal consistency, we conduct a series of experiments to show that without any fully connected layers, DCNNs with expansive convolution perform not worse than the widely used deep neural networks with hybrid structure containing contracting (without zero-padding) convolution layers and several fully connected layers.
SPLBoost: An Improved Robust Boosting Algorithm Based on Self-paced Learning
Jun 23, 2017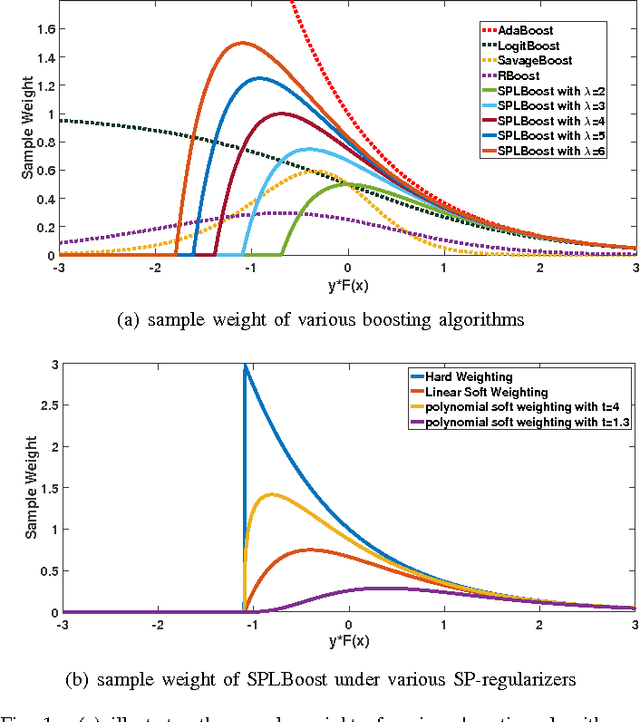
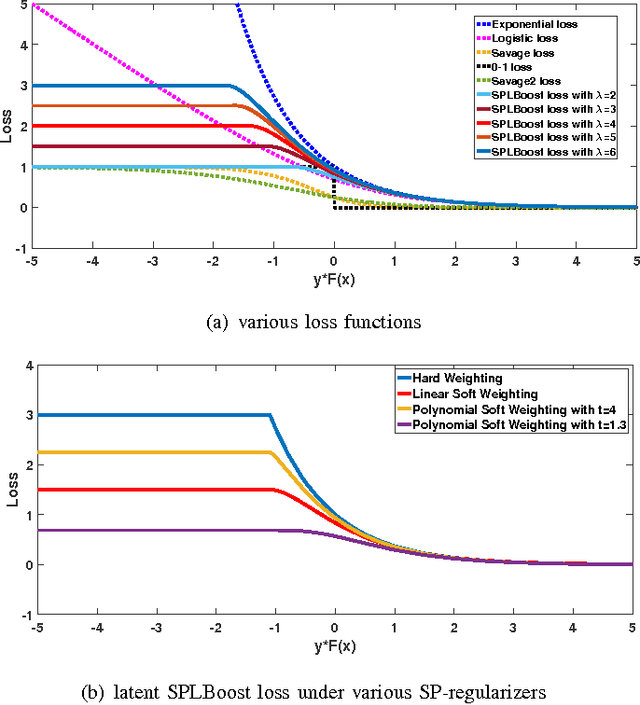
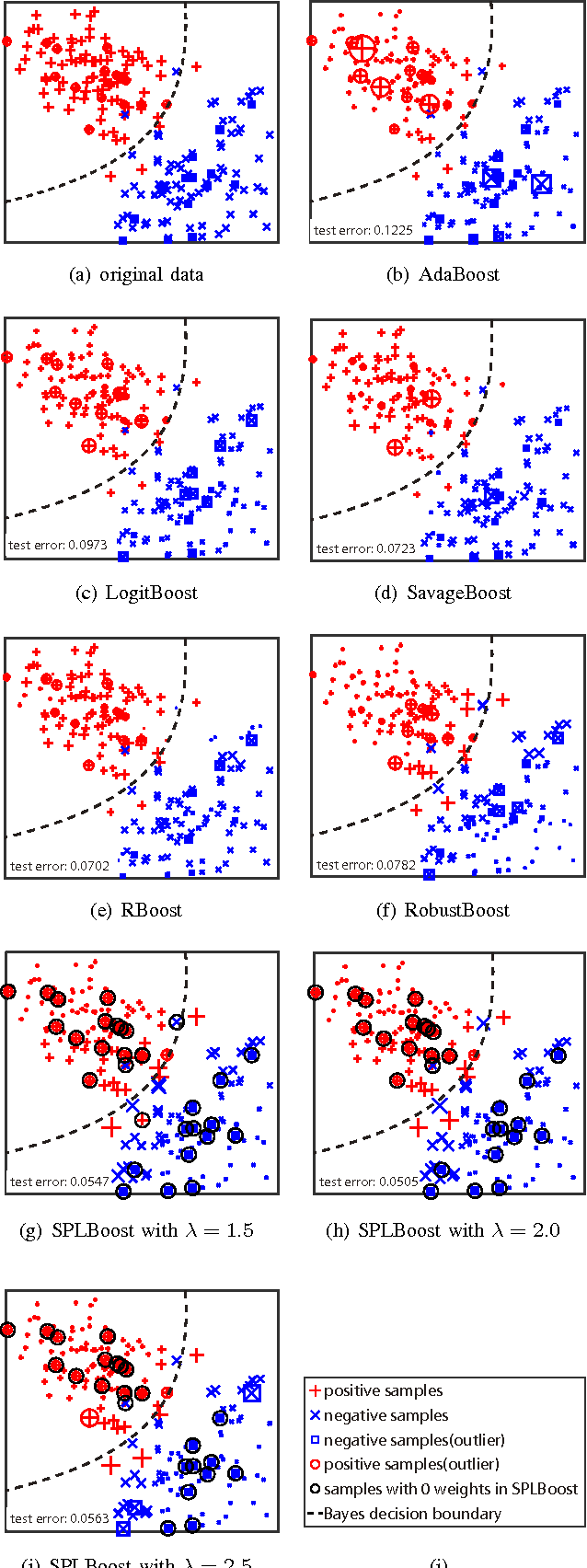
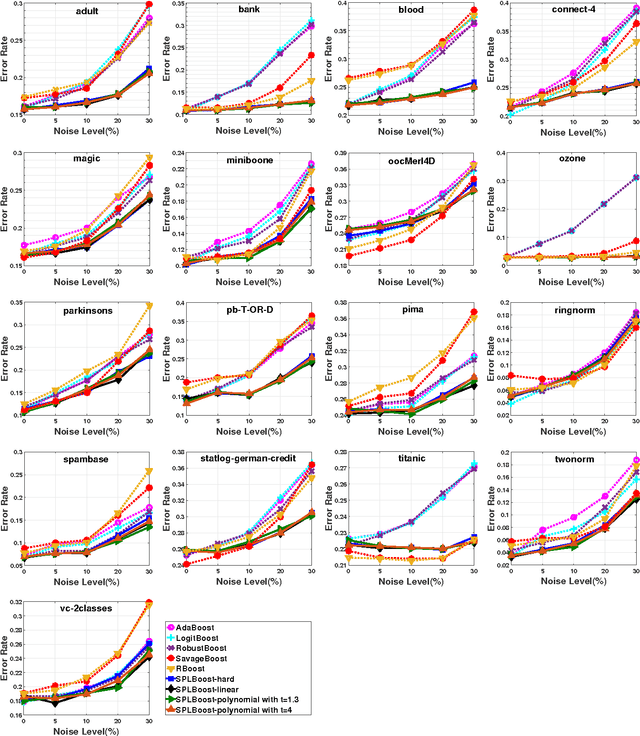
It is known that Boosting can be interpreted as a gradient descent technique to minimize an underlying loss function. Specifically, the underlying loss being minimized by the traditional AdaBoost is the exponential loss, which is proved to be very sensitive to random noise/outliers. Therefore, several Boosting algorithms, e.g., LogitBoost and SavageBoost, have been proposed to improve the robustness of AdaBoost by replacing the exponential loss with some designed robust loss functions. In this work, we present a new way to robustify AdaBoost, i.e., incorporating the robust learning idea of Self-paced Learning (SPL) into Boosting framework. Specifically, we design a new robust Boosting algorithm based on SPL regime, i.e., SPLBoost, which can be easily implemented by slightly modifying off-the-shelf Boosting packages. Extensive experiments and a theoretical characterization are also carried out to illustrate the merits of the proposed SPLBoost.