 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRI: Spatial Relation Induced Network For Spatial Description Resolution
Oct 27, 2020
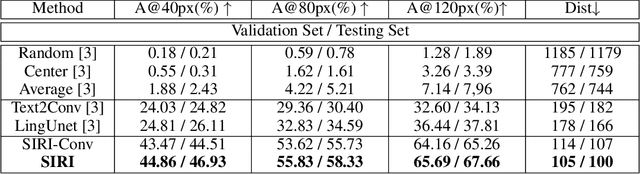
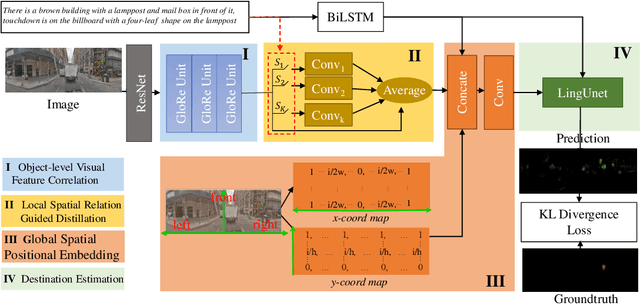

Spatial Description Resolution, as a language-guided localization task, is proposed for target location in a panoramic street view, given corresponding language descriptions. Explicitly characterizing an object-level relationship while distilling spatial relationships are currently absent but crucial to this task. Mimicking humans, who sequentially traverse spatial relationship words and objects with a first-person view to locate their target, we propose a novel spatial relationship induced (SIRI) network. Specifically, visual features are firstly correlated at an implicit object-level in a projected latent space; then they are distilled by each spatial relationship word, resulting in each differently activated feature representing each spatial relationship. Further, we introduce global position priors to fix the absence of positional information, which may result in global positional reasoning ambiguities. Both the linguistic and visual features are concatenated to finalize the target localization. Experimental results on the Touchdown show that our method is around 24\% better than the state-of-the-art method in terms of accuracy, measured by an 80-pixel radius. Our method also generalizes well on our proposed extended dataset collected using the same settings as Touchdown.
PPGNet: Learning Point-Pair Graph for Line Segment Detection
May 16, 2019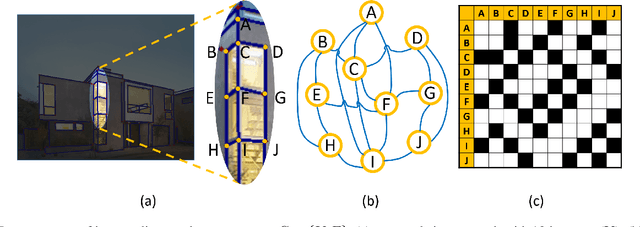

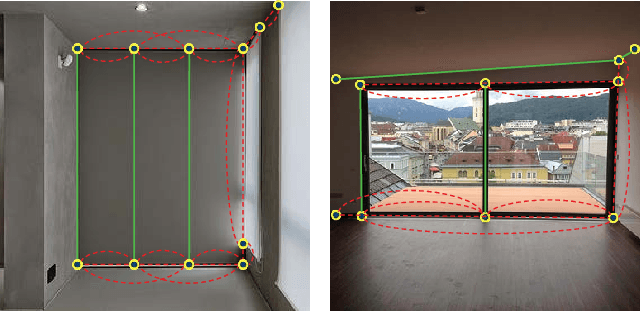
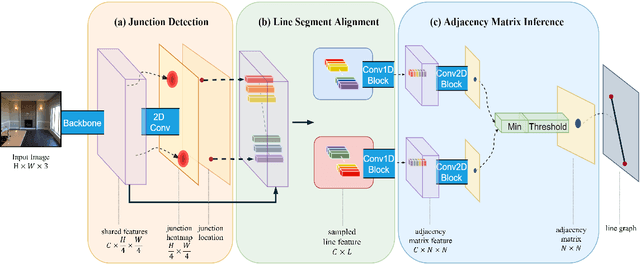
In this paper, we present a novel framework to detect line segments in man-made environments. Specifically, we propose to describe junctions, line segments and relationships between them with a simple graph, which is more structured and informative than end-point representation used in existing line segment detection methods. In order to extract a line segment graph from an image, we further introduce the PPGNet, a convolutional neural network that directly infers a graph from an image. We evaluate our method on published benchmarks including York Urban and Wireframe datasets. The results demonstrate that our method achieves satisfactory performance and generalizes well on all the benchmarks. The source code of our work is available at \url{https://github.com/svip-lab/PPGNet}.
Semantic Human Matting
Sep 18, 2018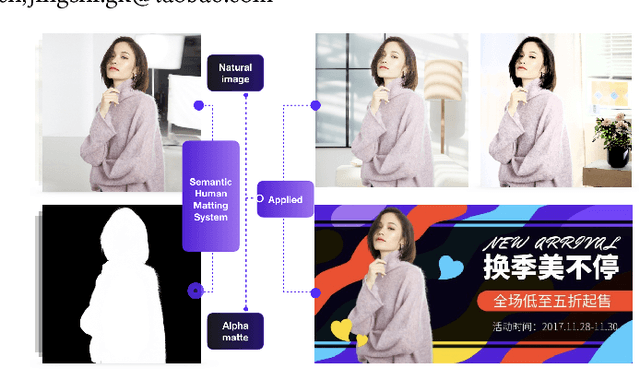
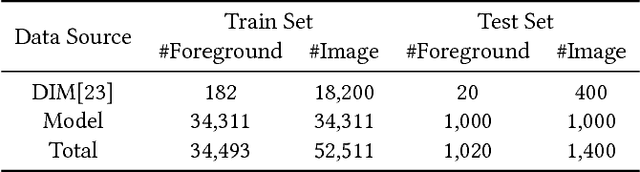


Human matting, high quality extraction of humans from natural images, is crucial for a wide variety of applications. Since the matting problem is severely under-constrained, most previous methods require user interactions to take user designated trimaps or scribbles as constraints. This user-in-the-loop nature makes them difficult to be applied to large scale data or time-sensitive scenarios. In this paper, instead of using explicit user input constraints, we employ implicit semantic constraints learned from data and propose an automatic human matting algorithm (SHM). SHM is the first algorithm that learns to jointly fit both semantic information and high quality details with deep networks. In practice, simultaneously learning both coarse semantics and fine details is challenging. We propose a novel fusion strategy which naturally gives a probabilistic estimation of the alpha matte. We also construct a very large dataset with high quality annotations consisting of 35,513 unique foregrounds to facilitate the learning and evaluation of human matting. Extensive experiments on this dataset and plenty of real images show that SHM achieves comparable results with state-of-the-art interactive matting methods.
Personalized Saliency and its Prediction
Jun 16, 2018
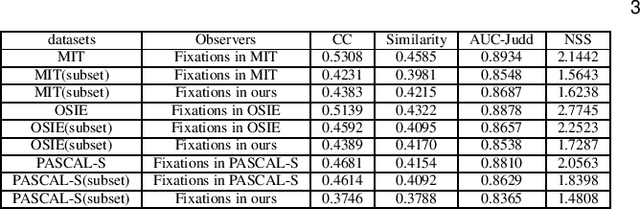
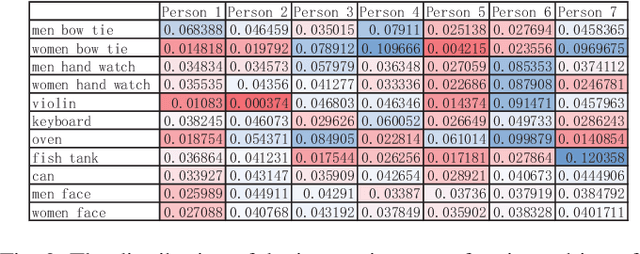
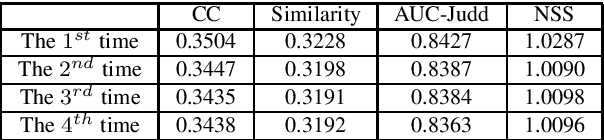
Nearly all existing visual saliency models by far have focused on predicting a universal saliency map across all observers. Yet psychology studies suggest that visual attention of different observers can vary significantly under specific circumstances, especially a scene is composed of multiple salient objects. To study such heterogenous visual attention pattern across observers, we first construct a personalized saliency dataset and explore correlations between visual attention, personal preferences, and image contents. Specifically, we propose to decompose a personalized saliency map (referred to as PSM) into a universal saliency map (referred to as USM) predictable by existing saliency detection models and a new discrepancy map across users that characterizes personalized saliency. We then present two solutions towards predicting such discrepancy maps, i.e., a multi-task convolutional neural network (CNN) framework and an extended CNN with Person-specific Information Encoded Filters (CNN-PIEF). Extensive experimental results demonstrate the effectiveness of our models for PSM prediction as well their generalization capability for unseen observers.