 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Generalization in Graph Neural Networks: A Structural Complexity Perspective
May 13, 2026Graph neural networks (GNNs) have emerged as a fundamental tool for learning from graph-structured data, achieving strong performance across a wide range of applications. However, understanding their generalization capabilities remains challenging due to the complex structural dependencies inherent in such data. Existing generalization analyses largely follow the classical machine learning paradigm, focusing primarily on model complexity while overlooking the fundamental role of graph structure. Therefore, in this work, we systematically investigate this role by asking: does the graph structure actually influence generalization, and if so, by how much? To answer the first question and validate our intuition, we theoretically prove that incorporating more edges into the prediction process transforms the input representations to be overly accommodating to the output model, thereby inducing overfitting. To address the second question, we formulate a structural complexity measure based on the number of effective edges and derive a Rademacher complexity-based generalization bound. In doing so, we demonstrate that GNN generalization depends explicitly on structural complexity, alongside traditional parameter-dependent factors. Motivated by these theoretical findings, we propose a structural entropy regularization method. This approach controls structural complexity by regulating effective edges to balance underfitting and overfitting, ultimately improving the generalization performance of GNNs.
Reinforcing Structured Chain-of-Thought for Video Understanding
Mar 26, 2026Multi-modal Large Language Models (MLLMs) show promise in video understanding. However, their reasoning often suffers from thinking drift and weak temporal comprehension, even when enhanced by Reinforcement Learning (RL) techniques like Group Relative Policy Optimization (GRPO). Moreover, existing RL methods usually depend on Supervised Fine-Tuning (SFT), which requires costly Chain-of-Thought (CoT) annotation and multi-stage training, and enforces fixed reasoning paths, limiting MLLMs' ability to generalize and potentially inducing bias. To overcome these limitations, we introduce Summary-Driven Reinforcement Learning (SDRL), a novel single-stage RL framework that obviates the need for SFT by utilizing a Structured CoT format: Summarize -> Think -> Answer. SDRL introduces two self-supervised mechanisms integrated into the GRPO objective: 1) Consistency of Vision Knowledge (CVK) enforces factual grounding by reducing KL divergence among generated summaries; and 2) Dynamic Variety of Reasoning (DVR) promotes exploration by dynamically modulating thinking diversity based on group accuracy. This novel integration effectively balances alignment and exploration, supervising both the final answer and the reasoning process. Our method achieves state-of-the-art performance on seven public VideoQA datasets.
PhysCorr: Dual-Reward DPO for Physics-Constrained Text-to-Video Generation with Automated Preference Selection
Nov 06, 2025



Recent advances in text-to-video generation have achieved impressive perceptual quality, yet generated content often violates fundamental principles of physical plausibility - manifesting as implausible object dynamics, incoherent interactions, and unrealistic motion patterns. Such failures hinder the deployment of video generation models in embodied AI, robotics, and simulation-intensive domains. To bridge this gap, we propose PhysCorr, a unified framework for modeling, evaluating, and optimizing physical consistency in video generation. Specifically, we introduce PhysicsRM, the first dual-dimensional reward model that quantifies both intra-object stability and inter-object interactions. On this foundation, we develop PhyDPO, a novel direct preference optimization pipeline that leverages contrastive feedback and physics-aware reweighting to guide generation toward physically coherent outputs. Our approach is model-agnostic and scalable, enabling seamless integration into a wide range of video diffusion and transformer-based backbones. Extensive experiments across multiple benchmarks demonstrate that PhysCorr achieves significant improvements in physical realism while preserving visual fidelity and semantic alignment. This work takes a critical step toward physically grounded and trustworthy video generation.
FunAudio-ASR Technical Report
Sep 15, 2025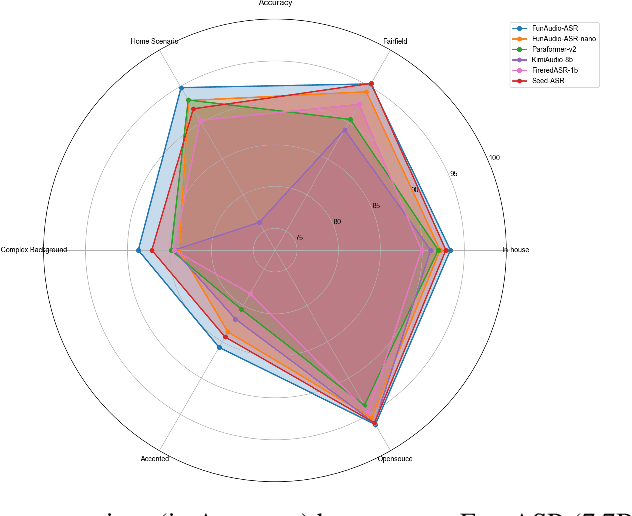
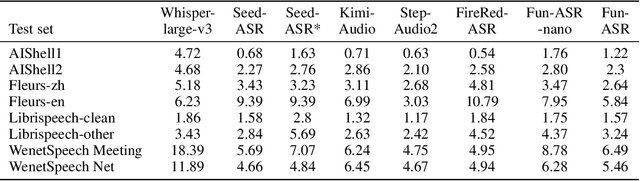
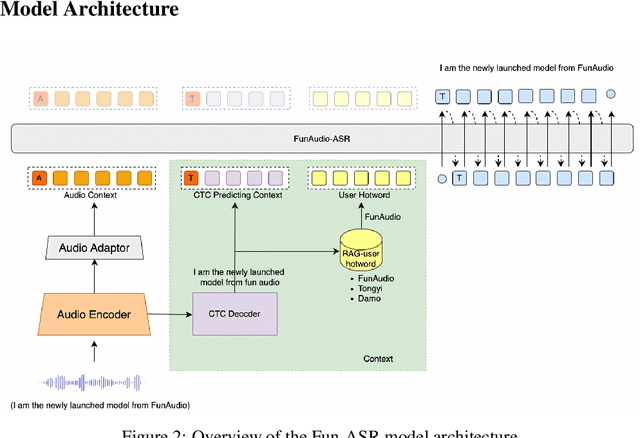
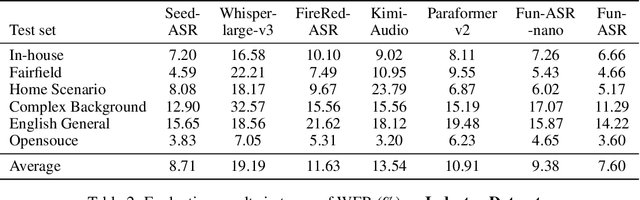
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Spectra-to-Structure and Structure-to-Spectra Inference Across the Periodic Table
Jun 13, 2025X-ray Absorption Spectroscopy (XAS) is a powerful technique for probing local atomic environments, yet its interpretation remains limited by the need for expert-driven analysis, computationally expensive simulations, and element-specific heuristics. Recent advances in machine learning have shown promise for accelerating XAS interpretation, but many existing models are narrowly focused on specific elements, edge types, or spectral regimes. In this work, we present XAStruct, a learning framework capable of both predicting XAS spectra from crystal structures and inferring local structural descriptors from XAS input. XAStruct is trained on a large-scale dataset spanning over 70 elements across the periodic table, enabling generalization to a wide variety of chemistries and bonding environments. The model includes the first machine learning approach for predicting neighbor atom types directly from XAS spectra, as well as a unified regression model for mean nearest-neighbor distance that requires no element-specific tuning. While we explored integrating the two pipelines into a single end-to-end model, empirical results showed performance degradation. As a result, the two tasks were trained independently to ensure optimal accuracy and task-specific performance. By combining deep neural networks for complex structure-property mappings with efficient baseline models for simpler tasks, XAStruct offers a scalable and extensible solution for data-driven XAS analysis and local structure inference. The source code will be released upon paper acceptance.
Efficient Temporal Action Segmentation via Boundary-aware Query Voting
May 25, 2024Although the performance of Temporal Action Segmentation (TAS) has improved in recent years, achieving promising results often comes with a high computational cost due to dense inputs, complex model structures, and resource-intensive post-processing requirements. To improve the efficiency while keeping the performance, we present a novel perspective centered on per-segment classification. By harnessing the capabilities of Transformers, we tokenize each video segment as an instance token, endowed with intrinsic instance segmentation. To realize efficient action segmentation, we introduce BaFormer, a boundary-aware Transformer network. It employs instance queries for instance segmentation and a global query for class-agnostic boundary prediction, yielding continuous segment proposals. During inference, BaFormer employs a simple yet effective voting strategy to classify boundary-wise segments based on instance segmentation. Remarkably, as a single-stage approach, BaFormer significantly reduces the computational costs, utilizing only 6% of the running time compared to state-of-the-art method DiffAct, while producing better or comparable accuracy over several popular benchmarks. The code for this project is publicly available at https://github.com/peiyao-w/BaFormer.
CTC Blank Triggered Dynamic Layer-Skipping for Efficient CTC-based Speech Recognition
Jan 04, 2024Deploying end-to-end speech recognition models with limited computing resources remains challenging, despite their impressive performance. Given the gradual increase in model size and the wide range of model applications, selectively executing model components for different inputs to improve the inference efficiency is of great interest. In this paper, we propose a dynamic layer-skipping method that leverages the CTC blank output from intermediate layers to trigger the skipping of the last few encoder layers for frames with high blank probabilities. Furthermore, we factorize the CTC output distribution and perform knowledge distillation on intermediate layers to reduce computation and improve recognition accuracy. Experimental results show that by utilizing the CTC blank, the encoder layer depth can be adjusted dynamically, resulting in 29% acceleration of the CTC model inference with minor performance degradation.
DIR-AS: Decoupling Individual Identification and Temporal Reasoning for Action Segmentation
Apr 04, 2023Fully supervised action segmentation works on frame-wise action recognition with dense annotations and often suffers from the over-segmentation issue. Existing works have proposed a variety of solutions such as boundary-aware networks, multi-stage refinement, and temporal smoothness losses. However, most of them take advantage of frame-wise supervision, which cannot effectively tackle the evaluation metrics with different granularities. In this paper, for the desirable large receptive field, we first develop a novel local-global attention mechanism with temporal pyramid dilation and temporal pyramid pooling for efficient multi-scale attention. Then we decouple two inherent goals in action segmentation, ie, (1) individual identification solved by frame-wise supervision, and (2) temporal reasoning tackled by action set prediction. Afterward, an action alignment module fuses these different granularity predictions, leading to more accurate and smoother action segmentation. We achieve state-of-the-art accuracy, eg, 82.8% (+2.6%) on GTEA and 74.7% (+1.2%) on Breakfast, which demonstrates the effectiveness of our proposed method, accompanied by extensive ablation studies. The code will be made available later.
DialAug: Mixing up Dialogue Contexts in Contrastive Learning for Robust Conversational Modeling
Apr 15, 2022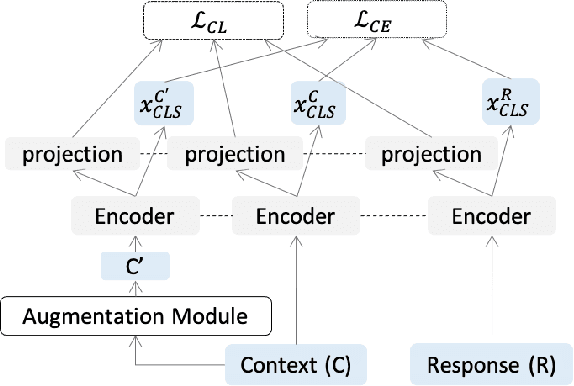
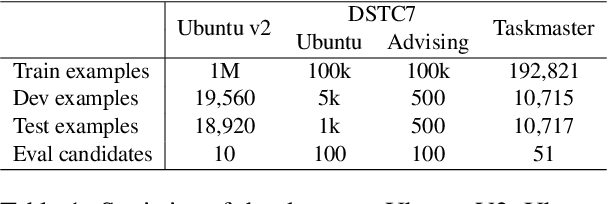

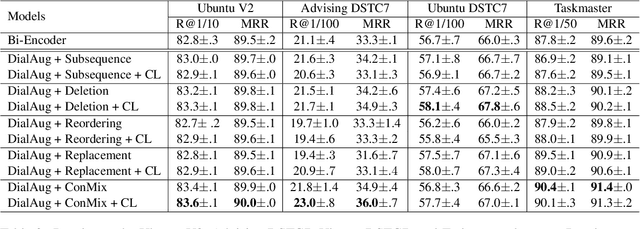
Retrieval-based conversational systems learn to rank response candidates for a given dialogue context by computing the similarity between their vector representations. However, training on a single textual form of the multi-turn context limits the ability of a model to learn representations that generalize to natural perturbations seen during inference. In this paper we propose a framework that incorporates augmented versions of a dialogue context into the learning objective. We utilize contrastive learning as an auxiliary objective to learn robust dialogue context representations that are invariant to perturbations injected through the augmentation method. We experiment with four benchmark dialogue datasets and demonstrate that our framework combines well with existing augmentation methods and can significantly improve over baseline BERT-based ranking architectures. Furthermore, we propose a novel data augmentation method, ConMix, that adds token level perturbations through stochastic mixing of tokens from other contexts in the batch. We show that our proposed augmentation method outperforms previous data augmentation approaches, and provides dialogue representations that are more robust to common perturbations seen during inference.
The RoyalFlush System of Speech Recognition for M2MeT Challenge
Feb 03, 2022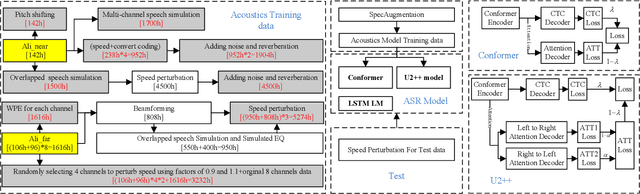
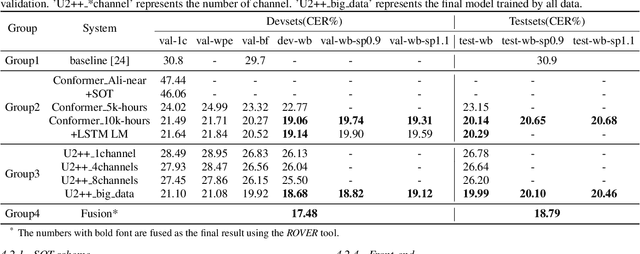
This paper describes our RoyalFlush system for the track of multi-speaker automatic speech recognition (ASR) in the M2MeT challenge. We adopted the serialized output training (SOT) based multi-speakers ASR system with large-scale simulation data. Firstly, we investigated a set of front-end methods, including multi-channel weighted predicted error (WPE), beamforming, speech separation, speech enhancement and so on, to process training, validation and test sets. But we only selected WPE and beamforming as our frontend methods according to their experimental results. Secondly, we made great efforts in the data augmentation for multi-speaker ASR, mainly including adding noise and reverberation, overlapped speech simulation, multi-channel speech simulation, speed perturbation, front-end processing, and so on, which brought us a great performance improvement. Finally, in order to make full use of the performance complementary of different model architecture, we trained the standard conformer based joint CTC/Attention (Conformer) and U2++ ASR model with a bidirectional attention decoder, a modification of Conformer, to fuse their results. Comparing with the official baseline system, our system got a 12.22% absolute Character Error Rate (CER) reduction on the validation set and 12.11% on the test set.