 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Adversarial MixUp for Few-Shot Unsupervised Domain Adaptation
Sep 03, 2023Domain shift is a common problem in clinical applications, where the training images (source domain) and the test images (target domain) are under different distributions. Unsupervised Domain Adaptation (UDA) techniques have been proposed to adapt models trained in the source domain to the target domain. However, those methods require a large number of images from the target domain for model training. In this paper, we propose a novel method for Few-Shot Unsupervised Domain Adaptation (FSUDA), where only a limited number of unlabeled target domain samples are available for training. To accomplish this challenging task, first, a spectral sensitivity map is introduced to characterize the generalization weaknesses of models in the frequency domain. We then developed a Sensitivity-guided Spectral Adversarial MixUp (SAMix) method to generate target-style images to effectively suppresses the model sensitivity, which leads to improved model generalizability in the target domain. We demonstrated the proposed method and rigorously evaluated its performance on multiple tasks using several public datasets.
Deformable Mixer Transformer with Gating for Multi-Task Learning of Dense Prediction
Aug 18, 2023



CNNs and Transformers have their own advantages and both have been widely used for dense prediction in multi-task learning (MTL). Most of the current studies on MTL solely rely on CNN or Transformer. In this work, we present a novel MTL model by combining both merits of deformable CNN and query-based Transformer with shared gating for multi-task learning of dense prediction. This combination may offer a simple and efficient solution owing to its powerful and flexible task-specific learning and advantages of lower cost, less complexity and smaller parameters than the traditional MTL methods. We introduce deformable mixer Transformer with gating (DeMTG), a simple and effective encoder-decoder architecture up-to-date that incorporates the convolution and attention mechanism in a unified network for MTL. It is exquisitely designed to use advantages of each block, and provide deformable and comprehensive features for all tasks from local and global perspective. First, the deformable mixer encoder contains two types of operators: the channel-aware mixing operator leveraged to allow communication among different channels, and the spatial-aware deformable operator with deformable convolution applied to efficiently sample more informative spatial locations. Second, the task-aware gating transformer decoder is used to perform the task-specific predictions, in which task interaction block integrated with self-attention is applied to capture task interaction features, and the task query block integrated with gating attention is leveraged to select corresponding task-specific features. Further, the experiment results demonstrate that the proposed DeMTG uses fewer GFLOPs and significantly outperforms current Transformer-based and CNN-based competitive models on a variety of metrics on three dense prediction datasets. Our code and models are available at https://github.com/yangyangxu0/DeMTG.
RIGID: Recurrent GAN Inversion and Editing of Real Face Videos
Aug 15, 2023GAN inversion is indispensable for applying the powerful editability of GAN to real images. However, existing methods invert video frames individually often leading to undesired inconsistent results over time. In this paper, we propose a unified recurrent framework, named \textbf{R}ecurrent v\textbf{I}deo \textbf{G}AN \textbf{I}nversion and e\textbf{D}iting (RIGID), to explicitly and simultaneously enforce temporally coherent GAN inversion and facial editing of real videos. Our approach models the temporal relations between current and previous frames from three aspects. To enable a faithful real video reconstruction, we first maximize the inversion fidelity and consistency by learning a temporal compensated latent code. Second, we observe incoherent noises lie in the high-frequency domain that can be disentangled from the latent space. Third, to remove the inconsistency after attribute manipulation, we propose an \textit{in-between frame composition constraint} such that the arbitrary frame must be a direct composite of its neighboring frames. Our unified framework learns the inherent coherence between input frames in an end-to-end manner, and therefore it is agnostic to a specific attribute and can be applied to arbitrary editing of the same video without re-training. Extensive experiments demonstrate that RIGID outperforms state-of-the-art methods qualitatively and quantitatively in both inversion and editing tasks. The deliverables can be found in \url{https://cnnlstm.github.io/RIGID}
Variance-reduced accelerated methods for decentralized stochastic double-regularized nonconvex strongly-concave minimax problems
Jul 14, 2023In this paper, we consider the decentralized, stochastic nonconvex strongly-concave (NCSC) minimax problem with nonsmooth regularization terms on both primal and dual variables, wherein a network of $m$ computing agents collaborate via peer-to-peer communications. We consider when the coupling function is in expectation or finite-sum form and the double regularizers are convex functions, applied separately to the primal and dual variables. Our algorithmic framework introduces a Lagrangian multiplier to eliminate the consensus constraint on the dual variable. Coupling this with variance-reduction (VR) techniques, our proposed method, entitled VRLM, by a single neighbor communication per iteration, is able to achieve an $\mathcal{O}(\kappa^3\varepsilon^{-3})$ sample complexity under the general stochastic setting, with either a big-batch or small-batch VR option, where $\kappa$ is the condition number of the problem and $\varepsilon$ is the desired solution accuracy. With a big-batch VR, we can additionally achieve $\mathcal{O}(\kappa^2\varepsilon^{-2})$ communication complexity. Under the special finite-sum setting, our method with a big-batch VR can achieve an $\mathcal{O}(n + \sqrt{n} \kappa^2\varepsilon^{-2})$ sample complexity and $\mathcal{O}(\kappa^2\varepsilon^{-2})$ communication complexity, where $n$ is the number of components in the finite sum. All complexity results match the best-known results achieved by a few existing methods for solving special cases of the problem we consider. To the best of our knowledge, this is the first work which provides convergence guarantees for NCSC minimax problems with general convex nonsmooth regularizers applied to both the primal and dual variables in the decentralized stochastic setting. Numerical experiments are conducted on two machine learning problems. Our code is downloadable from https://github.com/RPI-OPT/VRLM.
First-order Methods for Affinely Constrained Composite Non-convex Non-smooth Problems: Lower Complexity Bound and Near-optimal Methods
Jul 14, 2023Many recent studies on first-order methods (FOMs) focus on \emph{composite non-convex non-smooth} optimization with linear and/or nonlinear function constraints. Upper (or worst-case) complexity bounds have been established for these methods. However, little can be claimed about their optimality as no lower bound is known, except for a few special \emph{smooth non-convex} cases. In this paper, we make the first attempt to establish lower complexity bounds of FOMs for solving a class of composite non-convex non-smooth optimization with linear constraints. Assuming two different first-order oracles, we establish lower complexity bounds of FOMs to produce a (near) $\epsilon$-stationary point of a problem (and its reformulation) in the considered problem class, for any given tolerance $\epsilon>0$. In addition, we present an inexact proximal gradient (IPG) method by using the more relaxed one of the two assumed first-order oracles. The oracle complexity of the proposed IPG, to find a (near) $\epsilon$-stationary point of the considered problem and its reformulation, matches our established lower bounds up to a logarithmic factor. Therefore, our lower complexity bounds and the proposed IPG method are almost non-improvable.
Decentralized gradient descent maximization method for composite nonconvex strongly-concave minimax problems
Apr 05, 2023Minimax problems have recently attracted a lot of research interests. A few efforts have been made to solve decentralized nonconvex strongly-concave (NCSC) minimax-structured optimization; however, all of them focus on smooth problems with at most a constraint on the maximization variable. In this paper, we make the first attempt on solving composite NCSC minimax problems that can have convex nonsmooth terms on both minimization and maximization variables. Our algorithm is designed based on a novel reformulation of the decentralized minimax problem that introduces a multiplier to absorb the dual consensus constraint. The removal of dual consensus constraint enables the most aggressive (i.e., local maximization instead of a gradient ascent step) dual update that leads to the benefit of taking a larger primal stepsize and better complexity results. In addition, the decoupling of the nonsmoothness and consensus on the dual variable eases the analysis of a decentralized algorithm; thus our reformulation creates a new way for interested researchers to design new (and possibly more efficient) decentralized methods on solving NCSC minimax problems. We show a global convergence result of the proposed algorithm and an iteration complexity result to produce a (near) stationary point of the reformulation. Moreover, a relation is established between the (near) stationarities of the reformulation and the original formulation. With this relation, we show that when the dual regularizer is smooth, our algorithm can have lower complexity results (with reduced dependence on a condition number) than existing ones to produce a near-stationary point of the original formulation. Numerical experiments are conducted on a distributionally robust logistic regression to demonstrate the performance of the proposed algorithm.
DeMT: Deformable Mixer Transformer for Multi-Task Learning of Dense Prediction
Jan 12, 2023Convolution neural networks (CNNs) and Transformers have their own advantages and both have been widely used for dense prediction in multi-task learning (MTL). Most of the current studies on MTL solely rely on CNN or Transformer. In this work, we present a novel MTL model by combining both merits of deformable CNN and query-based Transformer for multi-task learning of dense prediction. Our method, named DeMT, is based on a simple and effective encoder-decoder architecture (i.e., deformable mixer encoder and task-aware transformer decoder). First, the deformable mixer encoder contains two types of operators: the channel-aware mixing operator leveraged to allow communication among different channels ($i.e.,$ efficient channel location mixing), and the spatial-aware deformable operator with deformable convolution applied to efficiently sample more informative spatial locations (i.e., deformed features). Second, the task-aware transformer decoder consists of the task interaction block and task query block. The former is applied to capture task interaction features via self-attention. The latter leverages the deformed features and task-interacted features to generate the corresponding task-specific feature through a query-based Transformer for corresponding task predictions. Extensive experiments on two dense image prediction datasets, NYUD-v2 and PASCAL-Context, demonstrate that our model uses fewer GFLOPs and significantly outperforms current Transformer- and CNN-based competitive models on a variety of metrics. The code are available at https://github.com/yangyangxu0/DeMT .
Stochastic Inexact Augmented Lagrangian Method for Nonconvex Expectation Constrained Optimization
Dec 19, 2022



Many real-world problems not only have complicated nonconvex functional constraints but also use a large number of data points. This motivates the design of efficient stochastic methods on finite-sum or expectation constrained problems. In this paper, we design and analyze stochastic inexact augmented Lagrangian methods (Stoc-iALM) to solve problems involving a nonconvex composite (i.e. smooth+nonsmooth) objective and nonconvex smooth functional constraints. We adopt the standard iALM framework and design a subroutine by using the momentum-based variance-reduced proximal stochastic gradient method (PStorm) and a postprocessing step. Under certain regularity conditions (assumed also in existing works), to reach an $\varepsilon$-KKT point in expectation, we establish an oracle complexity result of $O(\varepsilon^{-5})$, which is better than the best-known $O(\varepsilon^{-6})$ result. Numerical experiments on the fairness constrained problem and the Neyman-Pearson classification problem with real data demonstrate that our proposed method outperforms an existing method with the previously best-known complexity result.
When Neural Networks Fail to Generalize? A Model Sensitivity Perspective
Dec 01, 2022Domain generalization (DG) aims to train a model to perform well in unseen domains under different distributions. This paper considers a more realistic yet more challenging scenario,namely Single Domain Generalization (Single-DG), where only a single source domain is available for training. To tackle this challenge, we first try to understand when neural networks fail to generalize? We empirically ascertain a property of a model that correlates strongly with its generalization that we coin as "model sensitivity". Based on our analysis, we propose a novel strategy of Spectral Adversarial Data Augmentation (SADA) to generate augmented images targeted at the highly sensitive frequencies. Models trained with these hard-to-learn samples can effectively suppress the sensitivity in the frequency space, which leads to improved generalization performance. Extensive experiments on multiple public datasets demonstrate the superiority of our approach, which surpasses the state-of-the-art single-DG methods.
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 12, 2022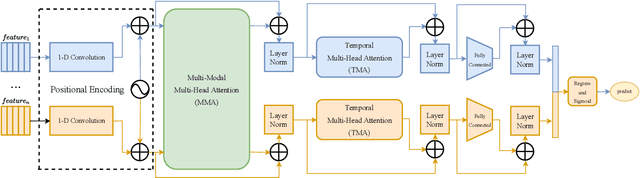
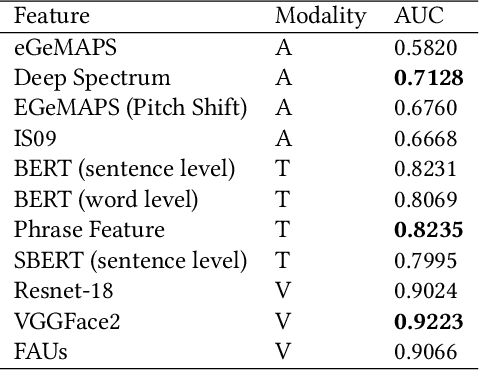
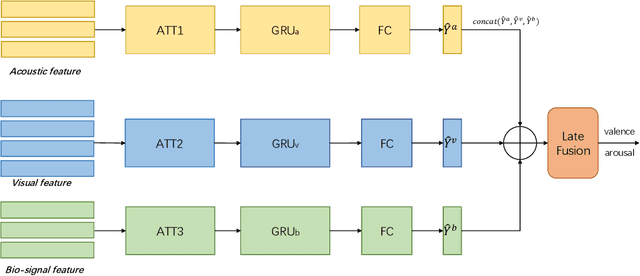
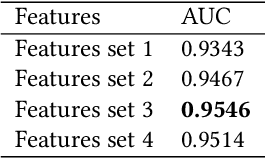
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilizing different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability of multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model from learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.