 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKatyusha Acceleration for Convex Finite-Sum Compositional Optimization
Paper and Code
Oct 24, 2019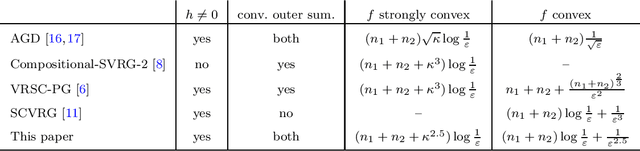

Structured problems arise in many applications. To solve these problems, it is important to leverage the structure information. This paper focuses on convex problems with a finite-sum compositional structure. Finite-sum problems appear as the sample average approximation of a stochastic optimization problem and also arise in machine learning with a huge amount of training data. One popularly used numerical approach for finite-sum problems is the stochastic gradient method (SGM). However, the additional compositional structure prohibits easy access to unbiased stochastic approximation of the gradient, so directly applying the SGM to a finite-sum compositional optimization problem (COP) is often inefficient. We design new algorithms for solving strongly-convex and also convex two-level finite-sum COPs. Our design incorporates the Katyusha acceleration technique and adopts the mini-batch sampling from both outer-level and inner-level finite-sum. We first analyze the algorithm for strongly-convex finite-sum COPs. Similar to a few existing works, we obtain linear convergence rate in terms of the expected objective error, and from the convergence rate result, we then establish complexity results of the algorithm to produce an $\varepsilon$-solution. Our complexity results have the same dependence on the number of component functions as existing works. However, due to the use of Katyusha acceleration, our results have better dependence on the condition number $\kappa$ and improve to $\kappa^{2.5}$ from the best-known $\kappa^3$. Finally, we analyze the algorithm for convex finite-sum COPs, which uses as a subroutine the algorithm for strongly-convex finite-sum COPs. Again, we obtain better complexity results than existing works in terms of the dependence on $\varepsilon$, improving to $\varepsilon^{-2.5}$ from the best-known $\varepsilon^{-3}$.