 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Deeper with Convolutions
Sep 17, 2014
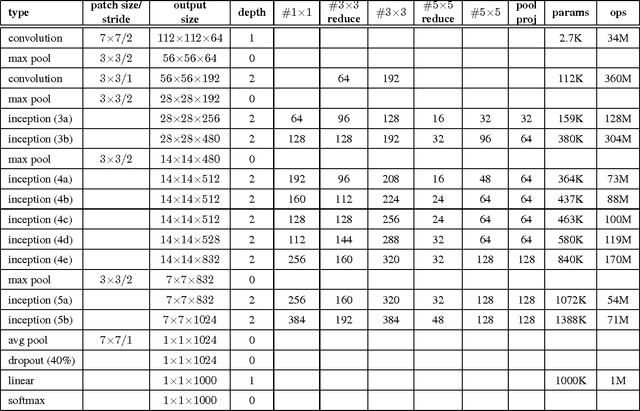
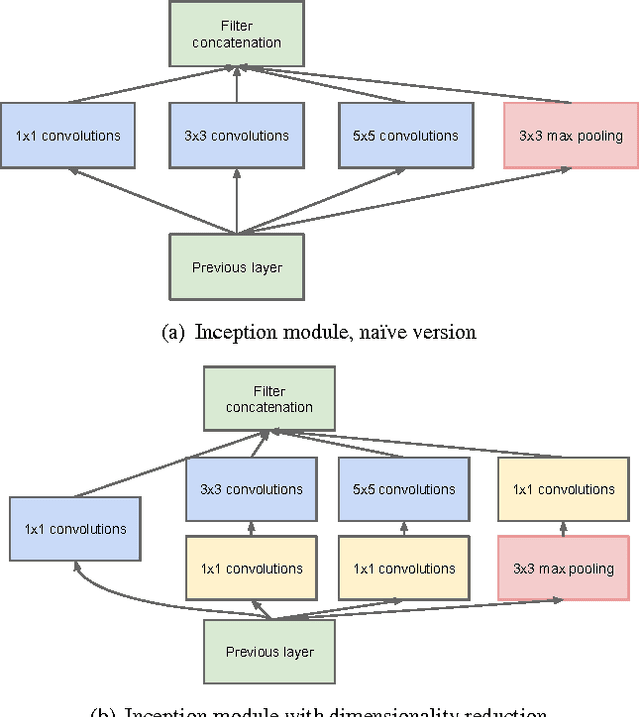
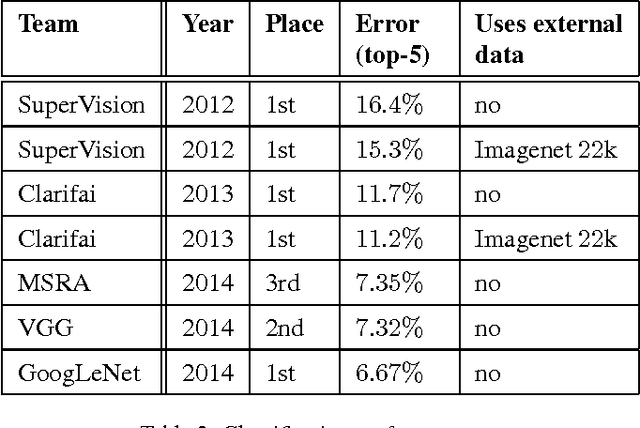
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC 2014 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
Caffe: Convolutional Architecture for Fast Feature Embedding
Jun 20, 2014

Caffe provides multimedia scientists and practitioners with a clean and modifiable framework for state-of-the-art deep learning algorithms and a collection of reference models. The framework is a BSD-licensed C++ library with Python and MATLAB bindings for training and deploying general-purpose convolutional neural networks and other deep models efficiently on commodity architectures. Caffe fits industry and internet-scale media needs by CUDA GPU computation, processing over 40 million images a day on a single K40 or Titan GPU ($\approx$ 2.5 ms per image). By separating model representation from actual implementation, Caffe allows experimentation and seamless switching among platforms for ease of development and deployment from prototyping machines to cloud environments. Caffe is maintained and developed by the Berkeley Vision and Learning Center (BVLC) with the help of an active community of contributors on GitHub. It powers ongoing research projects, large-scale industrial applications, and startup prototypes in vision, speech, and multimedia.
Deep Convolutional Ranking for Multilabel Image Annotation
Apr 14, 2014


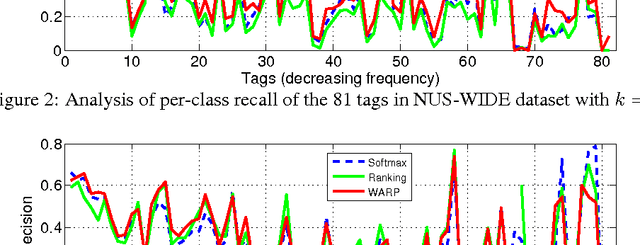
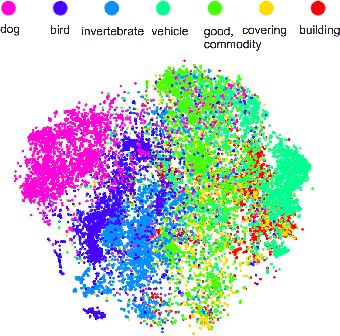
Multilabel image annotation is one of the most important challenges in computer vision with many real-world applications. While existing work usually use conventional visual features for multilabel annotation, features based on Deep Neural Networks have shown potential to significantly boost performance. In this work, we propose to leverage the advantage of such features and analyze key components that lead to better performances. Specifically, we show that a significant performance gain could be obtained by combining convolutional architectures with approximate top-$k$ ranking objectives, as thye naturally fit the multilabel tagging problem. Our experiments on the NUS-WIDE dataset outperforms the conventional visual features by about 10%, obtaining the best reported performance in the literature.
One-Shot Adaptation of Supervised Deep Convolutional Models
Feb 18, 2014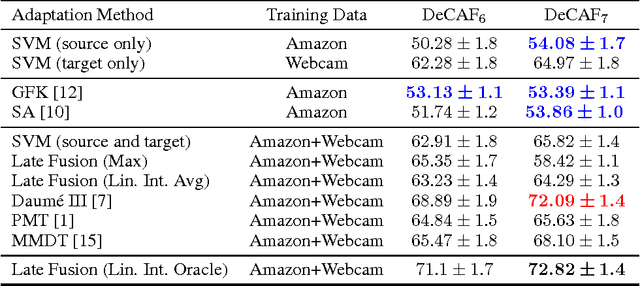
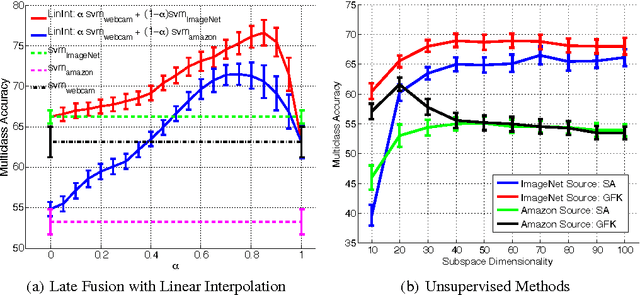
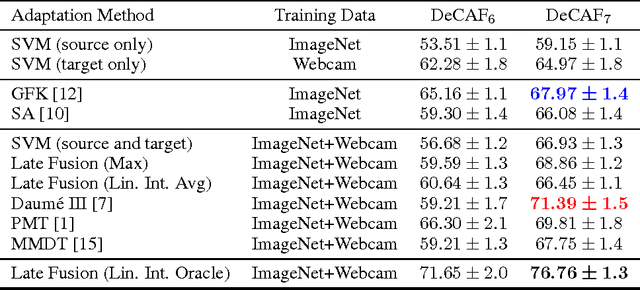
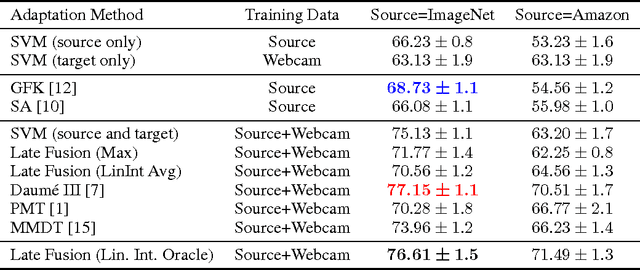
Dataset bias remains a significant barrier towards solving real world computer vision tasks. Though deep convolutional networks have proven to be a competitive approach for image classification, a question remains: have these models have solved the dataset bias problem? In general, training or fine-tuning a state-of-the-art deep model on a new domain requires a significant amount of data, which for many applications is simply not available. Transfer of models directly to new domains without adaptation has historically led to poor recognition performance. In this paper, we pose the following question: is a single image dataset, much larger than previously explored for adaptation, comprehensive enough to learn general deep models that may be effectively applied to new image domains? In other words, are deep CNNs trained on large amounts of labeled data as susceptible to dataset bias as previous methods have been shown to be? We show that a generic supervised deep CNN model trained on a large dataset reduces, but does not remove, dataset bias. Furthermore, we propose several methods for adaptation with deep models that are able to operate with little (one example per category) or no labeled domain specific data. Our experiments show that adaptation of deep models on benchmark visual domain adaptation datasets can provide a significant performance boost.
DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
Oct 06, 2013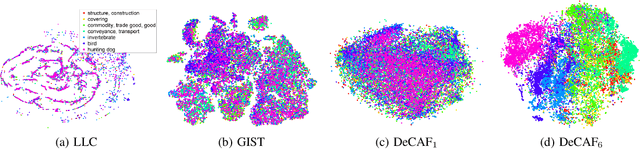
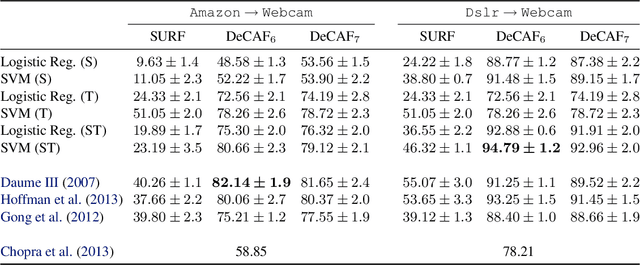
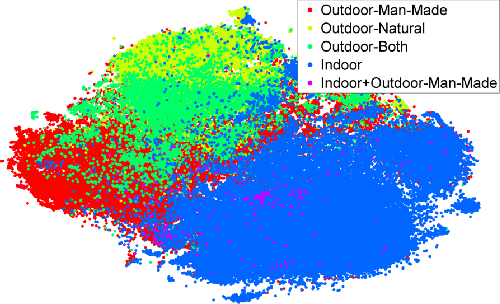

We evaluate whether features extracted from the activation of a deep convolutional network trained in a fully supervised fashion on a large, fixed set of object recognition tasks can be re-purposed to novel generic tasks. Our generic tasks may differ significantly from the originally trained tasks and there may be insufficient labeled or unlabeled data to conventionally train or adapt a deep architecture to the new tasks. We investigate and visualize the semantic clustering of deep convolutional features with respect to a variety of such tasks, including scene recognition, domain adaptation, and fine-grained recognition challenges. We compare the efficacy of relying on various network levels to define a fixed feature, and report novel results that significantly outperform the state-of-the-art on several important vision challenges. We are releasing DeCAF, an open-source implementation of these deep convolutional activation features, along with all associated network parameters to enable vision researchers to be able to conduct experimentation with deep representations across a range of visual concept learning paradigms.
Why Size Matters: Feature Coding as Nystrom Sampling
Apr 16, 2013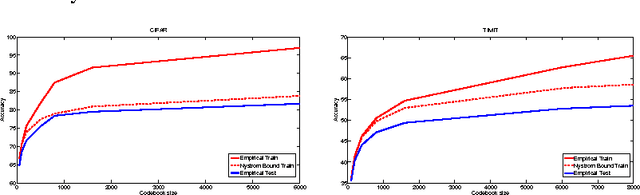
Recently, the computer vision and machine learning community has been in favor of feature extraction pipelines that rely on a coding step followed by a linear classifier, due to their overall simplicity, well understood properties of linear classifiers, and their computational efficiency. In this paper we propose a novel view of this pipeline based on kernel methods and Nystrom sampling. In particular, we focus on the coding of a data point with a local representation based on a dictionary with fewer elements than the number of data points, and view it as an approximation to the actual function that would compute pair-wise similarity to all data points (often too many to compute in practice), followed by a Nystrom sampling step to select a subset of all data points. Furthermore, since bounds are known on the approximation power of Nystrom sampling as a function of how many samples (i.e. dictionary size) we consider, we can derive bounds on the approximation of the exact (but expensive to compute) kernel matrix, and use it as a proxy to predict accuracy as a function of the dictionary size, which has been observed to increase but also to saturate as we increase its size. This model may help explaining the positive effect of the codebook size and justifying the need to stack more layers (often referred to as deep learning), as flat models empirically saturate as we add more complexity.
Pooling-Invariant Image Feature Learning
Jan 15, 2013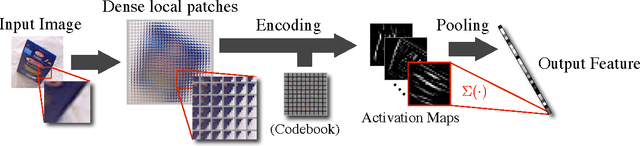
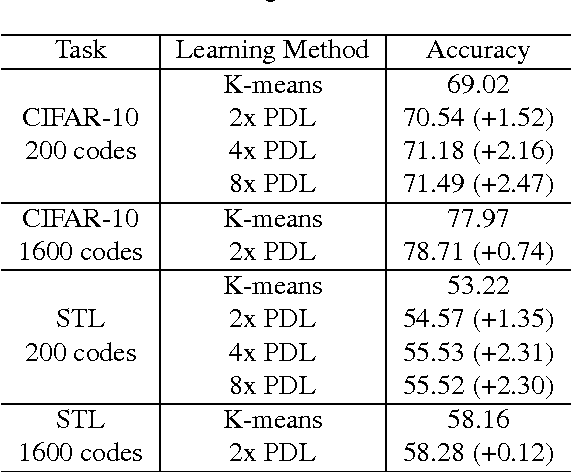
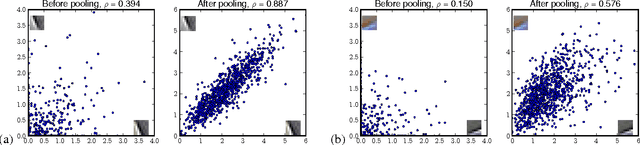
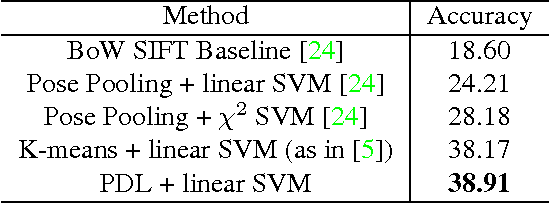
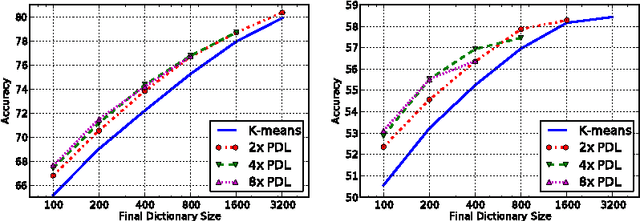
Unsupervised dictionary learning has been a key component in state-of-the-art computer vision recognition architectures. While highly effective methods exist for patch-based dictionary learning, these methods may learn redundant features after the pooling stage in a given early vision architecture. In this paper, we offer a novel dictionary learning scheme to efficiently take into account the invariance of learned features after the spatial pooling stage. The algorithm is built on simple clustering, and thus enjoys efficiency and scalability. We discuss the underlying mechanism that justifies the use of clustering algorithms, and empirically show that the algorithm finds better dictionaries than patch-based methods with the same dictionary size.
Factorized Multi-Modal Topic Model
Oct 16, 2012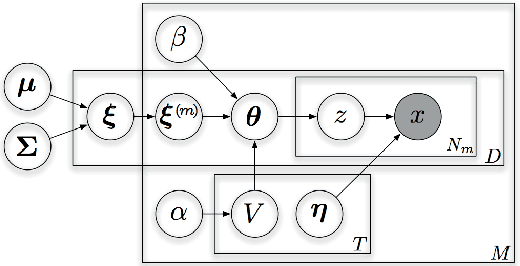

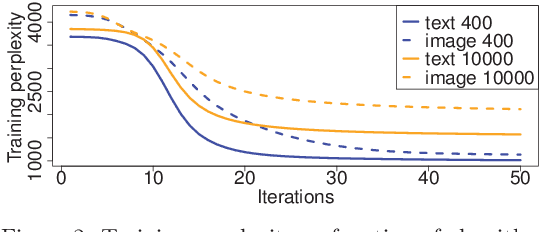
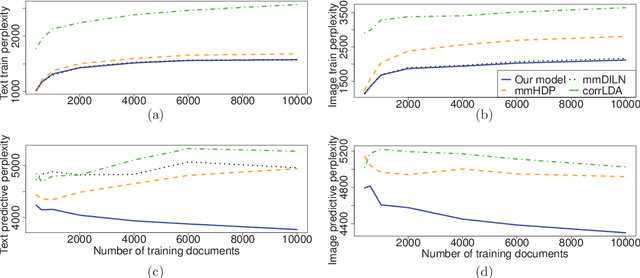
Multi-modal data collections, such as corpora of paired images and text snippets, require analysis methods beyond single-view component and topic models. For continuous observations the current dominant approach is based on extensions of canonical correlation analysis, factorizing the variation into components shared by the different modalities and those private to each of them. For count data, multiple variants of topic models attempting to tie the modalities together have been presented. All of these, however, lack the ability to learn components private to one modality, and consequently will try to force dependencies even between minimally correlating modalities. In this work we combine the two approaches by presenting a novel HDP-based topic model that automatically learns both shared and private topics. The model is shown to be especially useful for querying the contents of one domain given samples of the other.