 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping to Mitigate Reward Hacking in RLHF
Feb 26, 2025Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human values. However, RLHF is susceptible to reward hacking, where the agent exploits flaws in the reward function rather than learning the intended behavior, thus degrading alignment. While reward shaping helps stabilize RLHF and partially mitigate reward hacking, a systematic investigation into shaping techniques and their underlying principles remains lacking. To bridge this gap, we present a comprehensive study of the prevalent reward shaping methods. Our analysis suggests three key design principles: (1) RL reward is ideally bounded, (2) RL benefits from rapid initial growth followed by gradual convergence, and (3) RL reward is best formulated as a function of centered reward. Guided by these insights, we propose Preference As Reward (PAR), a novel approach that leverages the latent preferences embedded within the reward model itself as the signal for reinforcement learning. We evaluated PAR on two base models, Gemma2-2B and Llama3-8B, using two datasets, Ultrafeedback-Binarized and HH-RLHF. Experimental results demonstrate PAR's superior performance over other reward shaping methods. On the AlpacaEval 2.0 benchmark, PAR achieves a win rate at least 5 percentage points higher than competing approaches. Furthermore, PAR exhibits remarkable data efficiency, requiring only a single reference reward for optimal performance, and maintains robustness against reward hacking even after two full epochs of training. Code is available at https://github.com/PorUna-byte/PAR.
Order Matters: Investigate the Position Bias in Multi-constraint Instruction Following
Feb 24, 2025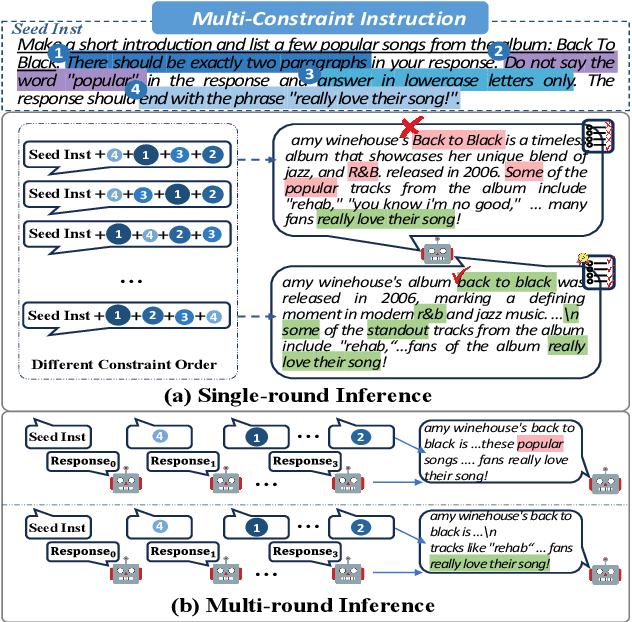
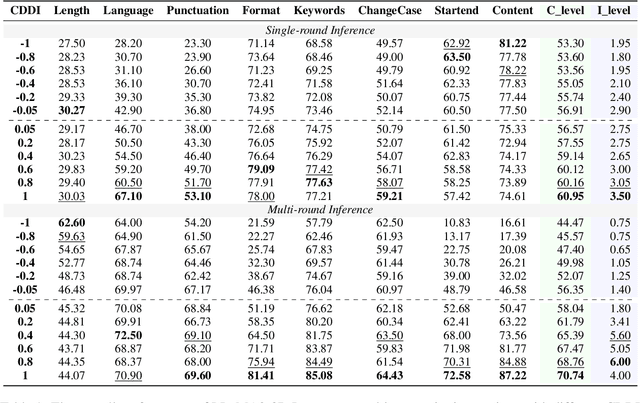
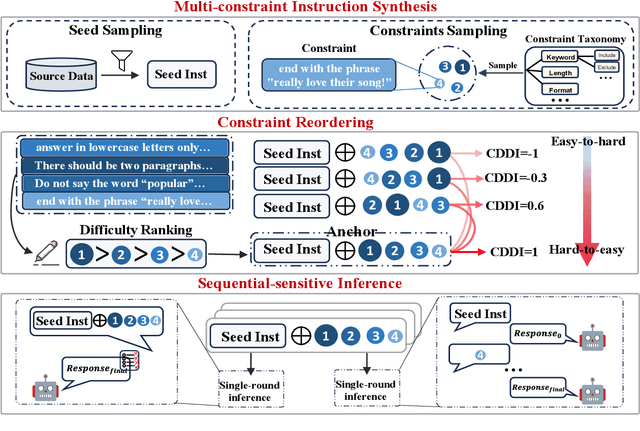

Real-world instructions with multiple constraints pose a significant challenge to existing large language models (LLMs). An observation is that the LLMs exhibit dramatic performance fluctuation when disturbing the order of the incorporated constraints. Yet, none of the existing works has systematically investigated this position bias problem in the field of multi-constraint instruction following. To bridge this gap, we design a probing task where we quantitatively measure the difficulty distribution of the constraints by a novel Difficulty Distribution Index (CDDI). Through the experimental results, we find that LLMs are more performant when presented with the constraints in a ``hard-to-easy'' order. This preference can be generalized to LLMs with different architecture or different sizes of parameters. Additionally, we conduct an explanation study, providing an intuitive insight into the correlation between the LLM's attention and constraint orders. Our code and dataset are publicly available at https://github.com/meowpass/PBIF.
CoSER: Coordinating LLM-Based Persona Simulation of Established Roles
Feb 13, 2025Role-playing language agents (RPLAs) have emerged as promising applications of large language models (LLMs). However, simulating established characters presents a challenging task for RPLAs, due to the lack of authentic character datasets and nuanced evaluation methods using such data. In this paper, we present CoSER, a collection of a high-quality dataset, open models, and an evaluation protocol towards effective RPLAs of established characters. The CoSER dataset covers 17,966 characters from 771 renowned books. It provides authentic dialogues with real-world intricacies, as well as diverse data types such as conversation setups, character experiences and internal thoughts. Drawing from acting methodology, we introduce given-circumstance acting for training and evaluating role-playing LLMs, where LLMs sequentially portray multiple characters in book scenes. Using our dataset, we develop CoSER 8B and CoSER 70B, i.e., advanced open role-playing LLMs built on LLaMA-3.1 models. Extensive experiments demonstrate the value of the CoSER dataset for RPLA training, evaluation and retrieval. Moreover, CoSER 70B exhibits state-of-the-art performance surpassing or matching GPT-4o on our evaluation and three existing benchmarks, i.e., achieving 75.80% and 93.47% accuracy on the InCharacter and LifeChoice benchmarks respectively.
AdaptiveLog: An Adaptive Log Analysis Framework with the Collaboration of Large and Small Language Model
Jan 19, 2025



Automated log analysis is crucial to ensure high availability and reliability of complex systems. The advent of LLMs in NLP has ushered in a new era of language model-driven automated log analysis, garnering significant interest. Within this field, two primary paradigms based on language models for log analysis have become prominent. Small Language Models (SLMs) follow the pre-train and fine-tune paradigm, focusing on the specific log analysis task through fine-tuning on supervised datasets. On the other hand, LLMs following the in-context learning paradigm, analyze logs by providing a few examples in prompt contexts without updating parameters. Despite their respective strengths, we notice that SLMs are more cost-effective but less powerful, whereas LLMs with large parameters are highly powerful but expensive and inefficient. To trade-off between the performance and inference costs of both models in automated log analysis, this paper introduces an adaptive log analysis framework known as AdaptiveLog, which effectively reduces the costs associated with LLM while ensuring superior results. This framework collaborates an LLM and a small language model, strategically allocating the LLM to tackle complex logs while delegating simpler logs to the SLM. Specifically, to efficiently query the LLM, we propose an adaptive selection strategy based on the uncertainty estimation of the SLM, where the LLM is invoked only when the SLM is uncertain. In addition, to enhance the reasoning ability of the LLM in log analysis tasks, we propose a novel prompt strategy by retrieving similar error-prone cases as the reference, enabling the model to leverage past error experiences and learn solutions from these cases. Extensive experiments demonstrate that AdaptiveLog achieves state-of-the-art results across different tasks, elevating the overall accuracy of log analysis while maintaining cost efficiency.
CDS: Data Synthesis Method Guided by Cognitive Diagnosis Theory
Jan 13, 2025



Large Language Models (LLMs) have demonstrated outstanding capabilities across various domains, but the increasing complexity of new challenges demands enhanced performance and adaptability. Traditional benchmarks, although comprehensive, often lack the granularity needed for detailed capability analysis. This study introduces the Cognitive Diagnostic Synthesis (CDS) method, which employs Cognitive Diagnosis Theory (CDT) for precise evaluation and targeted enhancement of LLMs. By decomposing complex tasks into discrete knowledge points, CDS accurately identifies and synthesizes data targeting model weaknesses, thereby enhancing the model's performance. This framework proposes a comprehensive pipeline driven by knowledge point evaluation, synthesis, data augmentation, and filtering, which significantly improves the model's mathematical and coding capabilities, achieving up to an 11.12% improvement in optimal scenarios.
Step-by-Step Mastery: Enhancing Soft Constraint Following Ability of Large Language Models
Jan 09, 2025It is crucial for large language models (LLMs) to follow instructions that involve multiple constraints. However, soft constraints are semantically related and difficult to verify through automated methods. These constraints remain a significant challenge for LLMs. To enhance the ability of LLMs to follow soft constraints, we initially design a pipeline to obtain high-quality outputs automatically. Additionally, to fully utilize the acquired data, we introduce a training paradigm based on curriculum learning. We experimentally evaluate the effectiveness of our methods in improving LLMs' soft constraint following ability and analyze the factors driving the improvements. The datasets and code are publicly available at https://github.com/Rainier-rq/FollowSoftConstraints.
MultiLingPoT: Enhancing Mathematical Reasoning with Multilingual Program Fine-tuning
Dec 17, 2024



Program-of-Thought (PoT), which aims to use programming language instead of natural language as an intermediate step in reasoning, is an important way for LLMs to solve mathematical problems. Since different programming languages excel in different areas, it is natural to use the most suitable language for solving specific problems. However, current PoT research only focuses on single language PoT, ignoring the differences between different programming languages. Therefore, this paper proposes an multilingual program reasoning method, MultiLingPoT. This method allows the model to answer questions using multiple programming languages by fine-tuning on multilingual data. Additionally, prior and posterior hybrid methods are used to help the model select the most suitable language for each problem. Our experimental results show that the training of MultiLingPoT improves each program's mathematical reasoning by about 2.5\%. Moreover, with proper mixing, the performance of MultiLingPoT can be further improved, achieving a 6\% increase compared to the single-language PoT with the data augmentation.Resources of this paper can be found at https://github.com/Nianqi-Li/MultiLingPoT.
Fast and Robust Contextual Node Representation Learning over Dynamic Graphs
Nov 11, 2024



Real-world graphs grow rapidly with edge and vertex insertions over time, motivating the problem of efficiently maintaining robust node representation over evolving graphs. Recent efficient GNNs are designed to decouple recursive message passing from the learning process, and favor Personalized PageRank (PPR) as the underlying feature propagation mechanism. However, most PPR-based GNNs are designed for static graphs, and efficient PPR maintenance remains as an open problem. Further, there is surprisingly little theoretical justification for the choice of PPR, despite its impressive empirical performance. In this paper, we are inspired by the recent PPR formulation as an explicit $\ell_1$-regularized optimization problem and propose a unified dynamic graph learning framework based on sparse node-wise attention. We also present a set of desired properties to justify the choice of PPR in STOA GNNs, and serves as the guideline for future node attention designs. Meanwhile, we take advantage of the PPR-equivalent optimization formulation and employ the proximal gradient method (ISTA) to improve the efficiency of PPR-based GNNs upto 6 times. Finally, we instantiate a simple-yet-effective model (\textsc{GoPPE}) with robust positional encodings by maximizing PPR previously used as attention. The model performs comparably to or better than the STOA baselines and greatly outperforms when the initial node attributes are noisy during graph evolution, demonstrating the effectiveness and robustness of \textsc{GoPPE}.
QUILL: Quotation Generation Enhancement of Large Language Models
Nov 06, 2024



While Large language models (LLMs) have become excellent writing assistants, they still struggle with quotation generation. This is because they either hallucinate when providing factual quotations or fail to provide quotes that exceed human expectations. To bridge the gap, we systematically study how to evaluate and improve LLMs' performance in quotation generation tasks. We first establish a holistic and automatic evaluation system for quotation generation task, which consists of five criteria each with corresponding automatic metric. To improve the LLMs' quotation generation abilities, we construct a bilingual knowledge base that is broad in scope and rich in dimensions, containing up to 32,022 quotes. Moreover, guided by our critiria, we further design a quotation-specific metric to rerank the retrieved quotations from the knowledge base. Extensive experiments show that our metrics strongly correlate with human preferences. Existing LLMs struggle to generate desired quotes, but our quotation knowledge base and reranking metric help narrow this gap. Our dataset and code are publicly available at https://github.com/GraceXiaoo/QUILL.
Faster Local Solvers for Graph Diffusion Equations
Oct 29, 2024



Efficient computation of graph diffusion equations (GDEs), such as Personalized PageRank, Katz centrality, and the Heat kernel, is crucial for clustering, training neural networks, and many other graph-related problems. Standard iterative methods require accessing the whole graph per iteration, making them time-consuming for large-scale graphs. While existing local solvers approximate diffusion vectors through heuristic local updates, they often operate sequentially and are typically designed for specific diffusion types, limiting their applicability. Given that diffusion vectors are highly localizable, as measured by the participation ratio, this paper introduces a novel framework for approximately solving GDEs using a local diffusion process. This framework reveals the suboptimality of existing local solvers. Furthermore, our approach effectively localizes standard iterative solvers by designing simple and provably sublinear time algorithms. These new local solvers are highly parallelizable, making them well-suited for implementation on GPUs. We demonstrate the effectiveness of our framework in quickly obtaining approximate diffusion vectors, achieving up to a hundred-fold speed improvement, and its applicability to large-scale dynamic graphs. Our framework could also facilitate more efficient local message-passing mechanisms for GNNs.