 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025



Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025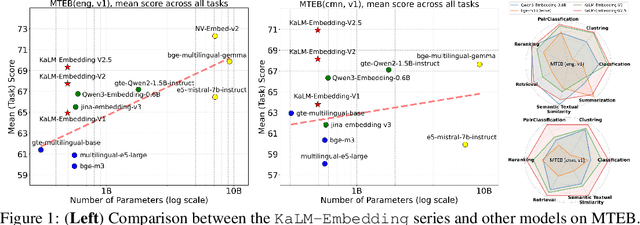
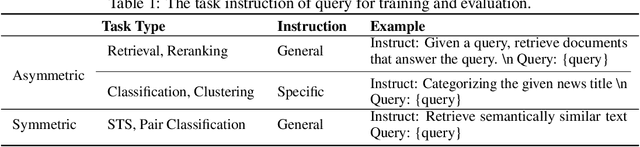

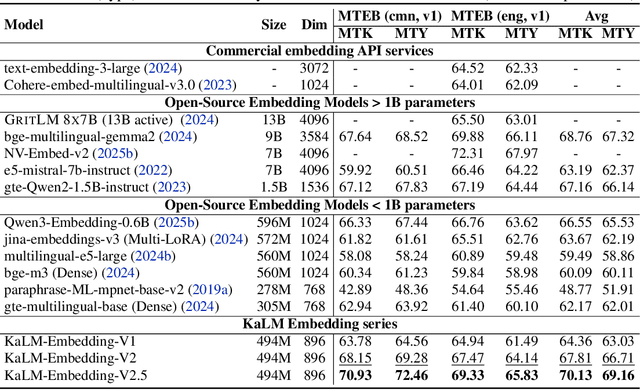
In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
XBOUND: Exploring the Capability Boundaries of Device-Control Agents through Trajectory Tree Exploration
May 27, 2025Recent advancements in vision-language models (VLMs) have spurred increased interest in Device-Control Agents (DC agents), such as utilizing in-the-wild device control to manage graphical user interfaces. Conventional methods for assessing the capabilities of DC agents, such as computing step-wise action accuracy and overall task success rates, provide a macroscopic view of DC agents' performance; however, they fail to offer microscopic insights into potential errors that may occur in real-world applications. Conducting a finer-grained performance evaluation of DC agents presents significant challenges. This study introduces a new perspective on evaluation methods for DC agents by proposing the XBOUND evaluation method, which employs the calculation of a novel Explore Metric to delineate the capability boundaries of DC agents. Compared to previous evaluation methods, XBOUND focuses on individual states to assess the proficiency of DC agents in mastering these states. Furthermore, we have developed a ``pseudo'' episode tree dataset derived from Android Control test data. Utilizing this dataset and XBOUND, we comprehensively evaluate the OS-Atlas and UI-TARS series, examining both the overall and specific performance across five common tasks. Additionally, we select representative cases to highlight the current deficiencies and limitations inherent in both series. Code is available at https://github.com/sqzhang-lazy/XBOUND.
Evaluating and Steering Modality Preferences in Multimodal Large Language Model
May 27, 2025Multimodal large language models (MLLMs) have achieved remarkable performance on complex tasks with multimodal context. However, it is still understudied whether they exhibit modality preference when processing multimodal contexts. To study this question, we first build a \textbf{MC\textsuperscript{2}} benchmark under controlled evidence conflict scenarios to systematically evaluate modality preference, which is the tendency to favor one modality over another when making decisions based on multimodal conflicting evidence. Our extensive evaluation reveals that all 18 tested MLLMs generally demonstrate clear modality bias, and modality preference can be influenced by external interventions. An in-depth analysis reveals that the preference direction can be captured within the latent representations of MLLMs. Built on this, we propose a probing and steering method based on representation engineering to explicitly control modality preference without additional fine-tuning or carefully crafted prompts. Our method effectively amplifies modality preference toward a desired direction and applies to downstream tasks such as hallucination mitigation and multimodal machine translation, yielding promising improvements.
Enhancing Generalization of Speech Large Language Models with Multi-Task Behavior Imitation and Speech-Text Interleaving
May 24, 2025Large language models (LLMs) have shown remarkable generalization across tasks, leading to increased interest in integrating speech with LLMs. These speech LLMs (SLLMs) typically use supervised fine-tuning to align speech with text-based LLMs. However, the lack of annotated speech data across a wide range of tasks hinders alignment efficiency, resulting in poor generalization. To address these issues, we propose a novel multi-task 'behavior imitation' method with speech-text interleaving, called MTBI, which relies solely on paired speech and transcripts. By ensuring the LLM decoder generates equivalent responses to paired speech and text, we achieve a more generalized SLLM. Interleaving is used to further enhance alignment efficiency. We introduce a simple benchmark to evaluate prompt and task generalization across different models. Experimental results demonstrate that our MTBI outperforms SOTA SLLMs on both prompt and task generalization, while requiring less supervised speech data.
A Semantic Information-based Hierarchical Speech Enhancement Method Using Factorized Codec and Diffusion Model
May 20, 2025Most current speech enhancement (SE) methods recover clean speech from noisy inputs by directly estimating time-frequency masks or spectrums. However, these approaches often neglect the distinct attributes, such as semantic content and acoustic details, inherent in speech signals, which can hinder performance in downstream tasks. Moreover, their effectiveness tends to degrade in complex acoustic environments. To overcome these challenges, we propose a novel, semantic information-based, step-by-step factorized SE method using factorized codec and diffusion model. Unlike traditional SE methods, our hierarchical modeling of semantic and acoustic attributes enables more robust clean speech recovery, particularly in challenging acoustic scenarios. Moreover, this method offers further advantages for downstream TTS tasks. Experimental results demonstrate that our algorithm not only outperforms SOTA baselines in terms of speech quality but also enhances TTS performance in noisy environments.
ProjectEval: A Benchmark for Programming Agents Automated Evaluation on Project-Level Code Generation
Mar 10, 2025



Recently, LLM agents have made rapid progress in improving their programming capabilities. However, existing benchmarks lack the ability to automatically evaluate from users' perspective, and also lack the explainability of the results of LLM agents' code generation capabilities. Thus, we introduce ProjectEval, a new benchmark for LLM agents project-level code generation's automated evaluation by simulating user interaction. ProjectEval is constructed by LLM with human reviewing. It has three different level inputs of natural languages or code skeletons. ProjectEval can evaluate the generated projects by user interaction simulation for execution, and by code similarity through existing objective indicators. Through ProjectEval, we find that systematic engineering project code, overall understanding of the project and comprehensive analysis capability are the keys for LLM agents to achieve practical projects. Our findings and benchmark provide valuable insights for developing more effective programming agents that can be deployed in future real-world production.
ASurvey: Spatiotemporal Consistency in Video Generation
Feb 25, 2025Video generation, by leveraging a dynamic visual generation method, pushes the boundaries of Artificial Intelligence Generated Content (AIGC). Video generation presents unique challenges beyond static image generation, requiring both high-quality individual frames and temporal coherence to maintain consistency across the spatiotemporal sequence. Recent works have aimed at addressing the spatiotemporal consistency issue in video generation, while few literature review has been organized from this perspective. This gap hinders a deeper understanding of the underlying mechanisms for high-quality video generation. In this survey, we systematically review the recent advances in video generation, covering five key aspects: foundation models, information representations, generation schemes, post-processing techniques, and evaluation metrics. We particularly focus on their contributions to maintaining spatiotemporal consistency. Finally, we discuss the future directions and challenges in this field, hoping to inspire further efforts to advance the development of video generation.
Exploiting Epistemic Uncertainty in Cold-Start Recommendation Systems
Feb 22, 2025


The cold-start problem remains a significant challenge in recommendation systems based on generative models. Current methods primarily focus on enriching embeddings or inputs by gathering more data, often overlooking the effectiveness of how existing training knowledge is utilized. This inefficiency can lead to missed opportunities for improving cold-start recommendations. To address this, we propose the use of epistemic uncertainty, which reflects a lack of certainty about the optimal model, as a tool to measure and enhance the efficiency with which a recommendation system leverages available knowledge. By considering epistemic uncertainty as a reducible component of overall uncertainty, we introduce a new approach to refine model performance. The effectiveness of this approach is validated through extensive offline experiments on publicly available datasets, demonstrating its superior performance and robustness in tackling the cold-start problem.
Learning-based A Posteriori Speech Presence Probability Estimation and Applications
Jan 23, 2025



The a posteriori speech presence probability (SPP) is the fundamental component of noise power spectral density (PSD) estimation, which can contribute to speech enhancement and speech recognition systems. Most existing SPP estimators can estimate SPP accurately from the background noise. Nevertheless, numerous challenges persist, including the difficulty of accurately estimating SPP from non-stationary noise with statistics-based methods and the high latency associated with deep learning-based approaches. This paper presents an improved SPP estimation approach based on deep learning to achieve higher SPP estimation accuracy, especially in non-stationary noise conditions. To promote the information extraction performance of the DNN, the global information of the observed signal and the local information of the decoupled frequency bins from the observed signal are connected as hybrid global-local information. The global information is extracted by one encoder. Then, one decoder and two fully connected layers are used to estimate SPP from the information of residual connection. To evaluate the performance of our proposed SPP estimator, the noise PSD estimation and speech enhancement tasks are performed. In contrast to existing minimum mean-square error (MMSE)-based noise PSD estimation approaches, the noise PSD is estimated by the sub-optimal MMSE based on the current frame SPP estimate without smoothing. Directed by the noise PSD estimate, a standard speech enhancement framework, the log spectral amplitude estimator, is employed to extract clean speech from the observed signal. From the experimental results, we can confirm that our proposed SPP estimator can achieve high noise PSD estimation accuracy and speech enhancement performance while requiring low model complexity.