 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Object Pose Connectivity Metrics for Regrasp Sequence Optimization
Apr 16, 2026Regrasp planning is often required when one pick-and-place cannot transfer an object from an initial pose to a goal pose while maintaining grasp feasibility. The main challenge is to reason about shared-grasp connectivity across intermediate poses, where discrete search becomes brittle. We propose an implicit multi-step regrasp planning framework based on differentiable pose sequence connectivity metrics. We model grasp feasibility under an object pose using an Energy-Based Model (EBM) and leverage energy additivity to construct a continuous energy landscape that measures pose-pair connectivity, enabling gradient-based optimization of intermediate object poses. An adaptive iterative deepening strategy is introduced to determine the minimum number of intermediate steps automatically. Experiments show that the proposed cost formulation provides smooth and informative gradients, improving planning robustness over other alternatives. They also demonstrate generalization to unseen grasp poses and cross-end-effector transfer, where a model trained with suction constraints can guide parallel gripper grasp manipulation. The multi-step planning results further highlight the effectiveness of adaptive deepening and minimum-step search.
GOLLIC: Learning Global Context beyond Patches for Lossless High-Resolution Image Compression
Oct 07, 2022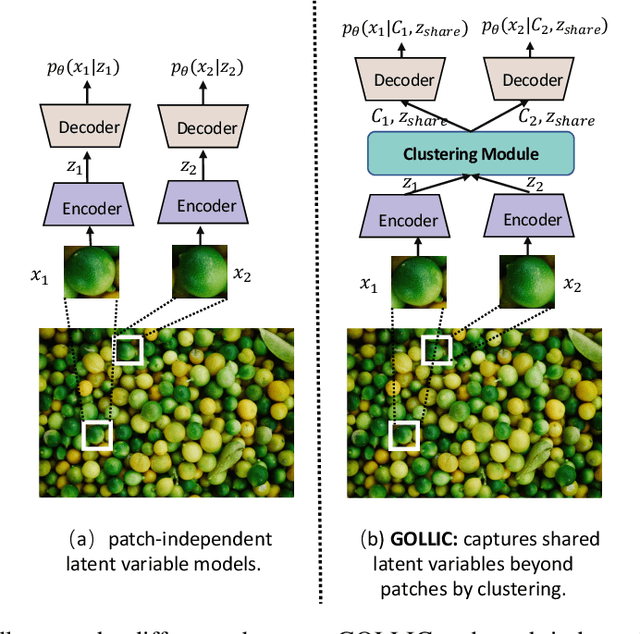
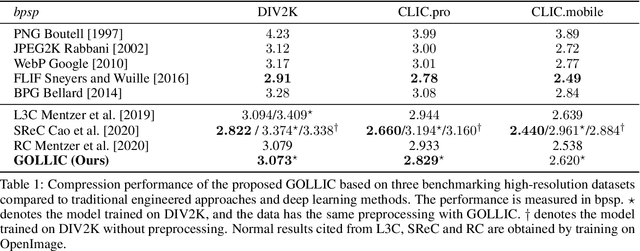
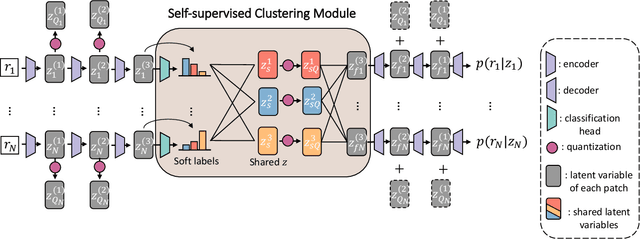

Neural-network-based approaches recently emerged in the field of data compression and have already led to significant progress in image compression, especially in achieving a higher compression ratio. In the lossless image compression scenario, however, existing methods often struggle to learn a probability model of full-size high-resolution images due to the limitation of the computation source. The current strategy is to crop high-resolution images into multiple non-overlapping patches and process them independently. This strategy ignores long-term dependencies beyond patches, thus limiting modeling performance. To address this problem, we propose a hierarchical latent variable model with a global context to capture the long-term dependencies of high-resolution images. Besides the latent variable unique to each patch, we introduce shared latent variables between patches to construct the global context. The shared latent variables are extracted by a self-supervised clustering module inside the model's encoder. This clustering module assigns each patch the confidence that it belongs to any cluster. Later, shared latent variables are learned according to latent variables of patches and their confidence, which reflects the similarity of patches in the same cluster and benefits the global context modeling. Experimental results show that our global context model improves compression ratio compared to the engineered codecs and deep learning models on three benchmark high-resolution image datasets, DIV2K, CLIC.pro, and CLIC.mobile.