 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Alignments in Directed Acyclic Graph for Non-Autoregressive Machine Translation
Mar 12, 2023Non-autoregressive translation (NAT) reduces the decoding latency but suffers from performance degradation due to the multi-modality problem. Recently, the structure of directed acyclic graph has achieved great success in NAT, which tackles the multi-modality problem by introducing dependency between vertices. However, training it with negative log-likelihood loss implicitly requires a strict alignment between reference tokens and vertices, weakening its ability to handle multiple translation modalities. In this paper, we hold the view that all paths in the graph are fuzzily aligned with the reference sentence. We do not require the exact alignment but train the model to maximize a fuzzy alignment score between the graph and reference, which takes captured translations in all modalities into account. Extensive experiments on major WMT benchmarks show that our method substantially improves translation performance and increases prediction confidence, setting a new state of the art for NAT on the raw training data.
Hidden Markov Transformer for Simultaneous Machine Translation
Mar 01, 2023Simultaneous machine translation (SiMT) outputs the target sequence while receiving the source sequence, and hence learning when to start translating each target token is the core challenge for SiMT task. However, it is non-trivial to learn the optimal moment among many possible moments of starting translating, as the moments of starting translating always hide inside the model and can only be supervised with the observed target sequence. In this paper, we propose a Hidden Markov Transformer (HMT), which treats the moments of starting translating as hidden events and the target sequence as the corresponding observed events, thereby organizing them as a hidden Markov model. HMT explicitly models multiple moments of starting translating as the candidate hidden events, and then selects one to generate the target token. During training, by maximizing the marginal likelihood of the target sequence over multiple moments of starting translating, HMT learns to start translating at the moments that target tokens can be generated more accurately. Experiments on multiple SiMT benchmarks show that HMT outperforms strong baselines and achieves state-of-the-art performance.
OrthoGAN:High-Precision Image Generation for Teeth Orthodontic Visualization
Dec 29, 2022



Patients take care of what their teeth will be like after the orthodontics. Orthodontists usually describe the expectation movement based on the original smile images, which is unconvincing. The growth of deep-learning generative models change this situation. It can visualize the outcome of orthodontic treatment and help patients foresee their future teeth and facial appearance. While previous studies mainly focus on 2D or 3D virtual treatment outcome (VTO) at a profile level, the problem of simulating treatment outcome at a frontal facial image is poorly explored. In this paper, we build an efficient and accurate system for simulating virtual teeth alignment effects in a frontal facial image. Our system takes a frontal face image of a patient with visible malpositioned teeth and the patient's 3D scanned teeth model as input, and progressively generates the visual results of the patient's teeth given the specific orthodontics planning steps from the doctor (i.e., the specification of translations and rotations of individual tooth). We design a multi-modal encoder-decoder based generative model to synthesize identity-preserving frontal facial images with aligned teeth. In addition, the original image color information is used to optimize the orthodontic outcomes, making the results more natural. We conduct extensive qualitative and clinical experiments and also a pilot study to validate our method.
Rephrasing the Reference for Non-Autoregressive Machine Translation
Nov 30, 2022



Non-autoregressive neural machine translation (NAT) models suffer from the multi-modality problem that there may exist multiple possible translations of a source sentence, so the reference sentence may be inappropriate for the training when the NAT output is closer to other translations. In response to this problem, we introduce a rephraser to provide a better training target for NAT by rephrasing the reference sentence according to the NAT output. As we train NAT based on the rephraser output rather than the reference sentence, the rephraser output should fit well with the NAT output and not deviate too far from the reference, which can be quantified as reward functions and optimized by reinforcement learning. Experiments on major WMT benchmarks and NAT baselines show that our approach consistently improves the translation quality of NAT. Specifically, our best variant achieves comparable performance to the autoregressive Transformer, while being 14.7 times more efficient in inference.
Continual Learning of Neural Machine Translation within Low Forgetting Risk Regions
Nov 04, 2022



This paper considers continual learning of large-scale pretrained neural machine translation model without accessing the previous training data or introducing model separation. We argue that the widely used regularization-based methods, which perform multi-objective learning with an auxiliary loss, suffer from the misestimate problem and cannot always achieve a good balance between the previous and new tasks. To solve the problem, we propose a two-stage training method based on the local features of the real loss. We first search low forgetting risk regions, where the model can retain the performance on the previous task as the parameters are updated, to avoid the catastrophic forgetting problem. Then we can continually train the model within this region only with the new training data to fit the new task. Specifically, we propose two methods to search the low forgetting risk regions, which are based on the curvature of loss and the impacts of the parameters on the model output, respectively. We conduct experiments on domain adaptation and more challenging language adaptation tasks, and the experimental results show that our method can achieve significant improvements compared with several strong baselines.
Counterfactual Data Augmentation via Perspective Transition for Open-Domain Dialogues
Oct 30, 2022The construction of open-domain dialogue systems requires high-quality dialogue datasets. The dialogue data admits a wide variety of responses for a given dialogue history, especially responses with different semantics. However, collecting high-quality such a dataset in most scenarios is labor-intensive and time-consuming. In this paper, we propose a data augmentation method to automatically augment high-quality responses with different semantics by counterfactual inference. Specifically, given an observed dialogue, our counterfactual generation model first infers semantically different responses by replacing the observed reply perspective with substituted ones. Furthermore, our data selection method filters out detrimental augmented responses. Experimental results show that our data augmentation method can augment high-quality responses with different semantics for a given dialogue history, and can outperform competitive baselines on multiple downstream tasks.
TFormer: 3D Tooth Segmentation in Mesh Scans with Geometry Guided Transformer
Oct 29, 2022Optical Intra-oral Scanners (IOS) are widely used in digital dentistry, providing 3-Dimensional (3D) and high-resolution geometrical information of dental crowns and the gingiva. Accurate 3D tooth segmentation, which aims to precisely delineate the tooth and gingiva instances in IOS, plays a critical role in a variety of dental applications. However, segmentation performance of previous methods are error-prone in complicated tooth-tooth or tooth-gingiva boundaries, and usually exhibit unsatisfactory results across various patients, yet the clinically applicability is not verified with large-scale dataset. In this paper, we propose a novel method based on 3D transformer architectures that is evaluated with large-scale and high-resolution 3D IOS datasets. Our method, termed TFormer, captures both local and global dependencies among different teeth to distinguish various types of teeth with divergent anatomical structures and confusing boundaries. Moreover, we design a geometry guided loss based on a novel point curvature to exploit boundary geometric features, which helps refine the boundary predictions for more accurate and smooth segmentation. We further employ a multi-task learning scheme, where an additional teeth-gingiva segmentation head is introduced to improve the performance. Extensive experimental results in a large-scale dataset with 16,000 IOS, the largest IOS dataset to our best knowledge, demonstrate that our TFormer can surpass existing state-of-the-art baselines with a large margin, with its utility in real-world scenarios verified by a clinical applicability test.
Improving Zero-Shot Multilingual Translation with Universal Representations and Cross-Mappings
Oct 28, 2022



The many-to-many multilingual neural machine translation can translate between language pairs unseen during training, i.e., zero-shot translation. Improving zero-shot translation requires the model to learn universal representations and cross-mapping relationships to transfer the knowledge learned on the supervised directions to the zero-shot directions. In this work, we propose the state mover's distance based on the optimal theory to model the difference of the representations output by the encoder. Then, we bridge the gap between the semantic-equivalent representations of different languages at the token level by minimizing the proposed distance to learn universal representations. Besides, we propose an agreement-based training scheme, which can help the model make consistent predictions based on the semantic-equivalent sentences to learn universal cross-mapping relationships for all translation directions. The experimental results on diverse multilingual datasets show that our method can improve consistently compared with the baseline system and other contrast methods. The analysis proves that our method can better align the semantic space and improve the prediction consistency.
Wait-info Policy: Balancing Source and Target at Information Level for Simultaneous Machine Translation
Oct 20, 2022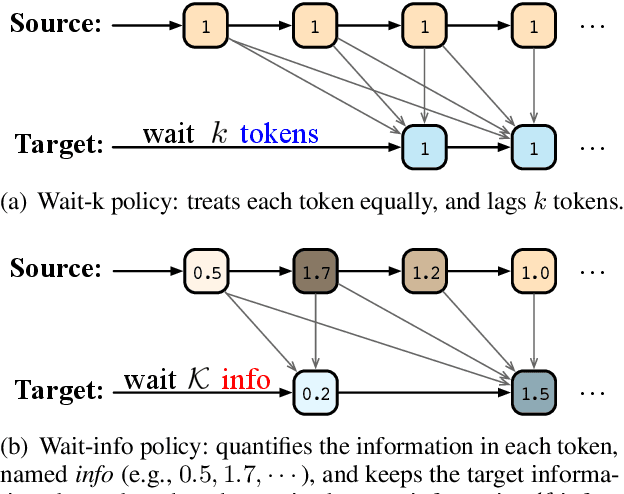
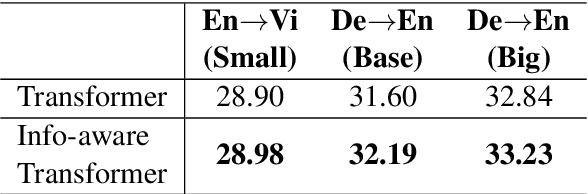
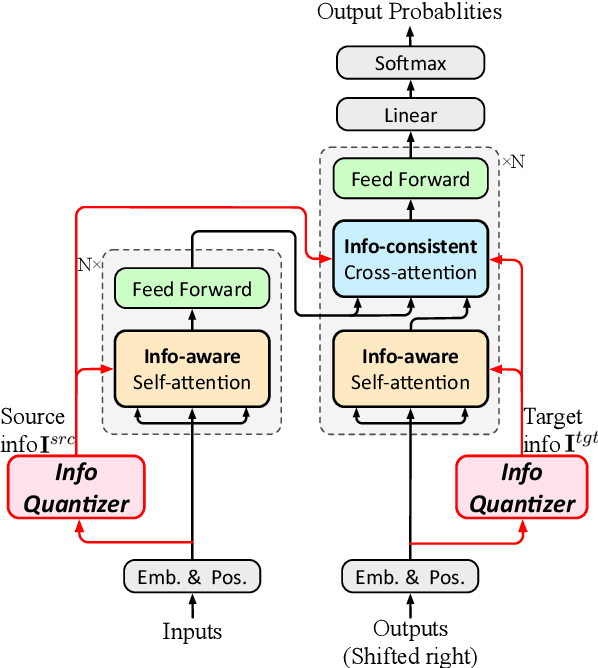
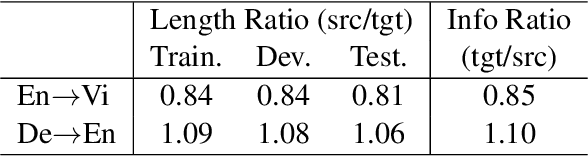
Simultaneous machine translation (SiMT) outputs the translation while receiving the source inputs, and hence needs to balance the received source information and translated target information to make a reasonable decision between waiting for inputs or outputting translation. Previous methods always balance source and target information at the token level, either directly waiting for a fixed number of tokens or adjusting the waiting based on the current token. In this paper, we propose a Wait-info Policy to balance source and target at the information level. We first quantify the amount of information contained in each token, named info. Then during simultaneous translation, the decision of waiting or outputting is made based on the comparison results between the total info of previous target outputs and received source inputs. Experiments show that our method outperforms strong baselines under and achieves better balance via the proposed info.
Low-resource Neural Machine Translation with Cross-modal Alignment
Oct 13, 2022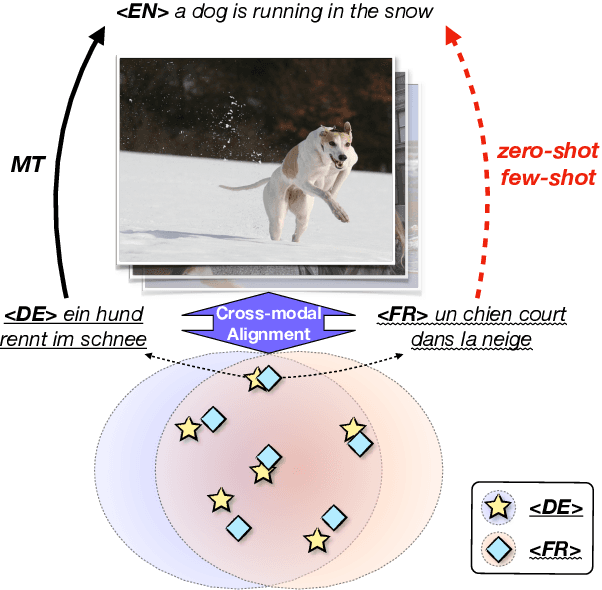
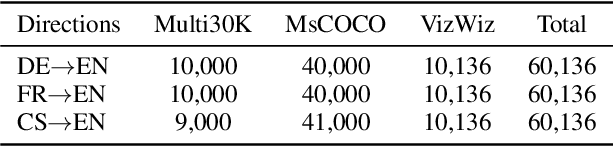
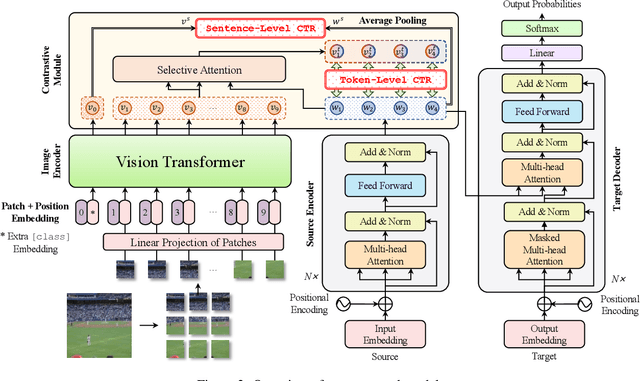
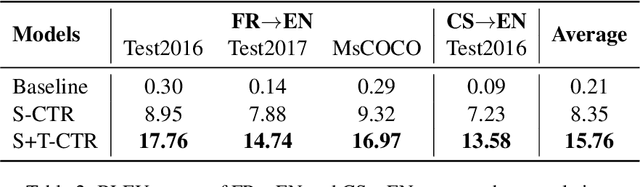
How to achieve neural machine translation with limited parallel data? Existing techniques often rely on large-scale monolingual corpora, which is impractical for some low-resource languages. In this paper, we turn to connect several low-resource languages to a particular high-resource one by additional visual modality. Specifically, we propose a cross-modal contrastive learning method to learn a shared space for all languages, where both a coarse-grained sentence-level objective and a fine-grained token-level one are introduced. Experimental results and further analysis show that our method can effectively learn the cross-modal and cross-lingual alignment with a small amount of image-text pairs and achieves significant improvements over the text-only baseline under both zero-shot and few-shot scenarios.