 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Polarity in Reinforcement Fine-Tuning: Direction, Asymmetry, and Control
May 14, 2026Policy entropy has emerged as a fundamental measure for understanding and controlling exploration in reinforcement learning with verifiable rewards (RLVR) for LLMs. However, existing entropy-aware methods mainly regulate entropy through global objectives, while the token-level mechanism by which sampled policy updates reshape policy entropy remains underexplored. In this work, we develop a theoretical framework of entropy mechanics in RLVR. Our analysis yields a first-order approximation of the entropy change, giving rise to entropy polarity, a signed token-level quantity that predicts how much a sampled update expands or contracts entropy. This analysis further reveals a structural asymmetry: reinforcing frequent high-probability tokens triggers contraction tendencies, whereas expansive tendencies typically require lower-probability samples or stronger distributional correction. Empirically, we show that entropy polarity reliably predicts entropy changes, and that positive and negative polarity branches play complementary roles in preserving exploration while strengthening exploitation. Building on these insights, we propose Polarity-Aware Policy Optimization (PAPO), which preserves both polarity branches and implements entropy control through advantage reweighting. With the empirical entropy trajectory as an online phase signal, PAPO adaptively reallocates optimization pressure between entropy-expanding and entropy-contracting updates. Experiments on mathematical reasoning and agentic benchmarks show that PAPO consistently outperforms competitive baselines, while delivering superior training efficiency and substantial reward improvements.
MagicAgent: Towards Generalized Agent Planning
Feb 22, 2026The evolution of Large Language Models (LLMs) from passive text processors to autonomous agents has established planning as a core component of modern intelligence. However, achieving generalized planning remains elusive, not only by the scarcity of high-quality interaction data but also by inherent conflicts across heterogeneous planning tasks. These challenges result in models that excel at isolated tasks yet struggle to generalize, while existing multi-task training attempts suffer from gradient interference. In this paper, we present \textbf{MagicAgent}, a series of foundation models specifically designed for generalized agent planning. We introduce a lightweight and scalable synthetic data framework that generates high-quality trajectories across diverse planning tasks, including hierarchical task decomposition, tool-augmented planning, multi-constraint scheduling, procedural logic orchestration, and long-horizon tool execution. To mitigate training conflicts, we propose a two-stage training paradigm comprising supervised fine-tuning followed by multi-objective reinforcement learning over both static datasets and dynamic environments. Empirical results demonstrate that MagicAgent-32B and MagicAgent-30B-A3B deliver superior performance, achieving accuracies of $75.1\%$ on Worfbench, $55.9\%$ on NaturalPlan, $57.5\%$ on $τ^2$-Bench, $86.9\%$ on BFCL-v3, and $81.2\%$ on ACEBench, as well as strong results on our in-house MagicEval benchmarks. These results substantially outperform existing sub-100B models and even surpass leading closed-source models.
Short Range Correlation Transformer for Occluded Person Re-Identification
Jan 04, 2022
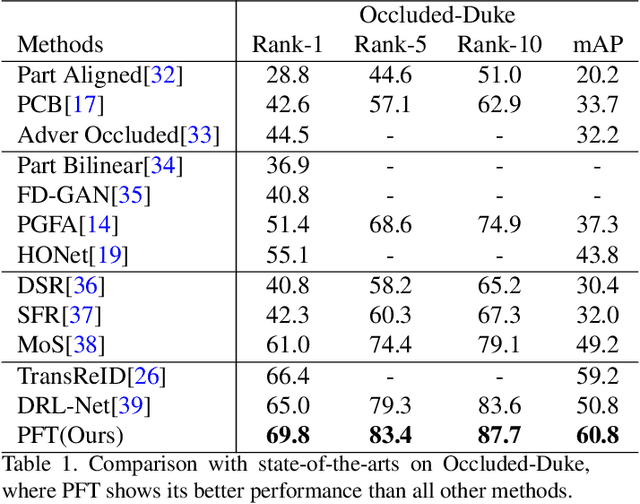
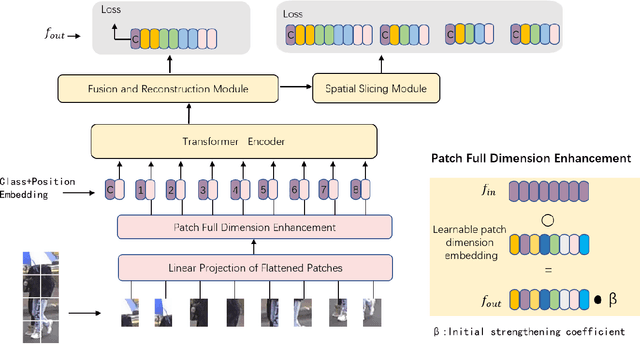
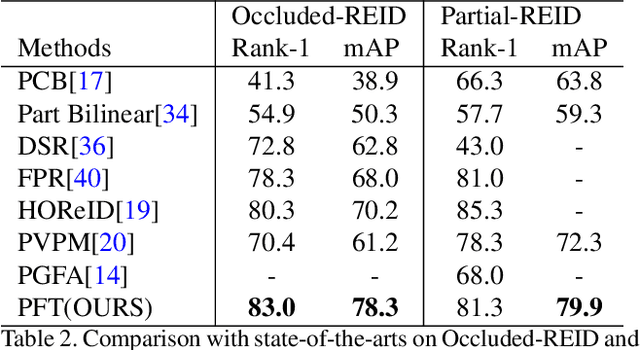
Occluded person re-identification is one of the challenging areas of computer vision, which faces problems such as inefficient feature representation and low recognition accuracy. Convolutional neural network pays more attention to the extraction of local features, therefore it is difficult to extract features of occluded pedestrians and the effect is not so satisfied. Recently, vision transformer is introduced into the field of re-identification and achieves the most advanced results by constructing the relationship of global features between patch sequences. However, the performance of vision transformer in extracting local features is inferior to that of convolutional neural network. Therefore, we design a partial feature transformer-based person re-identification framework named PFT. The proposed PFT utilizes three modules to enhance the efficiency of vision transformer. (1) Patch full dimension enhancement module. We design a learnable tensor with the same size as patch sequences, which is full-dimensional and deeply embedded in patch sequences to enrich the diversity of training samples. (2) Fusion and reconstruction module. We extract the less important part of obtained patch sequences, and fuse them with original patch sequence to reconstruct the original patch sequences. (3) Spatial Slicing Module. We slice and group patch sequences from spatial direction, which can effectively improve the short-range correlation of patch sequences. Experimental results over occluded and holistic re-identification datasets demonstrate that the proposed PFT network achieves superior performance consistently and outperforms the state-of-the-art methods.