 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Classifier Robustness through Active Generation of Pairwise Counterfactuals
May 22, 2023Counterfactual Data Augmentation (CDA) is a commonly used technique for improving robustness in natural language classifiers. However, one fundamental challenge is how to discover meaningful counterfactuals and efficiently label them, with minimal human labeling cost. Most existing methods either completely rely on human-annotated labels, an expensive process which limits the scale of counterfactual data, or implicitly assume label invariance, which may mislead the model with incorrect labels. In this paper, we present a novel framework that utilizes counterfactual generative models to generate a large number of diverse counterfactuals by actively sampling from regions of uncertainty, and then automatically label them with a learned pairwise classifier. Our key insight is that we can more correctly label the generated counterfactuals by training a pairwise classifier that interpolates the relationship between the original example and the counterfactual. We demonstrate that with a small amount of human-annotated counterfactual data (10%), we can generate a counterfactual augmentation dataset with learned labels, that provides an 18-20% improvement in robustness and a 14-21% reduction in errors on 6 out-of-domain datasets, comparable to that of a fully human-annotated counterfactual dataset for both sentiment classification and question paraphrase tasks.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Towards Robust Prompts on Vision-Language Models
Apr 17, 2023With the advent of vision-language models (VLMs) that can perform in-context and prompt-based learning, how can we design prompting approaches that robustly generalize to distribution shift and can be used on novel classes outside the support set of the prompts? In this work, we first define two types of robustness to distribution shift on VLMs, namely, robustness on base classes (the classes included in the support set of prompts) and robustness on novel classes. Then, we study the robustness of existing in-context learning and prompt learning approaches, where we find that prompt learning performs robustly on test images from base classes, while it does not generalize well on images from novel classes. We propose robust prompt learning by integrating multiple-scale image features into the prompt, which improves both types of robustness. Comprehensive experiments are conducted to study the defined robustness on six benchmarks and show the effectiveness of our proposal.
What Are Effective Labels for Augmented Data? Improving Calibration and Robustness with AutoLabel
Feb 22, 2023A wide breadth of research has devised data augmentation approaches that can improve both accuracy and generalization performance for neural networks. However, augmented data can end up being far from the clean training data and what is the appropriate label is less clear. Despite this, most existing work simply uses one-hot labels for augmented data. In this paper, we show re-using one-hot labels for highly distorted data might run the risk of adding noise and degrading accuracy and calibration. To mitigate this, we propose a generic method AutoLabel to automatically learn the confidence in the labels for augmented data, based on the transformation distance between the clean distribution and augmented distribution. AutoLabel is built on label smoothing and is guided by the calibration-performance over a hold-out validation set. We successfully apply AutoLabel to three different data augmentation techniques: the state-of-the-art RandAug, AugMix, and adversarial training. Experiments on CIFAR-10, CIFAR-100 and ImageNet show that AutoLabel significantly improves existing data augmentation techniques over models' calibration and accuracy, especially under distributional shift.
Bounding the Capabilities of Large Language Models in Open Text Generation with Prompt Constraints
Feb 17, 2023



The limits of open-ended generative models are unclear, yet increasingly important. What causes them to succeed and what causes them to fail? In this paper, we take a prompt-centric approach to analyzing and bounding the abilities of open-ended generative models. We present a generic methodology of analysis with two challenging prompt constraint types: structural and stylistic. These constraint types are categorized into a set of well-defined constraints that are analyzable by a single prompt. We then systematically create a diverse set of simple, natural, and useful prompts to robustly analyze each individual constraint. Using the GPT-3 text-davinci-002 model as a case study, we generate outputs from our collection of prompts and analyze the model's generative failures. We also show the generalizability of our proposed method on other large models like BLOOM and OPT. Our results and our in-context mitigation strategies reveal open challenges for future research. We have publicly released our code at https://github.com/SALT-NLP/Bound-Cap-LLM.
TEMPERA: Test-Time Prompting via Reinforcement Learning
Nov 21, 2022



Careful prompt design is critical to the use of large language models in zero-shot or few-shot learning. As a consequence, there is a growing interest in automated methods to design optimal prompts. In this work, we propose Test-time Prompt Editing using Reinforcement learning (TEMPERA). In contrast to prior prompt generation methods, TEMPERA can efficiently leverage prior knowledge, is adaptive to different queries and provides an interpretable prompt for every query. To achieve this, we design a novel action space that allows flexible editing of the initial prompts covering a wide set of commonly-used components like instructions, few-shot exemplars, and verbalizers. The proposed method achieves significant gains compared with recent SoTA approaches like prompt tuning, AutoPrompt, and RLPrompt, across a variety of tasks including sentiment analysis, topic classification, natural language inference, and reading comprehension. Our method achieves 5.33x on average improvement in sample efficiency when compared to the traditional fine-tuning methods.
Investigating Ensemble Methods for Model Robustness Improvement of Text Classifiers
Oct 28, 2022Large pre-trained language models have shown remarkable performance over the past few years. These models, however, sometimes learn superficial features from the dataset and cannot generalize to the distributions that are dissimilar to the training scenario. There have been several approaches proposed to reduce model's reliance on these bias features which can improve model robustness in the out-of-distribution setting. However, existing methods usually use a fixed low-capacity model to deal with various bias features, which ignore the learnability of those features. In this paper, we analyze a set of existing bias features and demonstrate there is no single model that works best for all the cases. We further show that by choosing an appropriate bias model, we can obtain a better robustness result than baselines with a more sophisticated model design.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022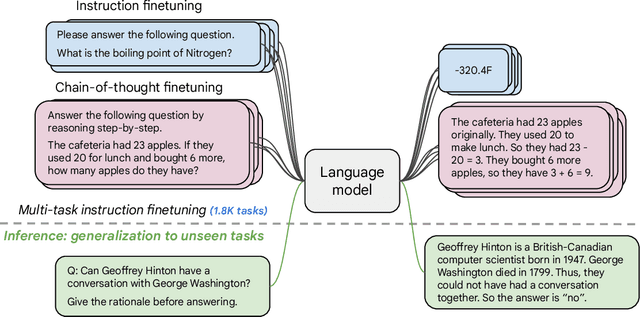

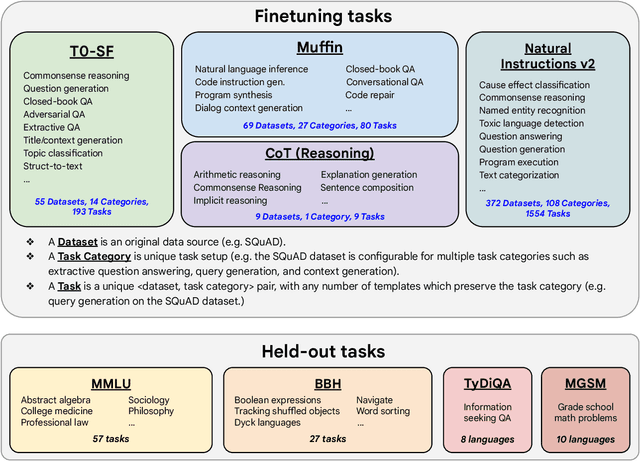

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Language Models are Multilingual Chain-of-Thought Reasoners
Oct 06, 2022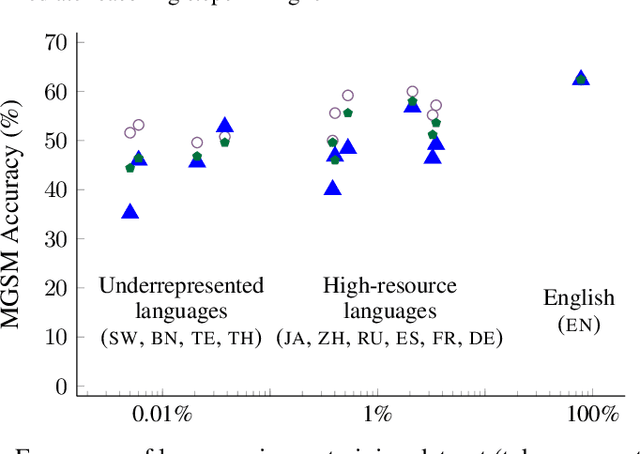


We evaluate the reasoning abilities of large language models in multilingual settings. We introduce the Multilingual Grade School Math (MGSM) benchmark, by manually translating 250 grade-school math problems from the GSM8K dataset (Cobbe et al., 2021) into ten typologically diverse languages. We find that the ability to solve MGSM problems via chain-of-thought prompting emerges with increasing model scale, and that models have strikingly strong multilingual reasoning abilities, even in underrepresented languages such as Bengali and Swahili. Finally, we show that the multilingual reasoning abilities of language models extend to other tasks such as commonsense reasoning and word-in-context semantic judgment. The MGSM benchmark is publicly available at https://github.com/google-research/url-nlp.
Recitation-Augmented Language Models
Oct 04, 2022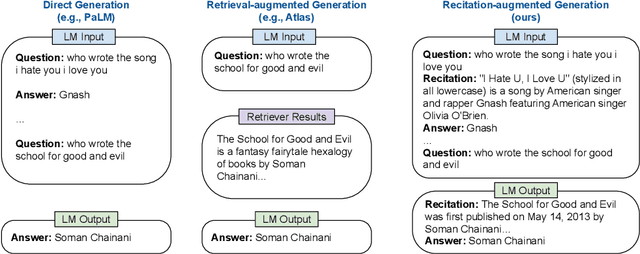
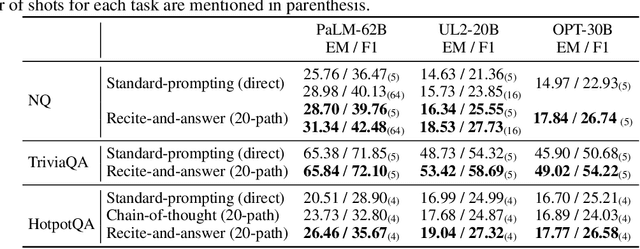
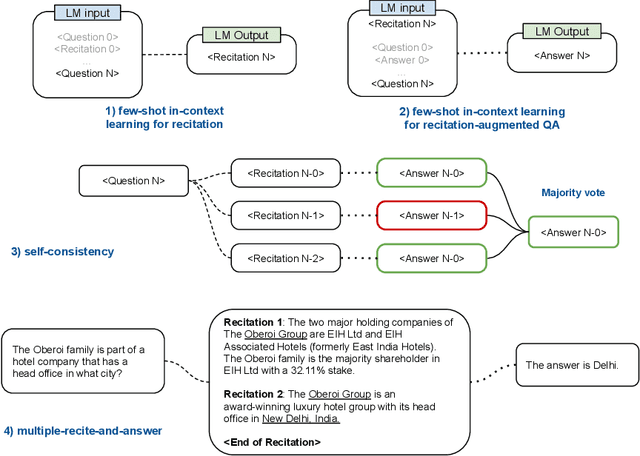

We propose a new paradigm to help Large Language Models (LLMs) generate more accurate factual knowledge without retrieving from an external corpus, called RECITation-augmented gEneration (RECITE). Different from retrieval-augmented language models that retrieve relevant documents before generating the outputs, given an input, RECITE first recites one or several relevant passages from LLMs' own memory via sampling, and then produces the final answers. We show that RECITE is a powerful paradigm for knowledge-intensive NLP tasks. Specifically, we show that by utilizing recitation as the intermediate step, a recite-and-answer scheme can achieve new state-of-the-art performance in various closed-book question answering (CBQA) tasks. In experiments, we verify the effectiveness of RECITE on three pre-trained models (PaLM, UL2, and OPT) and three CBQA tasks (Natural Questions, TriviaQA, and HotpotQA).