 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Learn by Teaching? A Preliminary Study
Jun 20, 2024



Teaching to improve student models (e.g., knowledge distillation) is an extensively studied methodology in LLMs. However, for humans, teaching not only improves students but also improves teachers. We ask: Can LLMs also learn by teaching (LbT)? If yes, we can potentially unlock the possibility of continuously advancing the models without solely relying on human-produced data or stronger models. In this paper, we provide a preliminary exploration of this ambitious agenda. We show that LbT ideas can be incorporated into existing LLM training/prompting pipelines and provide noticeable improvements. Specifically, we design three methods, each mimicking one of the three levels of LbT in humans: observing students' feedback, learning from the feedback, and learning iteratively, with the goals of improving answer accuracy without training and improving models' inherent capability with fine-tuning. The findings are encouraging. For example, similar to LbT in human, we see that: (1) LbT can induce weak-to-strong generalization: strong models can improve themselves by teaching other weak models; (2) Diversity in students might help: teaching multiple students could be better than teaching one student or the teacher itself. We hope that this early promise can inspire future research on LbT and more broadly adopting the advanced techniques in education to improve LLMs. The code is available at https://github.com/imagination-research/lbt.
DiTFastAttn: Attention Compression for Diffusion Transformer Models
Jun 12, 2024



Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to self-attention's quadratic complexity. We propose DiTFastAttn, a novel post-training compression method to alleviate DiT's computational bottleneck. We identify three key redundancies in the attention computation during DiT inference: 1. spatial redundancy, where many attention heads focus on local information; 2. temporal redundancy, with high similarity between neighboring steps' attention outputs; 3. conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. To tackle these redundancies, we propose three techniques: 1. Window Attention with Residual Caching to reduce spatial redundancy; 2. Temporal Similarity Reduction to exploit the similarity between steps; 3. Conditional Redundancy Elimination to skip redundant computations during conditional generation. To demonstrate the effectiveness of DiTFastAttn, we apply it to DiT, PixArt-Sigma for image generation tasks, and OpenSora for video generation tasks. Evaluation results show that for image generation, our method reduces up to 88\% of the FLOPs and achieves up to 1.6x speedup at high resolution generation.
ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation
Jun 04, 2024



Diffusion transformers (DiTs) have exhibited remarkable performance in visual generation tasks, such as generating realistic images or videos based on textual instructions. However, larger model sizes and multi-frame processing for video generation lead to increased computational and memory costs, posing challenges for practical deployment on edge devices. Post-Training Quantization (PTQ) is an effective method for reducing memory costs and computational complexity. When quantizing diffusion transformers, we find that applying existing diffusion quantization methods designed for U-Net faces challenges in preserving quality. After analyzing the major challenges for quantizing diffusion transformers, we design an improved quantization scheme: "ViDiT-Q": Video and Image Diffusion Transformer Quantization) to address these issues. Furthermore, we identify highly sensitive layers and timesteps hinder quantization for lower bit-widths. To tackle this, we improve ViDiT-Q with a novel metric-decoupled mixed-precision quantization method (ViDiT-Q-MP). We validate the effectiveness of ViDiT-Q across a variety of text-to-image and video models. While baseline quantization methods fail at W8A8 and produce unreadable content at W4A8, ViDiT-Q achieves lossless W8A8 quantization. ViDiTQ-MP achieves W4A8 with negligible visual quality degradation, resulting in a 2.5x memory optimization and a 1.5x latency speedup.
MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
May 30, 2024



Diffusion models have achieved significant visual generation quality. However, their significant computational and memory costs pose challenge for their application on resource-constrained mobile devices or even desktop GPUs. Recent few-step diffusion models reduces the inference time by reducing the denoising steps. However, their memory consumptions are still excessive. The Post Training Quantization (PTQ) replaces high bit-width FP representation with low-bit integer values (INT4/8) , which is an effective and efficient technique to reduce the memory cost. However, when applying to few-step diffusion models, existing quantization methods face challenges in preserving both the image quality and text alignment. To address this issue, we propose an mixed-precision quantization framework - MixDQ. Firstly, We design specialized BOS-aware quantization method for highly sensitive text embedding quantization. Then, we conduct metric-decoupled sensitivity analysis to measure the sensitivity of each layer. Finally, we develop an integer-programming-based method to conduct bit-width allocation. While existing quantization methods fall short at W8A8, MixDQ could achieve W8A8 without performance loss, and W4A8 with negligible visual degradation. Compared with FP16, we achieve 3-4x reduction in model size and memory cost, and 1.45x latency speedup.
HetHub: A Heterogeneous distributed hybrid training system for large-scale models
May 25, 2024The development of large-scale models relies on a vast number of computing resources. For example, the GPT-4 model (1.8 trillion parameters) requires 25000 A100 GPUs for its training. It is a challenge to build a large-scale cluster with a type of GPU-accelerator. Using multiple types of GPU-accelerators to construct a cluster is an effective way to solve the problem of insufficient homogeneous GPU-accelerators. However, the existing distributed training systems for large-scale models only support homogeneous GPU-accelerators, not heterogeneous GPU-accelerators. To address the problem, this paper proposes a distributed training system with hybrid parallelism support on heterogeneous GPU-accelerators for large-scale models. It introduces a distributed unified communicator to realize the communication between heterogeneous GPU-accelerators, a distributed performance predictor, and an automatic hybrid parallel module to develop and train models efficiently with heterogeneous GPU-accelerators. Compared to the distributed training system with homogeneous GPU-accelerators, our system can support six different combinations of heterogeneous GPU-accelerators and the optimal performance of heterogeneous GPU-accelerators has achieved at least 90% of the theoretical upper bound performance of homogeneous GPU-accelerators.
DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis
May 23, 2024



Diffusion models have achieved great success in image generation, with the backbone evolving from U-Net to Vision Transformers. However, the computational cost of Transformers is quadratic to the number of tokens, leading to significant challenges when dealing with high-resolution images. In this work, we propose Diffusion Mamba (DiM), which combines the efficiency of Mamba, a sequence model based on State Space Models (SSM), with the expressive power of diffusion models for efficient high-resolution image synthesis. To address the challenge that Mamba cannot generalize to 2D signals, we make several architecture designs including multi-directional scans, learnable padding tokens at the end of each row and column, and lightweight local feature enhancement. Our DiM architecture achieves inference-time efficiency for high-resolution images. In addition, to further improve training efficiency for high-resolution image generation with DiM, we investigate ``weak-to-strong'' training strategy that pretrains DiM on low-resolution images ($256\times 256$) and then finetune it on high-resolution images ($512 \times 512$). We further explore training-free upsampling strategies to enable the model to generate higher-resolution images (e.g., $1024\times 1024$ and $1536\times 1536$) without further fine-tuning. Experiments demonstrate the effectiveness and efficiency of our DiM.
A Survey on Efficient Inference for Large Language Models
Apr 22, 2024Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
Apr 08, 2024



Diffusion Models (DM) and Consistency Models (CM) are two types of popular generative models with good generation quality on various tasks. When training DM and CM, intermediate weight checkpoints are not fully utilized and only the last converged checkpoint is used. In this work, we find that high-quality model weights often lie in a basin which cannot be reached by SGD but can be obtained by proper checkpoint averaging. Based on these observations, we propose LCSC, a simple but effective and efficient method to enhance the performance of DM and CM, by combining checkpoints along the training trajectory with coefficients deduced from evolutionary search. We demonstrate the value of LCSC through two use cases: $\textbf{(a) Reducing training cost.}$ With LCSC, we only need to train DM/CM with fewer number of iterations and/or lower batch sizes to obtain comparable sample quality with the fully trained model. For example, LCSC achieves considerable training speedups for CM (23$\times$ on CIFAR-10 and 15$\times$ on ImageNet-64). $\textbf{(b) Enhancing pre-trained models.}$ Assuming full training is already done, LCSC can further improve the generation quality or speed of the final converged models. For example, LCSC achieves better performance using 1 number of function evaluation (NFE) than the base model with 2 NFE on consistency distillation, and decreases the NFE of DM from 15 to 9 while maintaining the generation quality on CIFAR-10. Our code is available at https://github.com/imagination-research/LCSC.
FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models
Mar 25, 2024



In recent years, there has been significant progress in the development of text-to-image generative models. Evaluating the quality of the generative models is one essential step in the development process. Unfortunately, the evaluation process could consume a significant amount of computational resources, making the required periodic evaluation of model performance (e.g., monitoring training progress) impractical. Therefore, we seek to improve the evaluation efficiency by selecting the representative subset of the text-image dataset. We systematically investigate the design choices, including the selection criteria (textural features or image-based metrics) and the selection granularity (prompt-level or set-level). We find that the insights from prior work on subset selection for training data do not generalize to this problem, and we propose FlashEval, an iterative search algorithm tailored to evaluation data selection. We demonstrate the effectiveness of FlashEval on ranking diffusion models with various configurations, including architectures, quantization levels, and sampler schedules on COCO and DiffusionDB datasets. Our searched 50-item subset could achieve comparable evaluation quality to the randomly sampled 500-item subset for COCO annotations on unseen models, achieving a 10x evaluation speedup. We release the condensed subset of these commonly used datasets to help facilitate diffusion algorithm design and evaluation, and open-source FlashEval as a tool for condensing future datasets, accessible at https://github.com/thu-nics/FlashEval.
Evaluating Quantized Large Language Models
Feb 28, 2024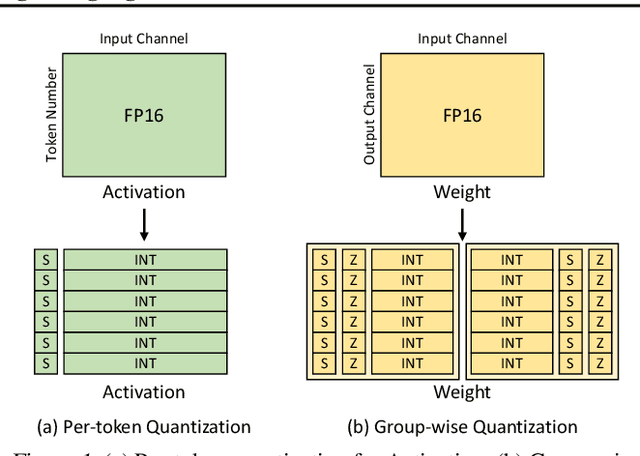



Post-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memory consumption and reduce computational overhead in LLMs. To meet the requirements of both high efficiency and performance across diverse scenarios, a comprehensive evaluation of quantized LLMs is essential to guide the selection of quantization methods. This paper presents a thorough evaluation of these factors by evaluating the effect of PTQ on Weight, Activation, and KV Cache on 11 model families, including OPT, LLaMA2, Falcon, Bloomz, Mistral, ChatGLM, Vicuna, LongChat, StableLM, Gemma, and Mamba, with parameters ranging from 125M to 180B. The evaluation encompasses five types of tasks: basic NLP, emergent ability, trustworthiness, dialogue, and long-context tasks. Moreover, we also evaluate the state-of-the-art (SOTA) quantization methods to demonstrate their applicability. Based on the extensive experiments, we systematically summarize the effect of quantization, provide recommendations to apply quantization techniques, and point out future directions.