 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSToM:Causal-oriented Steering for Intrinsic Theory-of-Mind Alignment in Large Language Models
Apr 11, 2026Theory of Mind (ToM), the ability to attribute mental states to others, is a hallmark of social intelligence. While large language models (LLMs) demonstrate promising performance on standard ToM benchmarks, we observe that they often fail to generalize to complex task-specific scenarios, relying heavily on prompt scaffolding to mimic reasoning. The critical misalignment between the internal knowledge and external behavior raises a fundamental question: Do LLMs truly possess intrinsic cognition, and can they externalize this internal knowledge into stable, high-quality behaviors? To answer this, we introduce CoSToM (Causal-oriented Steering for ToM alignment), a framework that transitions from mechanistic interpretation to active intervention. First, we employ causal tracing to map the internal distribution of ToM features, empirically uncovering the internal layers' characteristics in encoding fundamental ToM semantics. Building on this insight, we implement a lightweight alignment framework via targeted activation steering within these ToM-critical layers. Experiments demonstrate that CoSToM significantly enhances human-like social reasoning capabilities and downstream dialogue quality.
EffiSkill: Agent Skill Based Automated Code Efficiency Optimization
Mar 29, 2026Code efficiency is a fundamental aspect of software quality, yet how to harness large language models (LLMs) to optimize programs remains challenging. Prior approaches have sought for one-shot rewriting, retrieved exemplars, or prompt-based search, but they do not explicitly distill reusable optimization knowledge, which limits generalization beyond individual instances. In this paper, we present EffiSkill, a framework for code-efficiency optimization that builds a portable optimization toolbox for LLM-based agents. The key idea is to model recurring slow-to-fast transformations as reusable agent skills that capture both concrete transformation mechanisms and higher-level optimization strategies. EffiSkill adopts a two-stage design: Stage I mines Operator and Meta Skills from large-scale slow/fast program pairs to build a skill library; Stage II applies this library to unseen programs through execution-free diagnosis, skill retrieval, plan composition, and candidate generation, without runtime feedback. Results on EffiBench-X show that EffiSkill achieves higher optimization success rates, improving over the strongest baseline by 3.69 to 12.52 percentage points across model and language settings. These findings suggest that mechanism-level skill reuse provides a useful foundation for execution-free code optimization, and that the resulting skill library can serve as a reusable resource for broader agent workflows.
Adverseness vs. Equilibrium: Exploring Graph Adversarial Resilience through Dynamic Equilibrium
May 20, 2025Adversarial attacks to graph analytics are gaining increased attention. To date, two lines of countermeasures have been proposed to resist various graph adversarial attacks from the perspectives of either graph per se or graph neural networks. Nevertheless, a fundamental question lies in whether there exists an intrinsic adversarial resilience state within a graph regime and how to find out such a critical state if exists. This paper contributes to tackle the above research questions from three unique perspectives: i) we regard the process of adversarial learning on graph as a complex multi-object dynamic system, and model the behavior of adversarial attack; ii) we propose a generalized theoretical framework to show the existence of critical adversarial resilience state; and iii) we develop a condensed one-dimensional function to capture the dynamic variation of graph regime under perturbations, and pinpoint the critical state through solving the equilibrium point of dynamic system. Multi-facet experiments are conducted to show our proposed approach can significantly outperform the state-of-the-art defense methods under five commonly-used real-world datasets and three representative attacks.
SifterNet: A Generalized and Model-Agnostic Trigger Purification Approach
May 20, 2025Aiming at resisting backdoor attacks in convolution neural networks and vision Transformer-based large model, this paper proposes a generalized and model-agnostic trigger-purification approach resorting to the classic Ising model. To date, existing trigger detection/removal studies usually require to know the detailed knowledge of target model in advance, access to a large number of clean samples or even model-retraining authorization, which brings the huge inconvenience for practical applications, especially inaccessible to target model. An ideal countermeasure ought to eliminate the implanted trigger without regarding whatever the target models are. To this end, a lightweight and black-box defense approach SifterNet is proposed through leveraging the memorization-association functionality of Hopfield network, by which the triggers of input samples can be effectively purified in a proper manner. The main novelty of our proposed approach lies in the introduction of ideology of Ising model. Extensive experiments also validate the effectiveness of our approach in terms of proper trigger purification and high accuracy achievement, and compared to the state-of-the-art baselines under several commonly-used datasets, our SiferNet has a significant superior performance.
Hyperbolic Hypergraph Neural Networks for Multi-Relational Knowledge Hypergraph Representation
Dec 11, 2024



Knowledge hypergraphs generalize knowledge graphs using hyperedges to connect multiple entities and depict complicated relations. Existing methods either transform hyperedges into an easier-to-handle set of binary relations or view hyperedges as isolated and ignore their adjacencies. Both approaches have information loss and may potentially lead to the creation of sub-optimal models. To fix these issues, we propose the Hyperbolic Hypergraph Neural Network (H2GNN), whose essential component is the hyper-star message passing, a novel scheme motivated by a lossless expansion of hyperedges into hierarchies. It implements a direct embedding that consciously incorporates adjacent entities, hyper-relations, and entity position-aware information. As the name suggests, H2GNN operates in the hyperbolic space, which is more adept at capturing the tree-like hierarchy. We compare H2GNN with 15 baselines on knowledge hypergraphs, and it outperforms state-of-the-art approaches in both node classification and link prediction tasks.
Research on the Detection Method of Breast Cancer Deep Convolutional Neural Network Based on Computer Aid
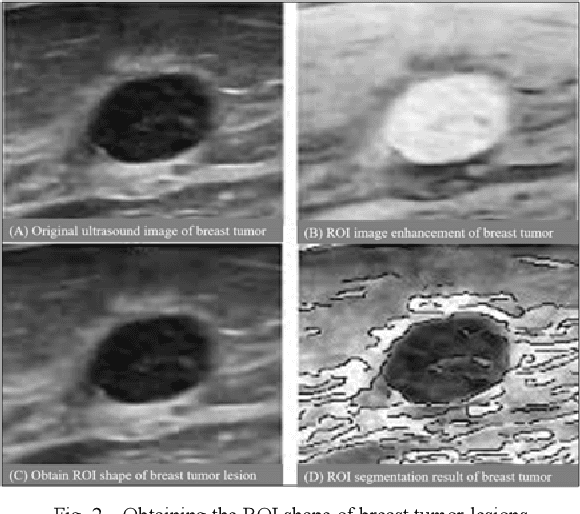
Apr 23, 2021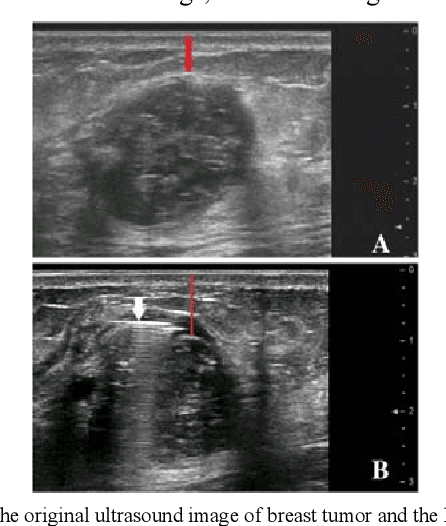
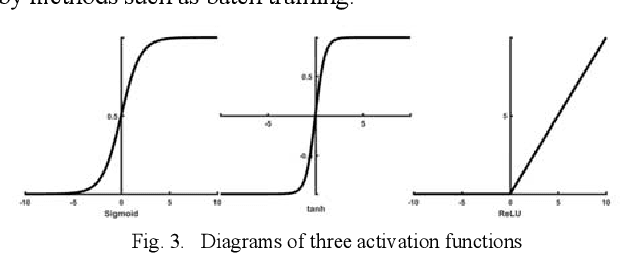
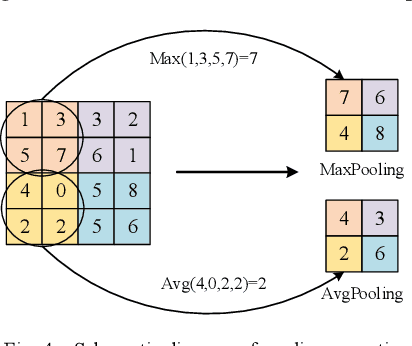
Traditional breast cancer image classification methods require manual extraction of features from medical images, which not only require professional medical knowledge, but also have problems such as time-consuming and labor-intensive and difficulty in extracting high-quality features. Therefore, the paper proposes a computer-based feature fusion Convolutional neural network breast cancer image classification and detection method. The paper pre-trains two convolutional neural networks with different structures, and then uses the convolutional neural network to automatically extract the characteristics of features, fuse the features extracted from the two structures, and finally use the classifier classifies the fused features. The experimental results show that the accuracy of this method in the classification of breast cancer image data sets is 89%, and the classification accuracy of breast cancer images is significantly improved compared with traditional methods.