 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview-Driven Multi-Label Music Style Classification by Exploiting Style Correlations
Aug 23, 2018
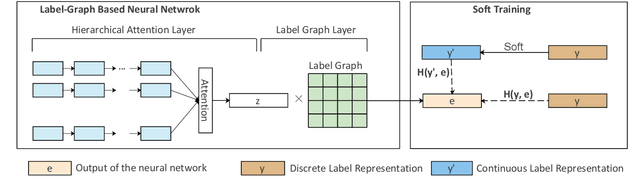
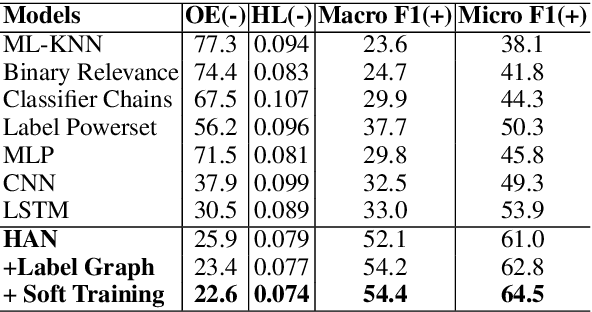
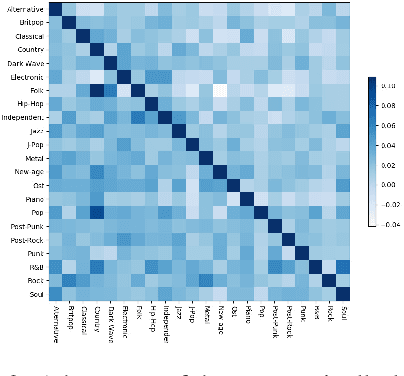
This paper explores a new natural language processing task, review-driven multi-label music style classification. This task requires the system to identify multiple styles of music based on its reviews on websites. The biggest challenge lies in the complicated relations of music styles. It has brought failure to many multi-label classification methods. To tackle this problem, we propose a novel deep learning approach to automatically learn and exploit style correlations. The proposed method consists of two parts: a label-graph based neural network, and a soft training mechanism with correlation-based continuous label representation. Experimental results show that our approach achieves large improvements over the baselines on the proposed dataset. Especially, the micro F1 is improved from 53.9 to 64.5, and the one-error is reduced from 30.5 to 22.6. Furthermore, the visualized analysis shows that our approach performs well in capturing style correlations.
DP-GAN: Diversity-Promoting Generative Adversarial Network for Generating Informative and Diversified Text
Aug 21, 2018
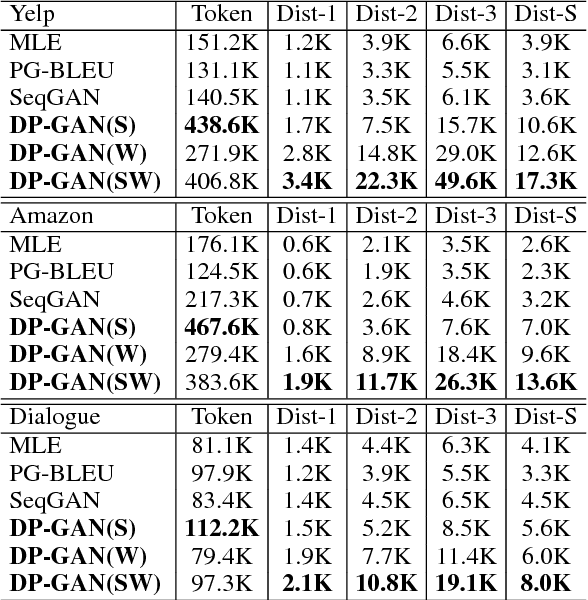
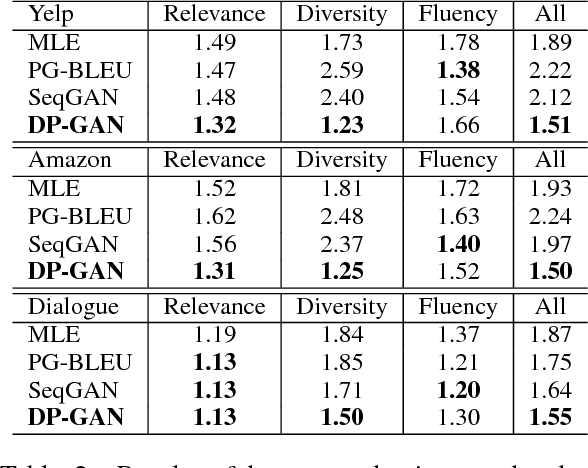
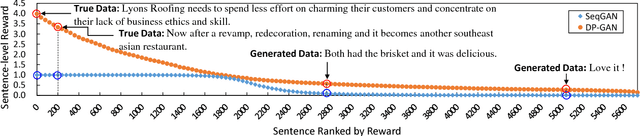
Existing text generation methods tend to produce repeated and "boring" expressions. To tackle this problem, we propose a new text generation model, called Diversity-Promoting Generative Adversarial Network (DP-GAN). The proposed model assigns low reward for repeatedly generated text and high reward for "novel" and fluent text, encouraging the generator to produce diverse and informative text. Moreover, we propose a novel language-model based discriminator, which can better distinguish novel text from repeated text without the saturation problem compared with existing classifier-based discriminators. The experimental results on review generation and dialogue generation tasks demonstrate that our model can generate substantially more diverse and informative text than existing baselines. The code is available at https://github.com/lancopku/DPGAN
Sememe Prediction: Learning Semantic Knowledge from Unstructured Textual Wiki Descriptions
Aug 16, 2018
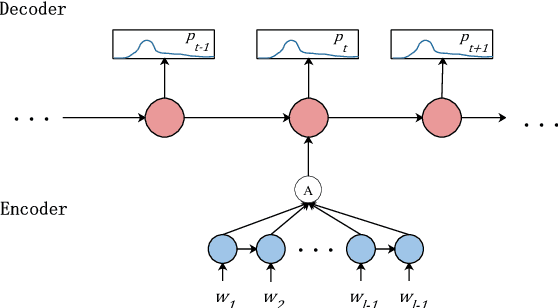
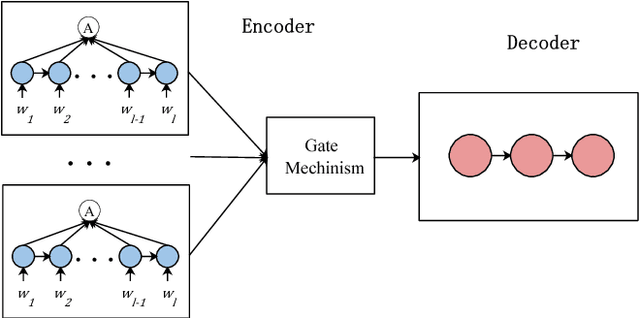
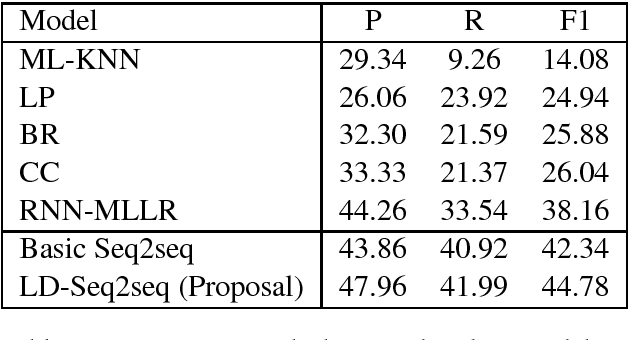
Huge numbers of new words emerge every day, leading to a great need for representing them with semantic meaning that is understandable to NLP systems. Sememes are defined as the minimum semantic units of human languages, the combination of which can represent the meaning of a word. Manual construction of sememe based knowledge bases is time-consuming and labor-intensive. Fortunately, communities are devoted to composing the descriptions of words in the wiki websites. In this paper, we explore to automatically predict lexical sememes based on the descriptions of the words in the wiki websites. We view this problem as a weakly ordered multi-label task and propose a Label Distributed seq2seq model (LD-seq2seq) with a novel soft loss function to solve the problem. In the experiments, we take a real-world sememe knowledge base HowNet and the corresponding descriptions of the words in Baidu Wiki for training and evaluation. The results show that our LD-seq2seq model not only beats all the baselines significantly on the test set, but also outperforms amateur human annotators in a random subset of the test set.
Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach
Aug 05, 2018
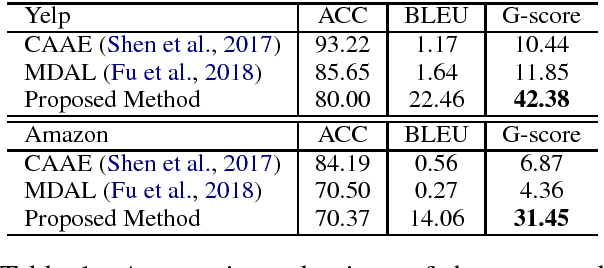
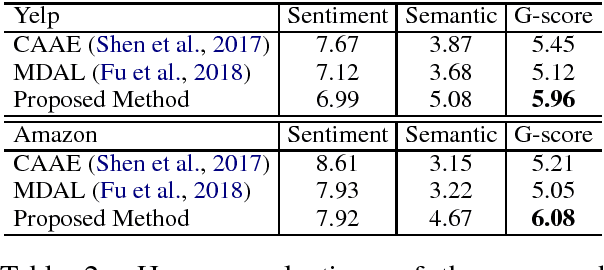

The goal of sentiment-to-sentiment "translation" is to change the underlying sentiment of a sentence while keeping its content. The main challenge is the lack of parallel data. To solve this problem, we propose a cycled reinforcement learning method that enables training on unpaired data by collaboration between a neutralization module and an emotionalization module. We evaluate our approach on two review datasets, Yelp and Amazon. Experimental results show that our approach significantly outperforms the state-of-the-art systems. Especially, the proposed method substantially improves the content preservation performance. The BLEU score is improved from 1.64 to 22.46 and from 0.56 to 14.06 on the two datasets, respectively.
Does Higher Order LSTM Have Better Accuracy for Segmenting and Labeling Sequence Data?
Jun 13, 2018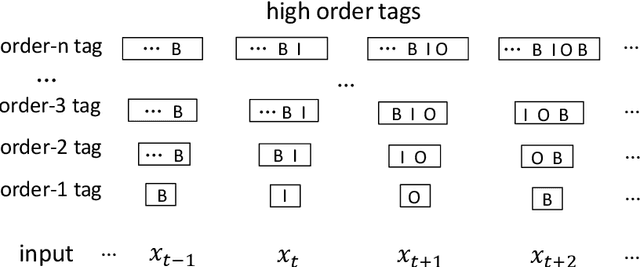
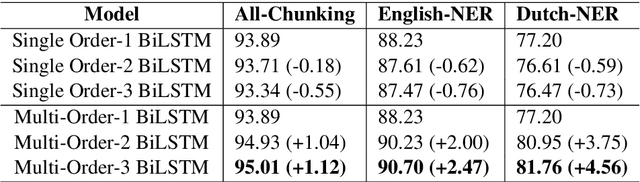

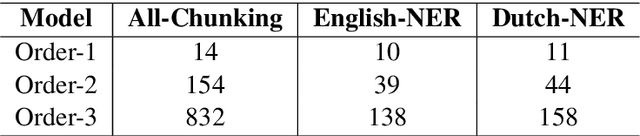
Existing neural models usually predict the tag of the current token independent of the neighboring tags. The popular LSTM-CRF model considers the tag dependencies between every two consecutive tags. However, it is hard for existing neural models to take longer distance dependencies of tags into consideration. The scalability is mainly limited by the complex model structures and the cost of dynamic programming during training. In our work, we first design a new model called "high order LSTM" to predict multiple tags for the current token which contains not only the current tag but also the previous several tags. We call the number of tags in one prediction as "order". Then we propose a new method called Multi-Order BiLSTM (MO-BiLSTM) which combines low order and high order LSTMs together. MO-BiLSTM keeps the scalability to high order models with a pruning technique. We evaluate MO-BiLSTM on all-phrase chunking and NER datasets. Experiment results show that MO-BiLSTM achieves the state-of-the-art result in chunking and highly competitive results in two NER datasets.
Deconvolution-Based Global Decoding for Neural Machine Translation
Jun 10, 2018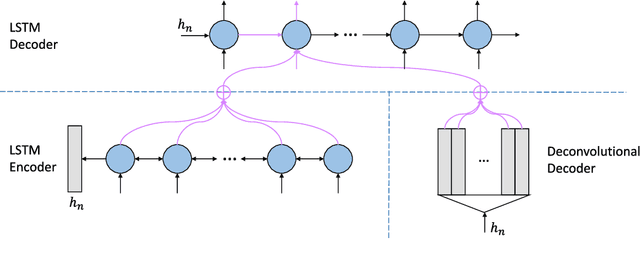
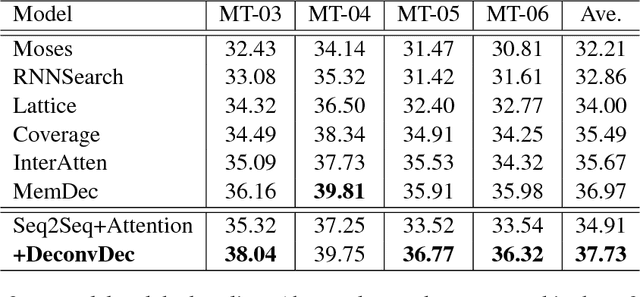
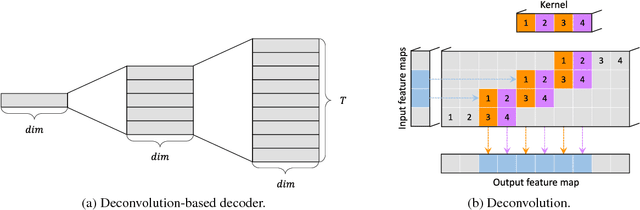
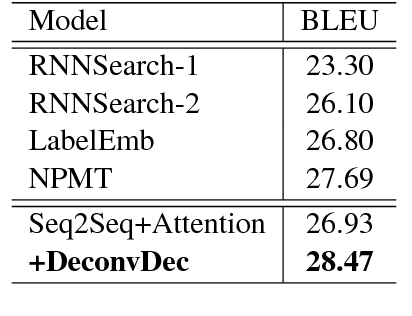
A great proportion of sequence-to-sequence (Seq2Seq) models for Neural Machine Translation (NMT) adopt Recurrent Neural Network (RNN) to generate translation word by word following a sequential order. As the studies of linguistics have proved that language is not linear word sequence but sequence of complex structure, translation at each step should be conditioned on the whole target-side context. To tackle the problem, we propose a new NMT model that decodes the sequence with the guidance of its structural prediction of the context of the target sequence. Our model generates translation based on the structural prediction of the target-side context so that the translation can be freed from the bind of sequential order. Experimental results demonstrate that our model is more competitive compared with the state-of-the-art methods, and the analysis reflects that our model is also robust to translating sentences of different lengths and it also reduces repetition with the instruction from the target-side context for decoding.
A Hierarchical End-to-End Model for Jointly Improving Text Summarization and Sentiment Classification
May 30, 2018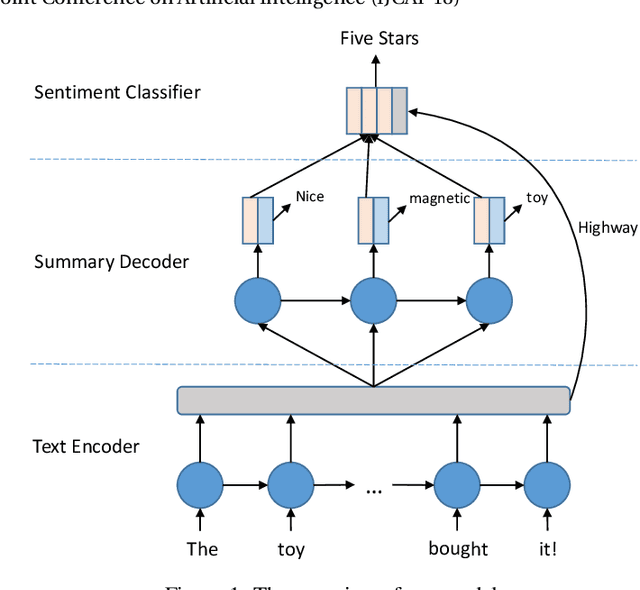
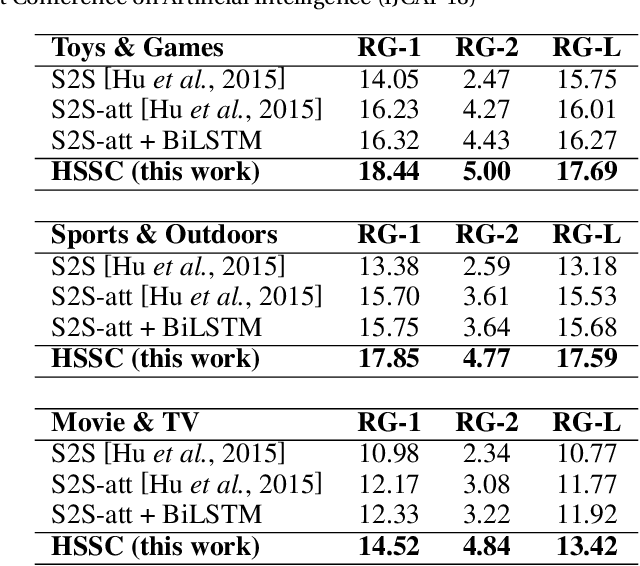
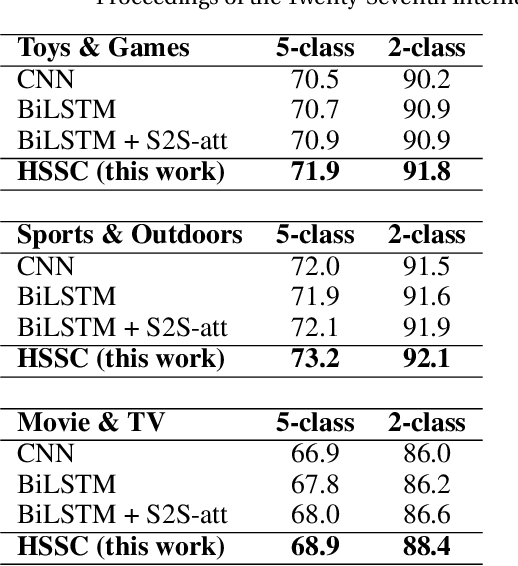
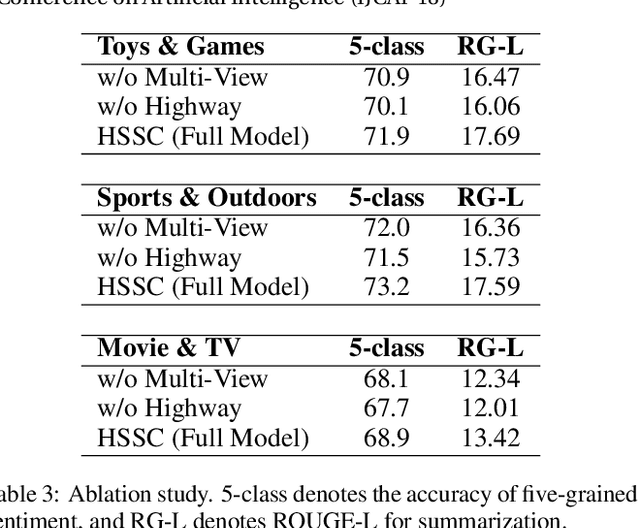
Text summarization and sentiment classification both aim to capture the main ideas of the text but at different levels. Text summarization is to describe the text within a few sentences, while sentiment classification can be regarded as a special type of summarization which "summarizes" the text into a even more abstract fashion, i.e., a sentiment class. Based on this idea, we propose a hierarchical end-to-end model for joint learning of text summarization and sentiment classification, where the sentiment classification label is treated as the further "summarization" of the text summarization output. Hence, the sentiment classification layer is put upon the text summarization layer, and a hierarchical structure is derived. Experimental results on Amazon online reviews datasets show that our model achieves better performance than the strong baseline systems on both abstractive summarization and sentiment classification.
Regularizing Output Distribution of Abstractive Chinese Social Media Text Summarization for Improved Semantic Consistency
May 10, 2018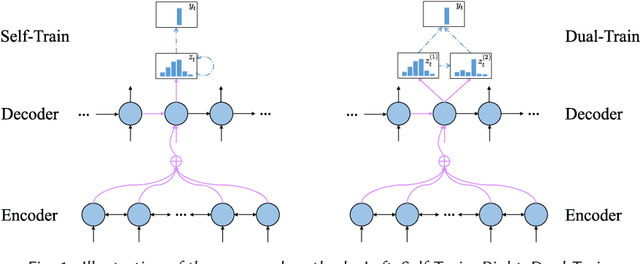
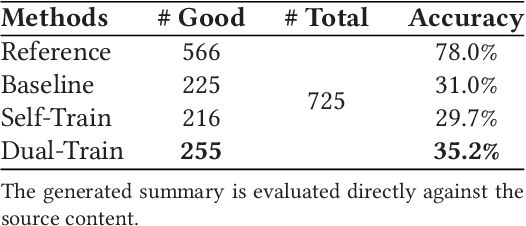
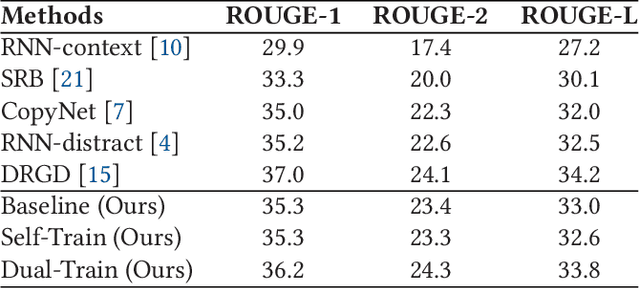
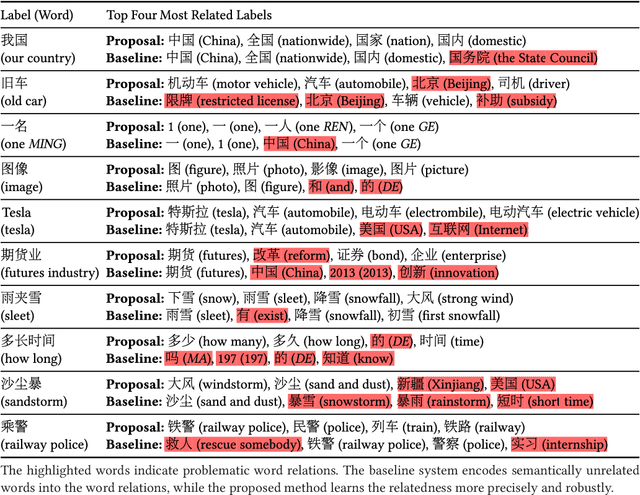
Abstractive text summarization is a highly difficult problem, and the sequence-to-sequence model has shown success in improving the performance on the task. However, the generated summaries are often inconsistent with the source content in semantics. In such cases, when generating summaries, the model selects semantically unrelated words with respect to the source content as the most probable output. The problem can be attributed to heuristically constructed training data, where summaries can be unrelated to the source content, thus containing semantically unrelated words and spurious word correspondence. In this paper, we propose a regularization approach for the sequence-to-sequence model and make use of what the model has learned to regularize the learning objective to alleviate the effect of the problem. In addition, we propose a practical human evaluation method to address the problem that the existing automatic evaluation method does not evaluate the semantic consistency with the source content properly. Experimental results demonstrate the effectiveness of the proposed approach, which outperforms almost all the existing models. Especially, the proposed approach improves the semantic consistency by 4\% in terms of human evaluation.
Query and Output: Generating Words by Querying Distributed Word Representations for Paraphrase Generation
Mar 30, 2018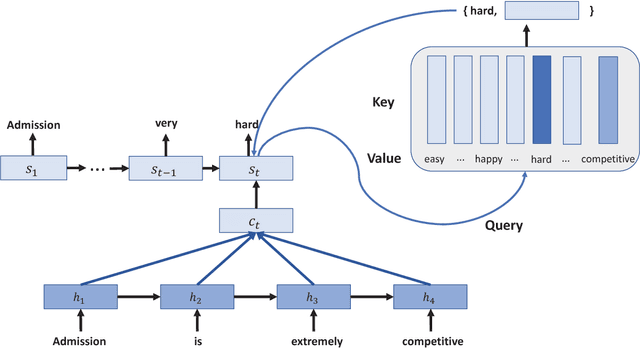

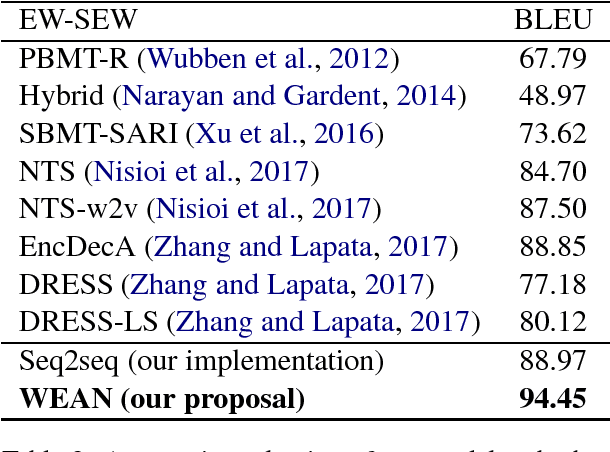
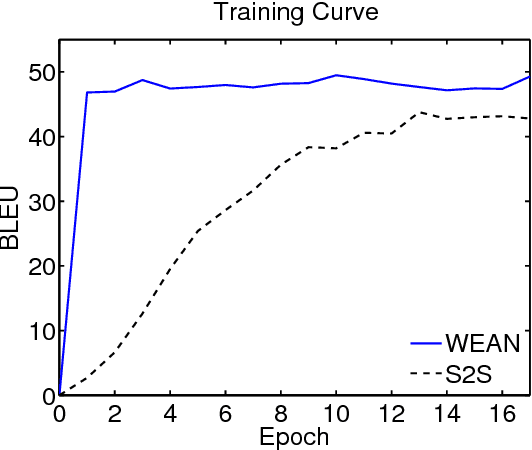
Most recent approaches use the sequence-to-sequence model for paraphrase generation. The existing sequence-to-sequence model tends to memorize the words and the patterns in the training dataset instead of learning the meaning of the words. Therefore, the generated sentences are often grammatically correct but semantically improper. In this work, we introduce a novel model based on the encoder-decoder framework, called Word Embedding Attention Network (WEAN). Our proposed model generates the words by querying distributed word representations (i.e. neural word embeddings), hoping to capturing the meaning of the according words. Following previous work, we evaluate our model on two paraphrase-oriented tasks, namely text simplification and short text abstractive summarization. Experimental results show that our model outperforms the sequence-to-sequence baseline by the BLEU score of 6.3 and 5.5 on two English text simplification datasets, and the ROUGE-2 F1 score of 5.7 on a Chinese summarization dataset. Moreover, our model achieves state-of-the-art performances on these three benchmark datasets.
Structure Regularized Neural Network for Entity Relation Classification for Chinese Literature Text
Mar 15, 2018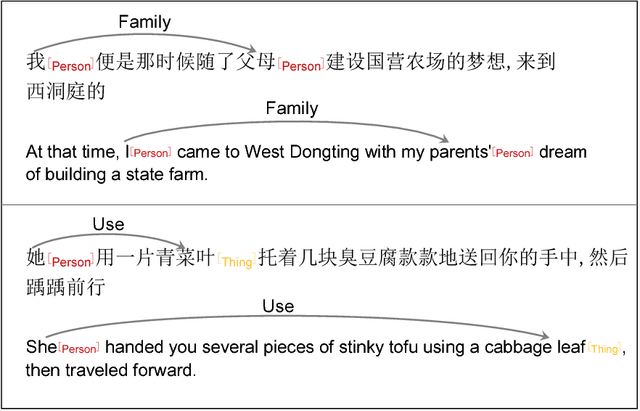

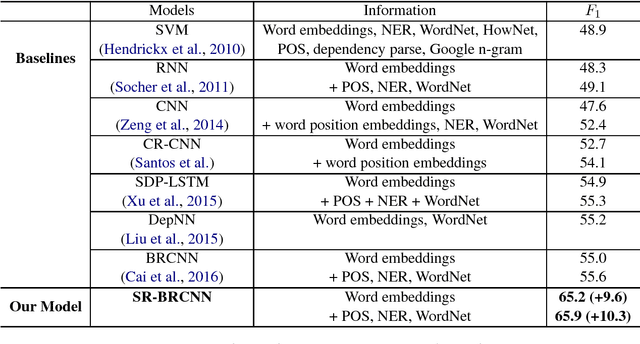
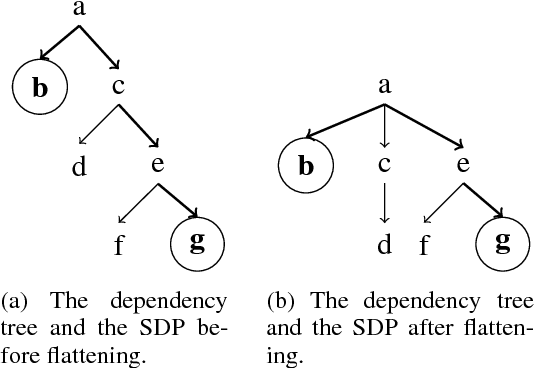
Relation classification is an important semantic processing task in the field of natural language processing. In this paper, we propose the task of relation classification for Chinese literature text. A new dataset of Chinese literature text is constructed to facilitate the study in this task. We present a novel model, named Structure Regularized Bidirectional Recurrent Convolutional Neural Network (SR-BRCNN), to identify the relation between entities. The proposed model learns relation representations along the shortest dependency path (SDP) extracted from the structure regularized dependency tree, which has the benefits of reducing the complexity of the whole model. Experimental results show that the proposed method significantly improves the F1 score by 10.3, and outperforms the state-of-the-art approaches on Chinese literature text.