 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Token Entropy Regularization for Multi-modal Antenna Affiliation Identification
Jan 29, 2026Accurate antenna affiliation identification is crucial for optimizing and maintaining communication networks. Current practice, however, relies on the cumbersome and error-prone process of manual tower inspections. We propose a novel paradigm shift that fuses video footage of base stations, antenna geometric features, and Physical Cell Identity (PCI) signals, transforming antenna affiliation identification into multi-modal classification and matching tasks. Publicly available pretrained transformers struggle with this unique task due to a lack of analogous data in the communications domain, which hampers cross-modal alignment. To address this, we introduce a dedicated training framework that aligns antenna images with corresponding PCI signals. To tackle the representation alignment challenge, we propose a novel Token Entropy Regularization module in the pretraining stage. Our experiments demonstrate that TER accelerates convergence and yields significant performance gains. Further analysis reveals that the entropy of the first token is modality-dependent. Code will be made available upon publication.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
SpanGNN: Towards Memory-Efficient Graph Neural Networks via Spanning Subgraph Training
Jun 07, 2024



Graph Neural Networks (GNNs) have superior capability in learning graph data. Full-graph GNN training generally has high accuracy, however, it suffers from large peak memory usage and encounters the Out-of-Memory problem when handling large graphs. To address this memory problem, a popular solution is mini-batch GNN training. However, mini-batch GNN training increases the training variance and sacrifices the model accuracy. In this paper, we propose a new memory-efficient GNN training method using spanning subgraph, called SpanGNN. SpanGNN trains GNN models over a sequence of spanning subgraphs, which are constructed from empty structure. To overcome the excessive peak memory consumption problem, SpanGNN selects a set of edges from the original graph to incrementally update the spanning subgraph between every epoch. To ensure the model accuracy, we introduce two types of edge sampling strategies (i.e., variance-reduced and noise-reduced), and help SpanGNN select high-quality edges for the GNN learning. We conduct experiments with SpanGNN on widely used datasets, demonstrating SpanGNN's advantages in the model performance and low peak memory usage.
Optimal Status Updates for Minimizing Age of Correlated Information in IoT Networks with Energy Harvesting Sensors
Oct 30, 2023Many real-time applications of the Internet of Things (IoT) need to deal with correlated information generated by multiple sensors. The design of efficient status update strategies that minimize the Age of Correlated Information (AoCI) is a key factor. In this paper, we consider an IoT network consisting of sensors equipped with the energy harvesting (EH) capability. We optimize the average AoCI at the data fusion center (DFC) by appropriately managing the energy harvested by sensors, whose true battery states are unobservable during the decision-making process. Particularly, we first formulate the dynamic status update procedure as a partially observable Markov decision process (POMDP), where the environmental dynamics are unknown to the DFC. In order to address the challenges arising from the causality of energy usage, unknown environmental dynamics, unobservability of sensors'true battery states, and large-scale discrete action space, we devise a deep reinforcement learning (DRL)-based dynamic status update algorithm. The algorithm leverages the advantages of the soft actor-critic and long short-term memory techniques. Meanwhile, it incorporates our proposed action decomposition and mapping mechanism. Extensive simulations are conducted to validate the effectiveness of our proposed algorithm by comparing it with available DRL algorithms for POMDPs.
Affinity-aware Compression and Expansion Network for Human Parsing
Aug 24, 2020
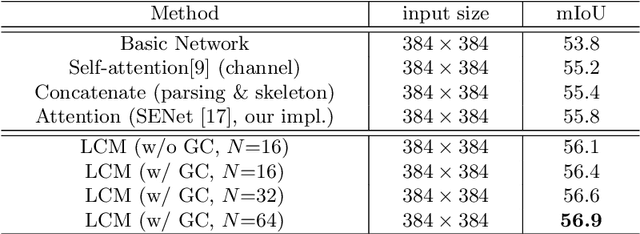
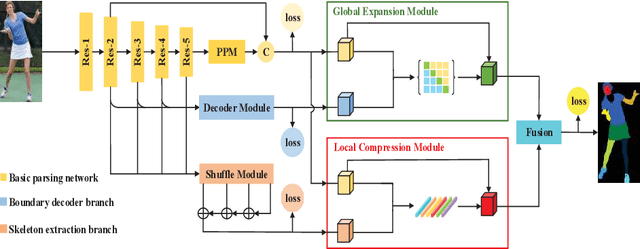
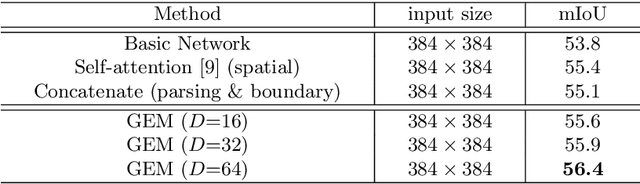
As a fine-grained segmentation task, human parsing is still faced with two challenges: inter-part indistinction and intra-part inconsistency, due to the ambiguous definitions and confusing relationships between similar human parts. To tackle these two problems, this paper proposes a novel \textit{Affinity-aware Compression and Expansion} Network (ACENet), which mainly consists of two modules: Local Compression Module (LCM) and Global Expansion Module (GEM). Specifically, LCM compresses parts-correlation information through structural skeleton points, obtained from an extra skeleton branch. It can decrease the inter-part interference, and strengthen structural relationships between ambiguous parts. Furthermore, GEM expands semantic information of each part into a complete piece by incorporating the spatial affinity with boundary guidance, which can effectively enhance the semantic consistency of intra-part as well. ACENet achieves new state-of-the-art performance on the challenging LIP and Pascal-Person-Part datasets. In particular, 58.1% mean IoU is achieved on the LIP benchmark.